
Spectre ja Meltdown ovat olleet viimepäivien kuumin puheenaihe IT-maailmassa. Suurimman osan huomiosta on saanut Intel, vaikka haavoittuvuudet koskevat myös muita valmistajia.
Spectre- ja Meltdown-haavoittuvuuksien paikkaamisen tiedetään vaikuttavan tietokoneiden suorituskykyyn. Se, miten paljon paikat suorituskykyä laskevat, riippuu ennen kaikkea tietokoneella tehtävistä tehtävistä. Suurimman suorituskyvyn laskut tapahtuvatkin lähinnä datakeskuksissa, joissa palvelimiin kohdistuu raskasta I/O-rasitusta.
Intel on julkaissut omat suorituskykytestinsä koskien kotikäyttäjien tietokoneita Windows-alustoilla. Testit on ajettu yhtiön kolmen viimeisen sukupolven prosessoreilla käyttäen erilaisia synteettisiä testejä. 8. sukupolven Coffee Lake -prosessoreilla ja 8. ja 7. sukupolven Kaby Lake -mobiiliprosessoreilla testit on suoritettu Windows 10 -käyttöjärjestelmällä ja 6. sukupolven Skylake-prosessoreilla sekä Windows 10:llä käyttäen SSD-asemaa että Windows 7:llä käyttäen SSD-asemaa ja kiintolevyä. Testit ajettu SYSmark 2014 SE-, PCMark 10- 3DMark Sky Diver- ja WebXPRT 2015 -ohjelmilla.
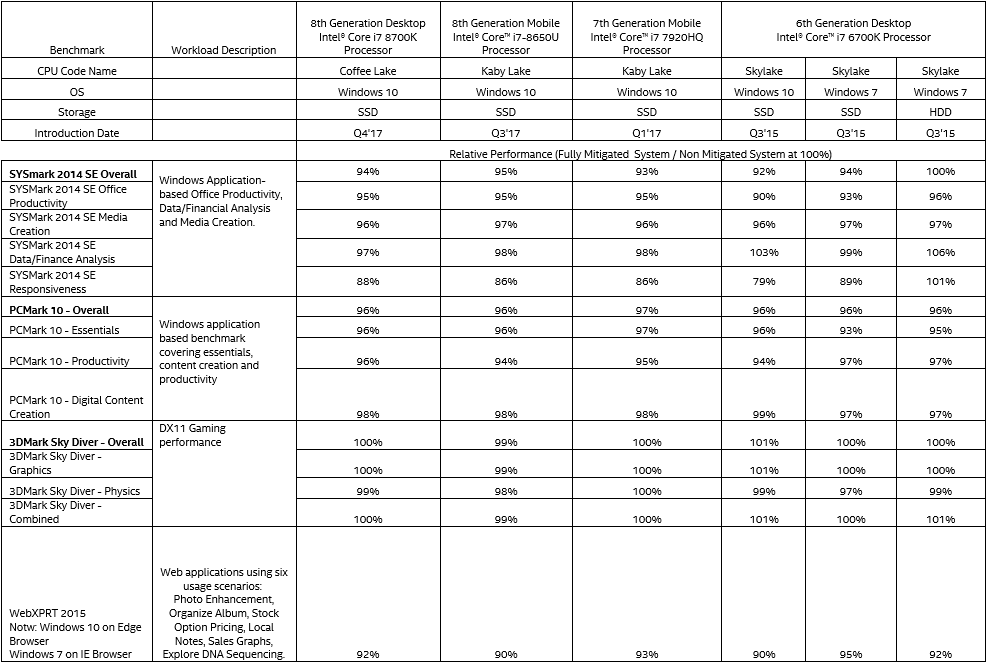
Intelin omien testien mukaan suorituskyky on laskenut lähes jokaisessa testissä, mutta muutama poikkeuskin löytyy. Suorituskyvyn kerrotaan jopa parantuneen kiintolevyllä ja Windows 7:llä varustetulla Skylake-kokoonpanolla SYSMark 2014 SE:n Data/Finance Analysis- ja Responsiveness-testeissä sekä samalla prosessorilla, SSD-asemalla ja Windows 10 -käyttöjärjestemällä SYSMark 2014 SE:n Data/Finance Analysis -testissä, 3DMark Sky Diverin kokonaistuloksessa, grafikka-testissä ja grafiikka- ja fysiikkatestit yhdistävässä Combined-testissä.
