
NVIDIA julkisti syyskuun alussa GeForce RTX 30 -sarjan näytönohjaimet, joiden grafiikkapiirit perustuvat uuteen Ampere-arkkitehtuuriin. Käymme tässä artikkelissa läpi arkkitehtuurin ominaisuudet sekä tutustumme GA102-grafiikkapiiriin ja GDDR6X-muisteihin, joita käytetään sekä GeForce RTX 3080- että RTX 3090 -malleissa. Myöhemmin lokakuussa myyntiin saapuva GeForce RTX 3070 käyttää pienempää GA104-grafiikkapiiriä ja GDDR6-muisteja.
Ampere-arkkitehtuuri
NVIDIA on jakanut Ampere-arkkitehtuurin uudistukset viiteen pääelementtiin: uuteen Streaming Multiprocessor- eli SM-yksikköön, toisen sukupolven Ray Tracing- eli RT-ytimeen, kolmannen sukupolven tensoriytimeen, GDDR6X-muisteihin ja uudelleensuunniteltuun jäähdytysratkaisuun. GeForce-pelinäytönohjaimissa käytettävät grafiikkapiirit valmistetaan Samsungin NVIDIAlle kustomoimalla 8 nanometrin valmistusprosessilla, joka perustuu yhtiön 10 nanometrin prosessiin.