Suurin negatiivinen vaikutus päivityksistä on saatu SYSMark 2014 SE:n Responsiveness-testissä Skylake-prosessorilla Windows 10 -alustalla ja Kaby Lake -mobiiliprosessoreilla. Skylaken tapauksessa suorituskyky oli vaivaiset 79 % alkuperäisestä, kun Kaby Lakejen suorituskyky riitti niin ikään erittäin heikkoon 86 %:iin alkuperäisestä. Myös Coffee Lake -kokoonpanoin ja Windows 7:lla ja SSD-asemalla varustetun Skylake-kokoonpanon tulokset laskivat alle 90 %:iin päivittämättömien verrokkien tuloksista samassa testissä.
Löydät kaikki suorituskykylukemat uutisen kuvasta, jonka voi avata täyteen kokoon klikkaamalla.
Lähde: Intel
Ei näykään, enkä ole missään väittänytkään, että näkyisi.
(Tässä puhuttiin ihan normaalisti, eikä spekulatiivisesti suoritetuista käskyistä.)
Ei niin. Enkä ole niin väittänytkään.
Hyvä, alat pikku hiljaa oppia jotain.
Intelin prosessorit kunnioittavat muistinsuojausta. Muistinsuojauksen speksit sanoo, että yritys lukea laittomasta osoitteesta johtaa siihen, että käsky nostaa poikkeuksen, eikä koskaan tallenna tulostaan arkkitehtuurilliseen tulosrekisteriin. Tämä pitää täysin paikkaansa intelin prosessoreilla.
Mutta nimenomaan tämä on ongelma, näin toimivat prosessorit ovat "rikki". Eli ylemmän tason koodi voi lukea alemman tason muistia ja ko. muisti saadaan näkymään ylemmän tason koodissa. Meltdown, prosessori on rikki muistinsuojauksen osalta. Ihan sama vaikka tottakai tarkoitus on ollut pitää muisti suojattuna, kyseinen toteutus ei vaan toimikaan. Hätäratkaisuna näille prosessoreille sitten on nyt väliaikaisesti(suorituskyvyn kustannuksella) eriytetty käyttöjärjestelmissä kernelin muisti kokonaan ylemmän tason ohjelmista ja generoitu kernelin osoitteet sattumanvaraisiksi mutta se ei poista sitä tosiasiaa että Meltdown-prosessorit eivät ole edes teoriassa turvallisia, vuotaminen on vain tehty vähän haastavammaksi. Kaikista korkean turvallisuuden vaatimista palvelimista pyritään aivan varmasti hävittämään Meltdown-haavoittuvat prossut niin nopeasti kuin suinkin – nyt vain väliaikaispaikkauksilla odotetaan että Intel saa sellaisia tehtyä.
Branch target bufferissahan on myös ongelmana että nykyään se toimii myös instruction cachena, eli joissain tapauksissa hyppykäskyn suorittamat käskytkin löytyvät BTB:stä. Nyt kun prosessori on flushannut TLB:nsä itse cachen data on kuitenkin tallessa ja kun spectrellä hyökätään BTB:hen sieltä löytyvät käskyt lukevat datan suoraan cachesta -> jos BTB:tä ei saada flushattua seuraava homma on kirjoittaa koko cachet yli.
Tuota kutsutaan nimellä "branch folding".
Ja se oli lähinnä 1980- ja 1990-lukujen RISC-prossujen temppu eikä juuri käytetä enää superskalaarisissa prosessoreissa:
Yksinkertaisissa In-order-prosessoreissa fetchin viivästyminen kellojaksolla tarkoitti sitä, että koko prosessorin liukuhihna hukkasi aina kellojakson. Tämän takia branch foldingia tarvittiin 1980-1990-luvuilla.
Nykyaikaisissa Out-Of-Order-prosesoreissa taas prosesorin etupää menee kaukana suorituksen edellä, ja välissä olevissa puskureissa riittää tyypillisesti hyvin käskyjä suoritettavaksi, se että fetch ei välillä tee mitään kellojakson ajan ei yleensä vielä yhtään hidasta suoritusvaihetta.
Ja jotta säästettäisiin edes kokonainen kellojakso nykyaikaisilla 4 käskyä fetchaavilla prosessoreilla, siellä BTBssä pitäisi sitten olla 4 käskyä, ei vain 1 käsky.
Ja Nykyään tähän on modernimpia ja parempiakin ratkaiuja:
Joissakin nykyaikaisissa prosessoreissa (ainakin Zen) tässä on menty vielä pidemmälle, ja haarautumisenennutimen ja fetchinkin väliin on lisätty puskurit. Haarautumisenennustin laittaa jonoon osoitteita joista fetch hakee käskyjä ja käskynhakuyksikkö hakee näistä osoitteista käskyjä, kun ehtii.
(lisäksi vielä nykyään myös decoden ja renamenkin välissä on vielä puskurit, ja superskalaarisisssa in-order-prosessoreissakin on tyypillisesti jonkinlainen käskypuskuri decoden ja suorituksen välissä, joten niissäkään se branch folding ei säästäisi keskimäärin ainakaan läheskään täyttä kellojaksoa)
Nykyaikaisilla prosssoreilla TLB tagataan, ei flushata context switchin yhteydessä (SMTn toteuttaminen vaatii tätä).
TLBn tagibiteistä nähdään, että nämä entryt ei ole tällä hetkellä/tälle käskylle voimassa, eikä niitä käytetä. Sitten myöhemmin kun prosessorin tila on jälleen vaihtunut, ne entryt on taas voimassa, eikä niitä tarvi uudestaan ladata sivutauluista asti muistista.
Spectren 2.variantin ongelma ei ole BTBssä oleva käsky vaan BTBssä oleva käskyosoite. Siellä on osoite niihin käskyihin, jonka hyökkääjä haluaa suoritettavan. Ja ne käskyt on kernelin luettavissa, koska
A) kerneliin on mäpätty koko user-prosssin muistialue samaan paikkaan. (jos ei olisi, kaikki IO kernel- ja user-tilojen välillä olisi paljon hankalampaa ja hitaampaa).
B) hyökkääjä voi hyväksikäyttää/väärinkäyttää jo kernelin omalla muistialueella olevaa koodia, kun vain tietää sen osoitteen jotenkin.
Ja ratkaisuksi ei tarvi flushata mitään, riittää se, että myös BTB tagataan. Että BTB ei toimisi sellaisten ennustusten mukaan, jotka on "opetettu" eri tilassa kuin missä prosessori nyt on.
AMDllä tilanne spectren 2.variantin suhteen on käsittääkseni se, että kernel-tilassa ei koskaan spekulatiivisesti suoriteta koodia muistista, joka on on määritelty user-tilan muistiksi. Tämäkään ei kuitenkaan suojaa siltä, että kernelin omaan muistiin on saatu se hyökkääjän koodi jotenkin ujutettua, ja hyökkäjä tietää sen osoitteen.
Miksi TLB flushattaisiin normaalisti toimivassa prosessorissa? TLB flush on tällähetkellä käytetty paikka Meltdownista kärsiville prosessoreille jotta kernelidatan sijainti saadaan piilotettua.
TLB taggaus on virtualisointia varten kun pitää käyttää useampia TLB-tauluja, Intelhän nyt hyödyntää em. ominaisuutta TLB ongelmansa kanssa eli ei tarvitse täysiä TLB flusheja kun taggaillaan eri taulut kernelille ja user-modelle – jos prosessori ei olisi "rikki" sitäkään kikkailua ei tarvittaisi.
SINÄHÄN tässä alunperin TLBn flushauksesta aloit puhumaan, en minä.
Kontrollirekisterillä CR3 säädellään sitä, mistä prosessorin sivutaulut löytyy.
Jos CR3n arvo muuttuu, myös virtuaalimuistimappaus muuttuu.
Jotta prosessori toimii oikein kun CR3sta muutetaan, TLB pitää joko tagata CR3n arvolla TAI TLB pitää flushata kun CR3n arvo muuttuu.
Nyt menee syy ja seuraus pahasti sekaisin.
TLBn flushaaminen ei auttaisi yhtään mitään, jos itse sivutauluihin ei kosketa, koska ne muistissa olevat SIVUTAULUT määrittelee sen virtuaalimuistimappauksen. TLB on vain cache sen osoitemuunnoksen tekemiseksi nopeammin, ilman että tarvii jokaista muistiaccessia varten tehdä 4 ylimääräistä muistiaccessia niihin sivutauluihin.
Sekoitat nyt sen, mikä on itse korjaus ja mikä on siihen liittyvä lisäominaisuus/optimointi.
Ja se yleisin käyttötarkoitus/pakottavin syy TLBn tagaamiselle on SMT, prosessorilla voi olla yhtä aikaa ajossa monta eri prosessia. Molemmilla pitää olla omat TLB-entrynsä, koska näillä kahdella prosessilla voi olla(tai siis ON!) aivan erilaiset virtuaalimuistimappaukset
No nyt jos puhutaan x86:sta, väitit että context switchissä TLB tagataan tai flushataan. Ei tehdä kumpaakaan, TLB taggaus ei ole x86:ssa edes tuettu (virtualisoinnin ulkopuolella)kuin Intelin Sandy bridgestä eteenpäin eikä sitä ole missään käytetty kun olisi vain hidastanut toimintaa. X86 tarvitsee TLB flushin virtuaalimuistiavaruuden muutoksissa, Kerneli siis lähinnä poikkeustapauksissa ja user-mode prosessin vaihdossa. Muuten vain vaihdellaan toimintatilaa user-moden ja kernel-moden välillä ilman tarvetta TLB:n putsauksiin.