GA102-grafiikkapiiri
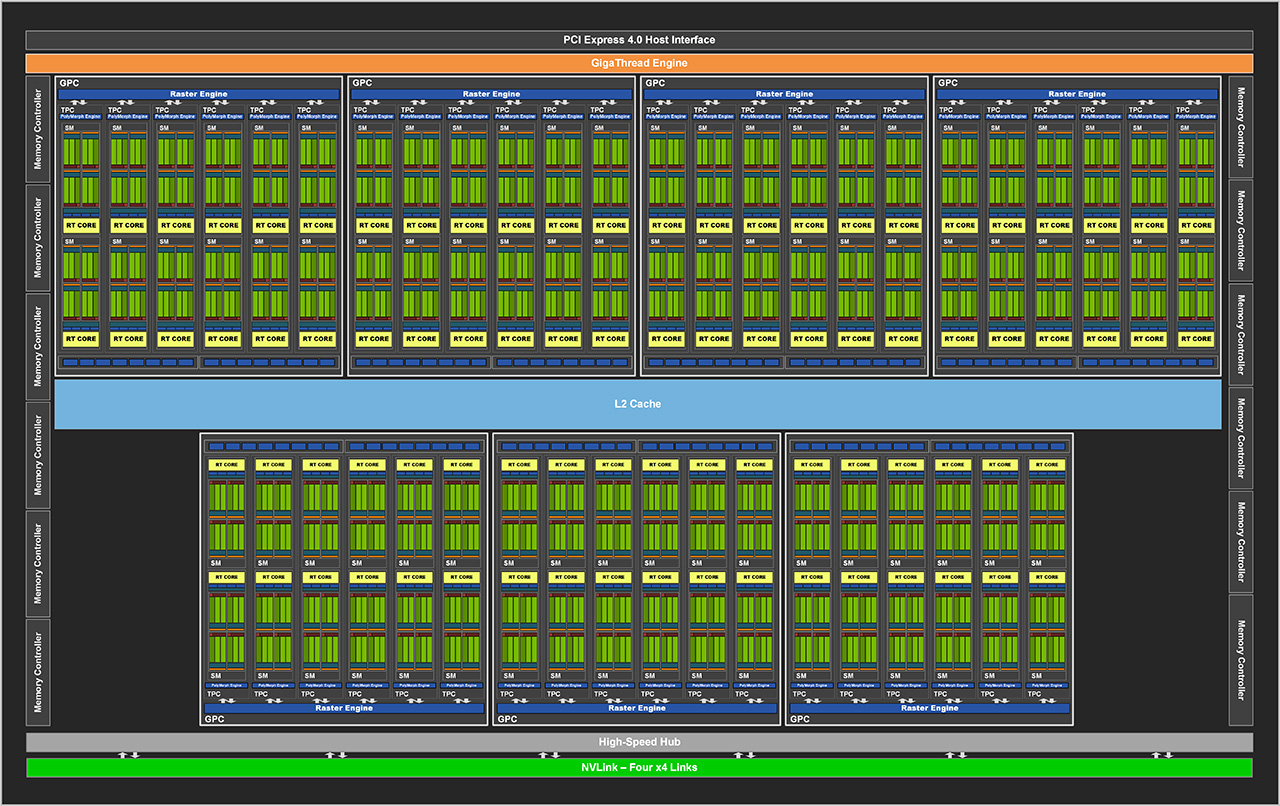
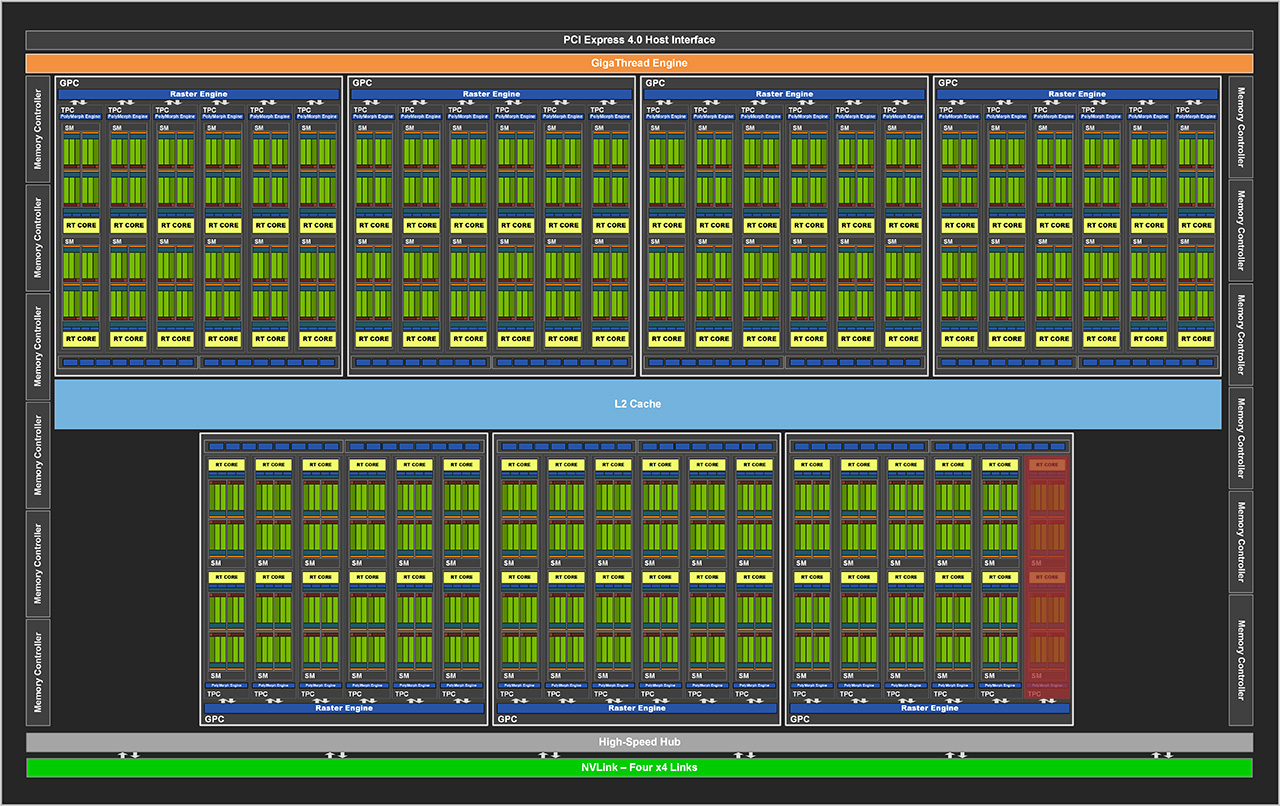
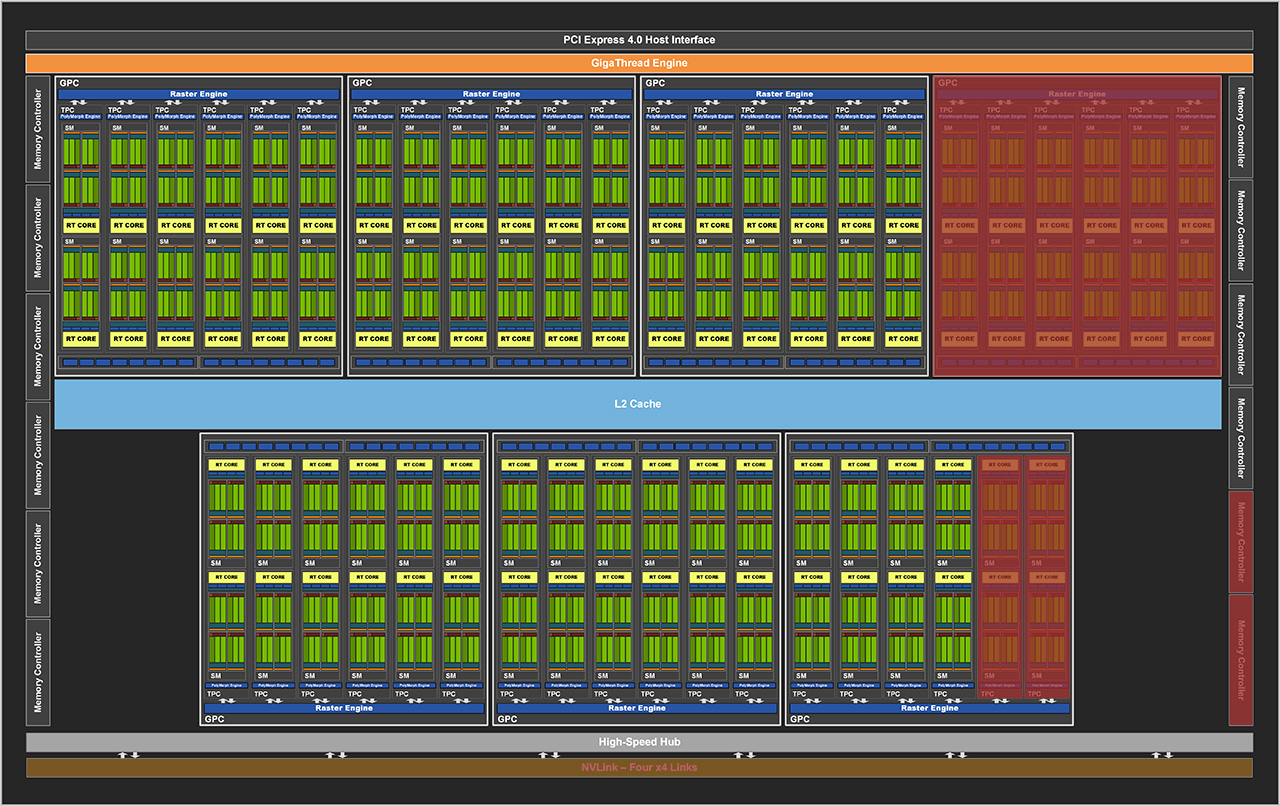
GeForce RTX 3080- ja 3090-näytönohjaimissa käytössä oleva GA102-grafiikkapiiri rakentuu yhteensä 28 miljardista transistorista. Se sisältää tehtäviä jakavan GigaThread Enginen, PCI Express 4.0 x16 -linkin ja yhteensä 7 GPC-yksikköä (Graphics Processing Cluster), joista kussakin on kuusi TPC-yksikköä (Texture Processing Cluster), jotka puolestaan sisältävät kukin kaksi SM-yksikköä (Streaming Multiprocessor).
Piirissä on jaettu kuuden megatavun L2-välimuisti, neljä NVLink x4 -linkkiä sekä yhteensä kaksitoista 32-bittistä GDDR6X-muistiohjainta, joista kukin ohjaa kahta 16-bittistä muistikanavaa. Aiemmin L2-välimuistin yhteydessä sijainneet ROP-yksiköt (Render OutPut unit) on siirretty nyt osaksi GPC-yksiköitä.

GeForce RTX 3090 -huippumallissa on käytössä kaikki seitsemän GPC-yksikköä, mutta yksi TPC-yksikkö ja sen myötä kaksi SM-yksikköä on poistettu käytöstä. RTX 3080 -mallissa on poistettu käytöstä yksi kokonainen GPC-yksikkö, kaksi TPC-yksikköä, kaksi 32-bittistä muistiohjainta sekä NVLink-linkit.
GeForce RTX 3070 -näytönohjaimen käyttämän GA104-grafiikkapiirin tarkat tekniset ominaisuudet ovat vielä osittain hämärän peitossa. NVIDIA ei ole julkaissut piiristä vielä blokkidiagrammia, eikä GPC-yksiköiden ja siten ROP-yksiköiden määrää voida päätellä muiden yksiköiden määrästä, sillä NVIDIA on käyttänyt ennenkin saman arkkitehtuurin sisällä erilaisia GPC-konfiguraatioita. Löydät näytönohjainten tarkemmat tiedossa olevat tekniset yksityiskohdat yllä olevasta taulukosta.