Intelin ongelma on tällähetkellä että spekulatiivinen koodinsuoritus ei välitä suojaustasoista mitään. Siksi TLB-cachen side-channel hyökkäyksellä saadaan luettua ylemmän tason koodilla alemman tason suojauksen alla olevaa koodia. TLB flush tyhjentää tuon osoitemuunnostaulun ja hyökkäys kuivuu kokoon sen osalta. Meltdown-paikkahan erottaa kernelin omaan muistiavaruuteensa mutta pakkohan se usermoden kuitenkin pitää tarvittava tieto mahdollistamaan kerneliin siirtyminen -> TLB flushataan vielä siiryttäessä kernelin puolelle.
SMT ei vaadi TLB:n tagaamista, eikä x86 mahdollista sitä muutenkaan, muistitauluissa ei ole threaditietoa ollenkaan. TLB ja cachet on prosessorissa jaettu threadien kesken, toki dynaamisesti mutta jaettu kuitenkin.
TLB-taggaus on ollut ainakin kymmenen vuotta x86:ssakin ihan puhtaasti virtualisoinnin takia, ajettaessa useampia kerneleitä TLB-joudutaan flushaamaan aina kernelin vaihdon yhteydessä jos mahdollisuutta ajaa useampaa virtuaalimuistimappausta yhtäaikaa ei ole. Normikäytössä taggaukselle ei ole ollut suorituskyvyn optimoinnin takia tarvetta.
Oikeammin, että suojaustarkistuksiin reagoidaan vasta retire-vaiheessa, eikä memory-vaiheessa.
Edelleenkään millään TLB-flushilla ei ole mitään väliä jos sivutauluista löytyy se data jota niistä ei pitäisi löytyä. TLB on vain välimuisti niille sivutauluille.
Jos niitä itse sivutauluissa olevia virtuaalimuistimappauksia ei muuteta, ne kernelin osoitteet kyllä lautautuu sinne TLBhen sieltä muistissa olevista sivutauluista, ja se flushaus on tehty täysin turhaan.
Ymmärrätkö edes, mikä ero on säikeellä ja prosessilla?
Kaikki SMT:tä tukevat CPUt kykynevät ajamaan montaa prosessia yhtä aikaa. Ei vain montaa säiettä.
Niillä prosesseilla voi olla eri virtuaalimuistimappaukset. Jolloin on pakko merkata, kumman prosessin muistimäppäyksistä on kyse.
Ja milläs se kernelisivudata latautuu sinne TLB:hen userpuolen softalla? No onhan se hyökkäys mahdollinen ehkä jollain tavalla ja kerran TLB pitää kuitenkin flushata niin se on sitten suorituskyvyn puolesta aivan sama ajaa kerneli omassa muistiavaruudessaan.
No vaihdetaan prosessi tilalle, ei muuta tilannetta virtuaalimuistimappauksen osalta. Jos virtuaalimuistitaulukoissa olisi prosessitieto tätä voitaisiin käyttää mutta x86:ssa ei ole. Eli cachet ja TLB:t vain yksinkertaisesti jaetaan prosessien välillä. Ja nähtävästi myös arkkitehtuureissa joissa ASID löytyy ei sitä käytetä tuossa tarkoituksessa, Intel skippaa yhden bitin dekoodauksen lukuvaiheessa, prosessitiedon dekoodaus tuossa vaiheessa olis ainakin magnitudin raskaampi operaatio
:facepalm:
Jälleen kerran on aivan perusasiat hukassa asiasta josta vänkää.
Sivutaulu-entry latautuu muistista TLBhen kun yrittää accessoida virtuaaliosoitetta, jonka osoitteenmuunnostietoihin tarvitaan sitä sivutaulua.
Ja ennen meltdown-workaroundia kaikki ne kernel-muistiosoitteet oli ihan näkyvissä sivutauluissa jotka oli user-tilassa käytössä. Niihin itse osoitteisiin ei vaan ollut luku- eikä kirjoitusoikeuksia.
Edelleenkään et ymmärrä mikä on syy, ja mikä on seuraus.
Koska perusymmärrys virtuaalimuistin toiminnassa on hukassa.
Ilmeisesti tarkoitat "virtuaalimuistitaulukoilla" sivutauluja.
Eikä sitä prosessi-id:tä tarvisi olla sivutauluissa. Voidaan tagata se sen mukaan, mikä oli CR3-rekisterin sekä CR4-rekisterin oleellisten bittien arvo sitä TLB-entryä muistista ladatessa.
:facepalm:
Niinkuin oikeasti.
Yritä nyt opetella edes perusasiat siitä, mikä on prosessi ja mikä säie, sen sijaan että luet hirveästi nippelitietoa ymmärtämättä sitä lukemaasi oikeasti.