Streaming Multiprocessor -yksikkö

NVIDIAn grafiikkapiirien peruspilari eli SM-yksikkö rakentui edellisessä Turing-sukupolvessa neljästä SIMD-yksiköstä (Single Instruction, Multiple Data), joista kussakin on oma Warp Scheduler -vuorontaja ja tehtävien lähetysyksikkö (Dispatch), jotka kukin kykenevät 32 säikeeseen kellojaksoa kohti. Ne jakavat tehtävät kahdelle tensoriyksikölle sekä 16 FP32-tarkkuuden (Floating Point, liukuluku) CUDA-ytimelle ja 16 INT32-tarkkuuden (Integer, kokonaisluku) ytimelle. Lisäksi SM-yksikköön kuuluu yksi RT-ydin, kuten aiemminkin.
Ampere-arkkitehtuurissa SIMD-yksiköiden perusrakenne on pysynyt identtisenä, mutta toisen datapolun INT32-yksiköt on päivitetty CUDA-ytimiksi, jotka hallitsevat sekä FP32- että INT32-tarkkuuden laskut. Tämän muutoksen myötä myös SM-yksiköiden laskennallinen CUDA-ydinten määrä kaksinkertaistui, vaikka itse laskentayksiköiden määrä ei ole muuttunut. Lisäksi NVIDIA on kasvattanut L1-välimuistin kaistan kaksinkertaiseksi, lisännyt sen määrää yhteensä 33 % ja kasvattanut välimuistiosioiden koon kaksinkertaiseksi.
Tensoriydin
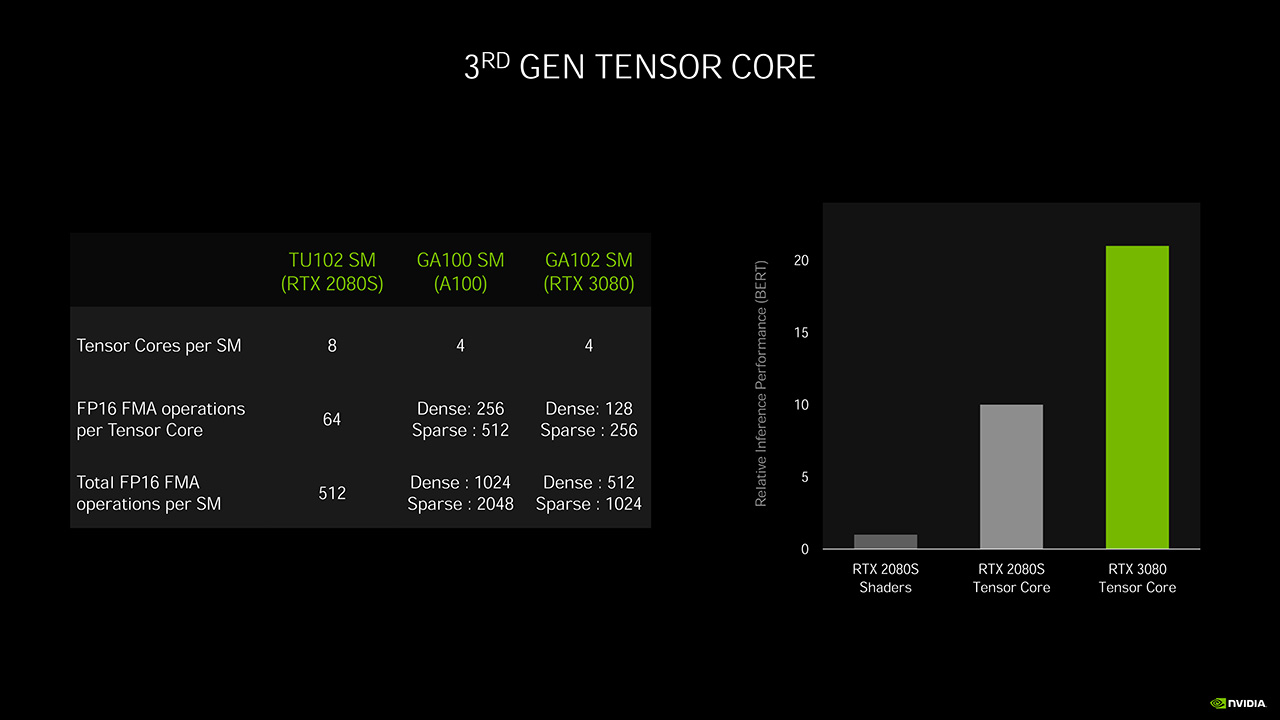
GA102:n SIMD-yksikköjen rinnalla on nyt vain yksi tensoriydin, mutta se on tehokkaampi kuin aiemmat kaksi ydintä. Siinä missä Turing-arkkitehtuurin tensoriydin kykeni 64 FP16-tarkkuuden FMA-operaatioon (Fused Multiply-Add) kellojaksossa, yltää GA102:n tensoriydin tehtävästä riippuen joko 128 FP16 FMA -operaatioon (Dense-matriisit) tai 256 FP16 FMA -operaatioon (Sparse-matriisit) per kellojakso.