:facepalm:
Ei sitä TLBtä voi vain jakaa merkkaamatta jonkinlaiseen kirjanpitoon, KUMMAN prosessin entrystä on kyse. Koska sama virtuaaliosoite tarkoittaa eri fyysistä osoitetta eri prosesseille.
jos toinen prosessi voisi käyttää toisen prosessin lataamaa TLB-entryä, sen tekemät luvut ja kirjoitukset menisivät väärään fyysiseen osoitteeseen.
Välimuistit sen sijaan kaikissa x86-prossuissa on tagattu fyysisillä osoitteilla eikä virtuaalisoitteilla, jolloin ne voidaan jakaa monen säikeen välillä ilman ylimääräistä kirjanpitoa.
Mutta: jos molemmat säikeet aina kuuluisivat samalle prosessille, niiden virtuaalimuistimappays OLISI SAMA, jolloin ne SAISIVAT jakaa sen TLBn ilman mitään ylimääräistä kirjanpitoa.
En kuitenkaan tiedä yhtään sellaista CPU:ta, joka tulisi tällaista rajoitettua "saman prosessin sisäistä" monisäikeistystä, koska se olisi sekä hyvin ongelmallinen softien yhteensopivuuden kannalta, että tarkoittaisi että sitä voisi käyttää paljon harvemmin.
Monet näyttikset sen sijaan saattavat voimia näin, niissä saattaa samassa ytimessä pystyä olemaan ajossa yhtä monta work grouppia joiden on pakko olla samaa kerneliä, samasta softasta yms. rajoituksia.
Tagataan mihin kun arkkitehtuurissa ei ole sille tilaa? Ja TLB cache on niin nopeuskriittinen paikka että vaikka ASID löytyisi TLB-entrystä sitä ei tuohon tarkoitukseen käytetä.
Eli siis kun se on jaettu tilanne on se että kummallakin prosessilla on omat TLB:nsä. Nopeammat TLB:t on jaettu yleensä staattisesti puoliksi ja vähemmän nopeuskriittiset dynaamisesti eli toinen prosessi voi saada suuremman osan käyttöönsä.
Siinä SMT:ssä on siis kaksi erillistä prosessoria jotka jakaa resursseja ja TLB ei kuulu näihin jaettuihin resursseihin, kumpikin TLB:n puolikas palvelee vain omaa prosessiaan.
Sinne TLBhen.
Sinne voi ihan vapaasti toteutus lisätä bittejä, sen formaatti ei ole arkkitehtuurillisesti määriteltyä tilaa.
Arkkitehtuurillisesti on määritelty ainoastaan CR3/CR4-rekisterit, sivutaulujen formaatti ja TLBn flushauskäsky jolla sieltä voidaan poistaa yksittäisiä entryjä.
"TLB cache"… mitäs nyt tuolla tarkoitat?
Ja tuo "nopeuskriittinen paikka" ja "tuohon tarkoitukseen".
Kaikki TLB-accessit on sitä, että tehdään osoitteenmuunnosta lukemiselle tai kirjoitukselle.
Sinä nyt ilmeisesi haet tässä sitä, että "käytetään vain virtualisointiin".
Mutta sinne ei todellakaan aleta tekemään kahta täysin erilaista ja erinopeuksista datapolkua LSUihin sen mukaan, onko nyt virtualisointi käytössä vai ei.
Se TLB-haku kestää ihan yhtä kauan kummassakin tapauksessa. Ja prosessorin pitää siihen pystyä silloin kun se virtualisointi on käytössä.
Ja itseasiassa:
Nehalemissa L1D-viive kasvoi kolmesta neljän kellojaksoon. Syy saattoi olla juuri tässä.
Kyllä se on ihan dynaamisesti jaettu ainakin Zenillä:
Mutta todennäköisesti tuossa SMT-TAGinä on kuitenkin vain se yksi bitti että kummasta virtuaaliytimestä on kyse, eikä CR3+CR4n sisältöjen perusteella tehtyä tagausta.
Samoin ainakin Sandy Bridgellä ja Haswellilla (ja Ivy Bridgellä ja Broadwellillä) TLBt on täysin dynaamisesti jaettu virtuaaliytimien välillä. Näissä load- ja store-puskurit on käytännössä ainoat staattisesti jaetut resurssit.
Mennyt jo niin sivuraiteille että tiedä mistä aloittaisi.
Eli siis kuten sanoin, context switchissä ei normaalissa x86-ympäristössä tarvitse tehdä TLB flushia, ainoastaan user mode puoli TLB:sta flushataan prosessin vaihtuessa.
TLB taggaus taas … eli x86:ssa sitä ei normaalisti käytetä, ja jos käytetään niin sitä ei käytetä SMT:n virtuaaliprosessorien erotteluun, ainoastaan TLB:n sisällöt tallennetaan ja palautetaan palattaessa samaan prosessiin.
Ja prossu toki voi mapata TLB:n dynaamisesti kahdelle threadille yhdellä bitillä mutta se on eri asia kuin mitä yleensä tarkoitetaan TLB:n taggauksella.
TLB on nimenomaan cache, cache osoitemuunnoksille.
Eli TLB on yksi nopeuskriittisimpiä kohtia prossun liukuhihnalla, joka osoitetieto pitää saada muutettua ennen cachen lukemista. Eli TLB:n taggaus tietylle prosessille vaatii sen verran monta bittiä että sitä ei yleensä käytetä TLB-muunnoksia tehtäessä vaikka arkkitehtuuri sitä tukisi.
Mitähän ihmettä tässä oikein yrität selittää?
No tästä voidaan olla samaa mieltä
Intelillä ainakin ITLB on joko staattisesti jaettu tai kokonaan duplikoitu threadien välillä.
Mutta pointtihan ei ollut se vaan että TLB-taggaus ei ole pakollinen SMT:ssä, TLB:t voivat olla täysin erilliset virtuaaliprosessoriytimien kesken.
Nyt oot oikeassa, näin tää Intelin tapauksessa toimii. Mutta enpä tosiaan itse tajunnut koko asiaa, missään ei ole mun mielestä uutisoitu että Intelin MMU:kin vuotaa kuin seula. Tottakai MMU:n pitäisi tehdä käyttöoikeustarkastus ennen uuden osoitemuunnoksen tekemistä, tässä Meltdown-vuodossa on siis PALJON vakavammasta ongelmasta kyse kuin oon käsittänytkään.
-> luettuna alkuperäisestä Meltdown raportista: Sidechannel hyökkäys spekulatiiviseen osoitteeseen saa prossun tekemään pagewalkin, päivittämään TLB:n cacheen osoitemuunnoksen ja lataamaan ko. cachelinen muistiin josta siitä voidaan kaivella dataa toisella hyökkäyksellä -> aivan naurettavan helppoa pollata koko kernelin muistiavaruus ja siinä sivussa koko fyysinen muistiavaruus siltä osin kun se on kerneliin mapattu.
Sitten vielä Intel on lisännyt TSX:n jossa on ominaisuuksia joissa on tietoturvan kannalta aika kyseenalaisia ratkaisuja, paketoituja käskyjä jotka palauttaa prosessorin edeltävään tilaan jos yksi paketoinnin käskyistä ei mene läpi -> lopputuloksena tuon Meltdown raportin esimerkkikoodilla saadaan dumpattua 6700K:lla 503KB/s kernelidataa 0.02% virheprosentilla aivan koko muistiavaruudesta.
Juu Meltdown-paikoilla oli hiukan kiire, toisaalta mitä vittua Intel, kuka tuolla puljussa on antanut valtuutukset poistaa kaikki normaalit käyttöoikeustarkastukset käytöstä?
Jokos sen saa paljastaa kuinka meltdown lukua saatiin nopeutettua uudelleen , patsin jälkeenkin.
:facepalm:
Ehdotit juuri Catch-22-järjestelmää.
Että voidaan tarkasta käyttöoikeudet, pitää prosessorilla olla sivutaulujen data.
Mutta että voidaan ladata sivutaulujen data, pitäisi sinun mielestäsi olla ensin tarkastettu käyttöoikeudet.
Sivutaulujen lataamisessa ei ole mitään haavoittuvaista. Niitä ei koskaan ladata käyttäjän määrittelmästä paikasta, vaan kernelin määrittelemästä paikasta. Ja tämä paikka on määritelty fyysisenä osoitteena eikä virtuaaliosoitteena. Niitä ladatessa ei edes pystyisi tekemään mitään käyttöoiikeustarkastusta, koska käyttöoikeudet on määritelty vain virtuaaliosoitteille (sivukohtaisesti).
Sun pitää vastustaa ihan periaatteesta kaikkea mun kirjoittamaa? MMU on ihan erillinen, prosessorista riippumaton yksikkö. MMU:lle on aivan perusasia että käyttöoikeudet tarkastetaan ennenkuin osoitemuunnos välitetään prosessorille, mitä vittua sillä koko MMU:lla tekee jos se ei sitä suorita. TLB:n nopeusoptimoinnin nyt tajuaa mutta MMU:lla pitäisi olla aikaa tarkistaa oikeudet aina.
Kun joku on pihalla kuin lumiukko ja postaa ihan täyttä tuubaa esittäen todella tietävää asiantuntijaa niin silloin reagoin ja kerron missä tuuba on tuubaa.