RT-ydin
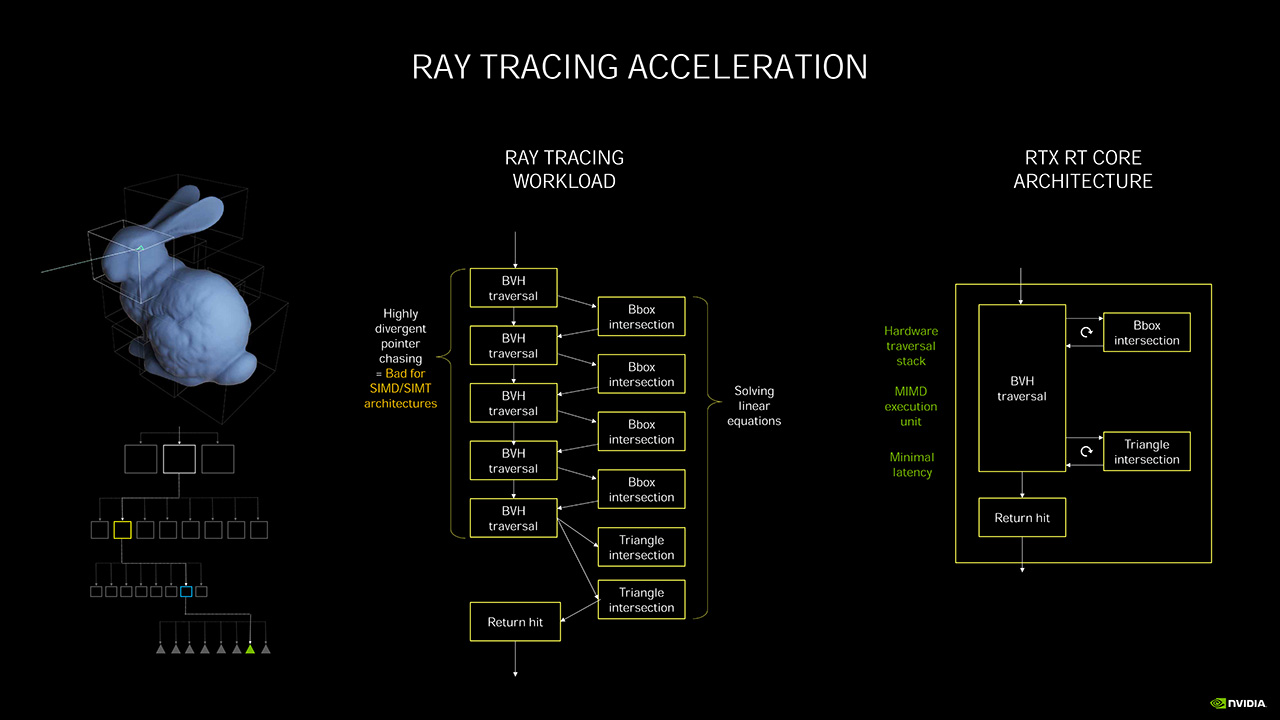
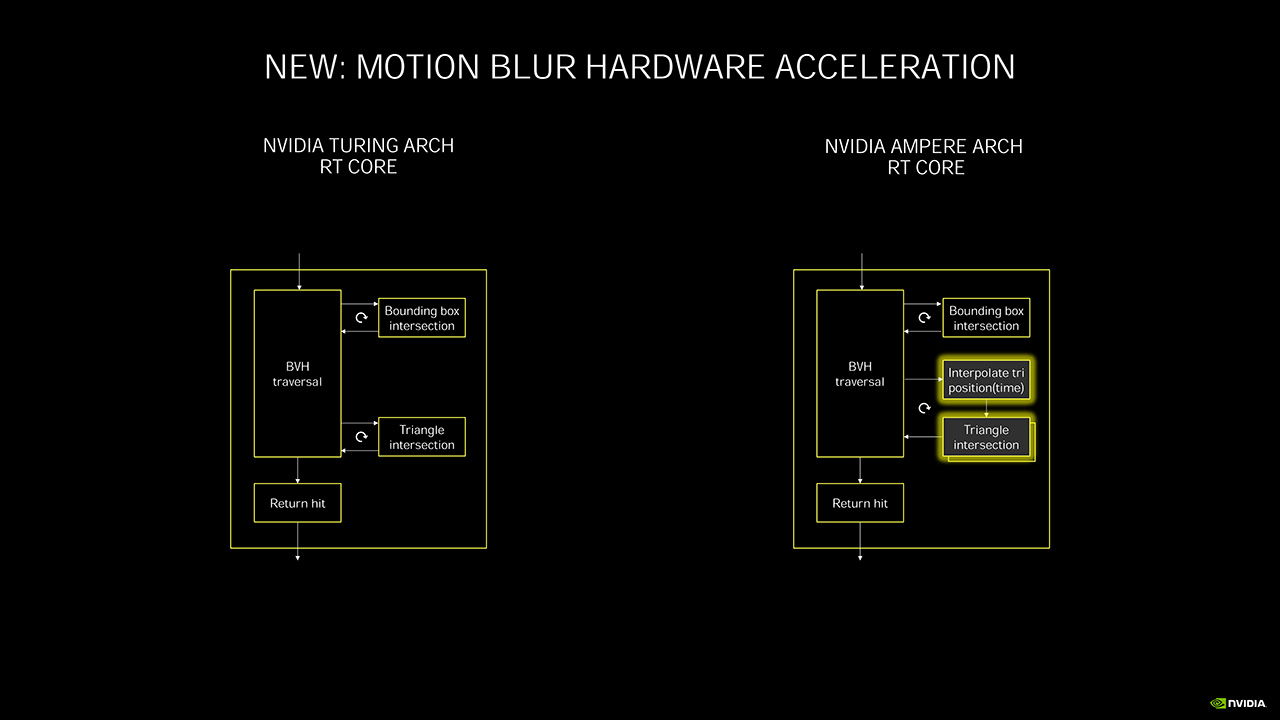
Toisen sukupolven RT- eli säteenseurantaytimet sisältävät ensimmäisen sukupolven tavoin MIMD-rakenteeseen (Multiple Instruction, Multiple Data) perustuvan BVH Traversal -yksikön (Bounding Volume Hierarchy), Bounding Box -törmäystarkistimen ja kolmio-törmäystarkistimen. Uutuutena siihen on lisätty uusi interpolointiyksikkö, joka kykenee laskemaan kolmion muuttuvan sijainnin ajan funktiona, mitä voidaan hyödyntää motion blur -efektien toteuttamisessa nopeuttaen BVH Traversal -toimintoja parhaimmillaan kahdeksankertaiseksi, kun osumien edelliset sijainnit ovat jo tiedossa. Myös kolmiotörmäystarkistuksen nopeutta on kasvatettu kaksinkertaiseksi aiempaan nähden.