Jos postaisit jotain joka pitää paikkaansa niin sitten en "vastustaisi".
Sinulla vaan tuntuu olevan ihan käsittämätön Dunning-Kruger-efekti tietotekniikan osaamisessasi. Jatkuvasti luulet osaavasi asioita, joita et oikeasti osaa etkä ymmärrä ja sitten hirveällä innolla alat vänkäämään niistä.
Jossain 68020ssä(jossa se oli optionaalinen, eri piirilläkin). Sen jälkeen ei enää.
:facepalm:
Näytät olevan täysin pihalla siitä, mitä sivutaulut ovat.
Sivutaulujen lataus ei ole käyttäjän tekemä muistinlataus. Sivutaulut ladataan, jotta se MMU itse voi toimia, ja sen jälkeen tehdä sen osoitteenmuunnoksen ja oikeustarkastuksen sille käyttäjän tekemällä muistiaccessille. Sivutaulujen latauksen tekee oikeastaan MMU, ei "käyttäjän koodi".
Ninkuin oikeasti, voisitko ystävällisesti ensin yrittää ottaa perusasiosta ensin selvää.
Se, että luet vaikka mitä nippelitietoa ei paljoa auta jos et ymmärrä lukemaasi, jos et ymmärrä vänkäämiesi asioiden oikeita toimintaperiaatteita.
Nyt et vittu oo tosissas, eiks tää kerro just susta 😀
Siis kun MMU teke pagewalkin eli hakee muistisivut ja tekee osoitteenmuunnoksen miksi se ei tässä vaiheessa tarkistaisi myös käyttöoikeuksia ja vasta sen jälkeen kirjoittaisi tulosta TLB:hen myöhemmin käytettäväksi? Side-channel attack vaatii että osoitemuunnos löytyy TLB:stä jotta ko. osoitteen muisti voidaan lukea sinä aikana kun spekulatiivista väärää osoitetta ei ole vielä sellaiseksi ehditty tunnistaa.
Näin ohimennen mielenkiintoista lukea itselle täyttä haltiakieltä olevaa juttua sivukaupalla ja lähinnä kahden käyttäjän väittelyä. :dead:
Itseasiassa varsin mielenkiintoista luettavaa. Tästä kun koittaa poimia vielä sen oikean faktan niin saa hyvin tietoa ko. aiheesta. :tup:
Riippumatta siitä, on se nyt tehtävä muistiosoite laillinen, laiton vai spekulatiivinen laiton, se muunnosdata halutaan sinne TLBhen tallettaa, jotta seuraava osoitteenmuunnos ja turvallisuustarkastus sille samalle sivulle olisi myös nopea. Saadaan sitten seuraavalle accessille nopeasti se tieto, mihin sivuun se osoittaa ja tieto että "tämä on laiton osoite, sen pitää heittää poikkeus" sen sijaan että alettaisiin siinä vaiheessa jälleen tekemään neljää (turhaa) muistiaccessia sen sivutaulun lataamiseksi, kun sitä edellisen kerran ladatassa ei sinne TLBhen tallennettu.
Ja Meltdownin kannalta ihan sama missä järkestyksessä oikeuksien tarkastaminen ja TLBn kirjoitus tehdään, kun molemmat kannattaa kuitenkin tehdä, kun ongelma ei Meltdownissa ole mikään tarkastuksen tekemättä jättäminen vaan siihen reagoiminen. Efektiivisesti ne tehdään kuitenkin rinnakkain.
Mihin nyt viitaat sanalla "sellaiseksi?" Laittomaan vai spekulatiiviseen?
Ja tulkitsee tuon kummalla tahansa tavalla, ei vaadi etukäteen. Se TLB-entry voidaan aivan hyvin ladata sillä samalla muistiaccessilla mikä sen laittoman spekulatiivisen latauksen tekee, jos se ei tule DRAM-muistista asti vaan esim L2-välimuistista, ja samalla jollain muulla fyysisen muistin lataamisella tai hitaiden käskyjen (esim jakolaskujen) sekvenssillä hidastetaan sen haarautumisen tarkastamista.
No TLB:n osalta voisi äärimmäinen optimointi mennäkin näin. Mutta entäpäs miksi sitten sen spekulatiivisen laittoman osoitteen data ladataan cacheen, sitä ei melko varmasti tulla tarvitsemaan 😉
Jaksat ja jaksat jänkätä. Intelin x86-prossut on nykyisin täysin rikki tietoturvallisuuden osalta koodilla jota niiden olisi tarkoitus ajaa, etkö näe tässä mitään ongelmaa?