GDDR6X-muistit
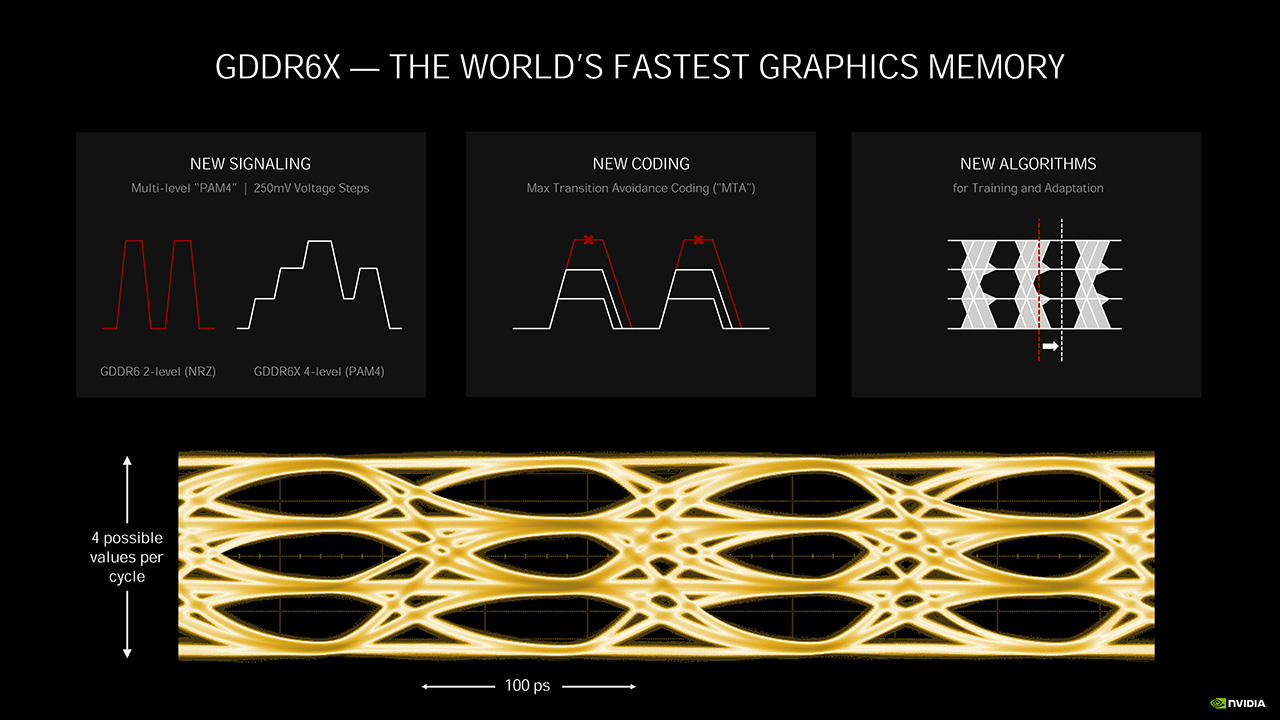
GDDR6X-muistit ovat NVIDIAn ja Micronin yhteistyön hedelmä ja niiden merkittävin muutos on NRZ-signaloinnin (binäärinen Non-Return to Zero) vaihto PAM4-signalointiin (4-tasoinen Pulse Amplitude Modulation). Tämä mahdollistaa tiedonsiirron neljä kertaa kellojaksoa kohti, kun NRZ-signaloinnilla voidaan siirtää dataa kaksi kertaa kellojaksossa. Uusi Max Transition Avoidance Coding eli MTA-teknologia varmistaa, että signaalin jännitetasot voivat hypätä korkeintaan kaksi jännitetasoa ylös- tai alaspäin kerrallaan. Tällä on pyritty pitämään muistisignaalin ns. ”datasilmä” mahdollisimman laajana. Muistiohjaimet myös ”opettavat” itseään aika-ajoin uudelleen varmistaakseen, jotta data luetaan oikeassa kohtaa signaalia. RTX 3080 -mallissa GDDR6X-muistit toimivat 19 Gbps:n ja RTX 3090 -mallissa 19,5 Gbps:n nopeudella.
Energiatehokkuus
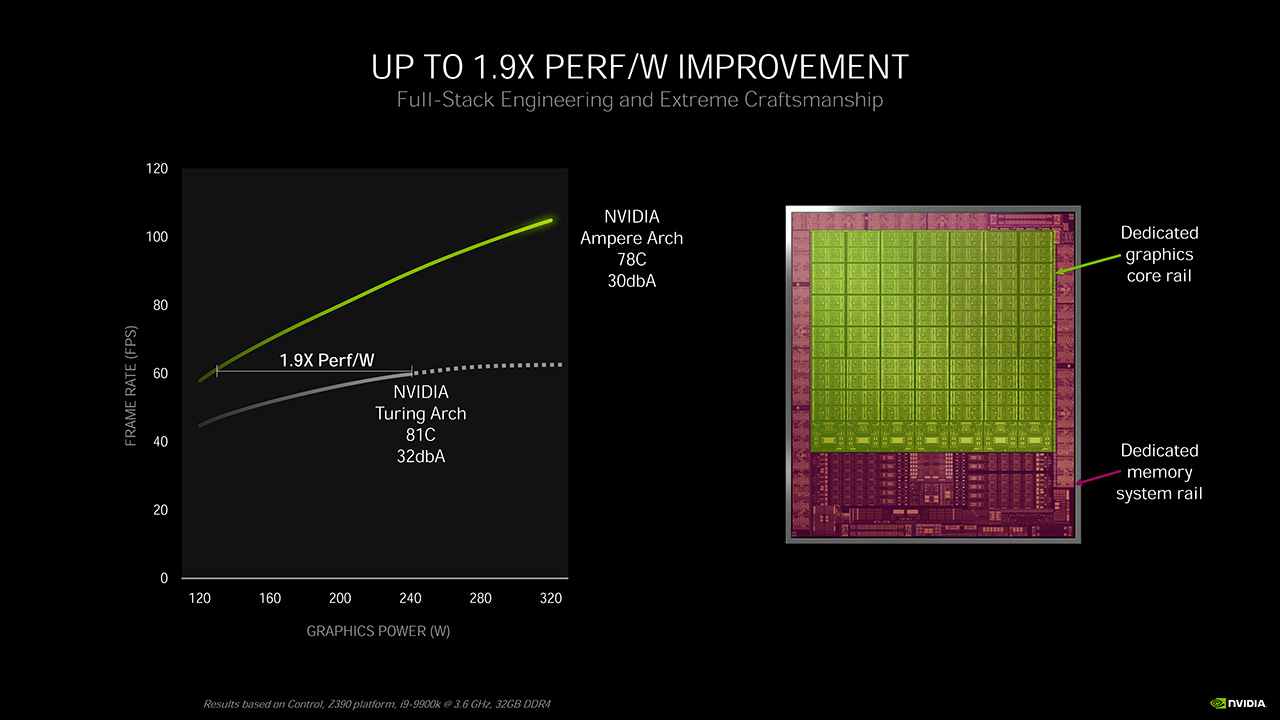
NVIDIAn mukaan kaikki arkkitehtuurin ja valmistusprosessin muutokset sekä itse grafiikkaydinten ja muun sirun jännitelinjojen erottelu toisistaan nostavat Ampere-arkkitehtuurin energiatehokkuuden parhaimmillaan 1,9-kertaiseksi Turingiin verrattuna. Oletettavasti vertailukohtina ovat RTX 3080 ja RTX 2080 Super, joita NVIDIA on käyttänyt muissakin vertailuissaan. Käytännössä parannus ei kuitenkaan tule olemaan 90 %, sillä se on mitattu hidastamalla Amperen suorituskykyä samalle tasolle Turingin kanssa. NVIDIAn suorituskykygraafien perusteella Control-pelissä RTX 3080:n suorituskyky wattia kohden tulisi olemaan todellisuudessa noin 30 % parempi, kuin RTX 2080 Superilla.
Testiartikkeli NVIDIAn omasta GeForce RTX 3080 Founders Edition -näytönohjaimesta julkaistaan 16. syyskuuta. Näytönohjainvalmistajien eli Asuksen, Gigabyten ja MSI:n GeForce RTX 3080 -mallien testi julkaistaan 17. syyskuuta. GeForce RTX 3090 -näytönohjaimien testitulokset saa julkaista 24. syyskuuta. GeForce RTX 3070 -näytönohjaimet saapuvat lokakuussa. NVIDIA ei vielä toistaiseksi julkistanut GeForce RTX 3060- ja 3050-malleja.
Sen voxelirakenteen päälle voidaan myös rakentaa optimoitu rakenne, jonka avulla voidaan hypätä tyhjien alueiden tarkastelut. Mut ei tästä kannata ainakaan tässä threadissä vääntää.
Jos luet sen mun alkuperäisen kommentin niin yritin nimenomaan sanoa, että vaikka minecraft näyttää yksinkertaiselta ja helposti optimoitavalta niin ei se ole yhtään sen helpompi peli optimoida kuin jokin muu peli dxr apin päälle. Loppu on turhaa spekulointia siitä miten minecraft tyyppisen voxeleista koostuvan pelin voisi optimoida paremmin kuin mitä dxr api sallii.
Ihan yksinkertaisin ajatus asiasta voisi olla se, että jos rauta sallisi niiden bounding boxien käytön voxeleina niin voisi löytyä jotain mielenkiintoista optimoitavaa. Ei tarvisi niitä kolmioita kuin npc/pelaajan hahmoille.
Kuten hkultala tossa jo mainitsi, niin ne bounding box rakenteet tulee olemaan käytännössä samankokoiset tiesi niitä rakentava taho mitään minecraftin erikoispiirteitä vai ei. Ihmismieli kuvittelee että kun kyseessä on vaan laatikoita lopullisella tasolla, niin homma toimisi jotenkin eritavalla, vaikka ne kaikki bounding boxit on joka tapauksessa laatikoita.