Ja mikä itse Meltdown-ongelma on, siis prosessori saadaan huijattua lataamaan spekulatiivisesti koko muistinsa tarkastamatta käyttöoikeuksia juuri sen takia missä järjestyksessä käyttöoikeuksia tarkistetaan ja TLB:hen kirjoitetaan. Olin aluksi vähän skeptinen kun AMD ilmoitti heti että heidän prossunsa ei kärsi Meltdownista mutta tarkemmin ajateltuna se on aivan päivänselvää, prossun tietoturvasuunnittelun pitää olla aivan perseestä ennenkuin Meltdown tässä määrin tulee mahdolliseksi.
No pistäs referenssi tähän, vai päättelitkö ihan itse 😀
Mitä tämä uutisen otsikko oikein tarkoittaa : "Intelin prosessoreista löytynyt bugi vaatii suorituskykyyn vaikuttavan käyttöjärjestelmätason"
Taitaa olla lyhennetty otsikkoa leikkaamalla.
Intelin prosessoreista löytynyt bugi vaatii suorituskykyyn vaikuttavan käyttöjärjestelmätason päivityksen
Puuttuu forum puolelta tuo päivityksen. Ei taida mahtua otsikkoon…
Niin, siinä Intel tekee turhaa työtä ja haaskaa energiaa ja muistikaistaa melko harvinaisessa tilanteessa. (ja lisäbonuksena on altis meltdownille).
Ja syynä oli se, että näin saatiin prosessorin rakenteesta yksinkertaisempi, vähemmän logiikkaa sinne latausyksiköihin. Siinä vaiheessa kun tämä ratkaisu tehtiin varmaan myös ajateltiin, että tämä tekee prosessorista luotettavamman, vähemmän paikkoja bugeille. Tämä vaan osoittautui virheelliseksi päätelmäksi.
Tämän takia pidän todennäköisempänä, että AMD on immuuni Meltdownille nimenomaan sen takia, että AMD halusi tehdä omista prossuistaan energiatehokkaampia eikä halunnut haaskata virtaa (ja kaistaa) tekemällä turhia laittomia loadeja, ja oli valmis lisäämään prosessoreihinsa monimutkaisuutta niiden laittomien latausten katkaisemiseen jo aiemmassa vaiheessa. Ja tämä sähkönkulutuksen ja muistikaistan optimointi myös teki AMDstä immuunin meltdownille. Eli että ihan virran- ja kaistansäästösyistä AMD sattui tekemään prossuistaan immuuneja meltdownille.
(en kuitenkaan ole varma tästä AMDn motivaatiosta)
Ei ne ole mitenkään "täysin rikki". Ne on täysin speksinsä mukaisia, alkuperäinen speksi vaan ei ota sivukanavahyökkäyksiä huomioon. Ja meltdowniin on olemassa softa-workaround joka suojaa siltä, siitä vaan tulee pieni suorituskykyhaitta kernel-kutsujen yhteydessä.
TLBllä ei edelleenkään ole tämän kanssa mitään tekemistä. Vaan vain sillä, koska laittomaan muistiosoitteeseen reagoidaan.
Ihan itse päättelin. Ei vaadi paljoa päättely- eikä laskutaitoa, kun ymmärtää miten välimuisti ja virtuaalimuisti toimii.
Sivutauluja kakutetaan melko normaalisti ainakin L2-kakuissa, (L1-kakuista en ole aivan varma, mutta ilmeisesti ei niissä). (*) Neljä riippuvaista latausta L2-kakusta tekee n. 48 kellojaksoa.
Efektiivisesti osoitteenmuunnos siis kestää n. 48 kellojaksoa ylimääräistä, jos sivutaulut tulee L2-kakuista eikä muunnostietoa löydy TLBstä.
Aivan triviaalia viivästää sitä ehdon tarkastelua tuon verran enemmän. Yksi riippuvainen haku DRAM-muistista asti sille hypyn ehdolle tekee heti yli 100 kellojaksoa.
(*)
Ja juuri tähän sivutaulujen kakuttamiseen liittyi Phenomin kuuluisa bugi, siinä ei toteutunut välimuistin koherenttius täydellisesti sivutaulujen latausten osalta ja tietyssä tilanteessa sivutauluja muuttaessa toinen prosessoriydin luki ne välimuistista väärin; workaround oli kokonaan kieltää sivutaulujen lataaminen välimuistista ja ladata ne aina DRAMilta asti)
Taidatpa vaan olla päättelyinesi yksin. Näitähän kutsutaan TLB-sidechannel hyökkäyksiksi nimenomaan sen takia että TLB:n tulokset tulevat liukuhihnalle käskyn kulkiessa, koko TLB:tä ei välttämättä dekoodata vaan vain osa jonka perusteella pystytään L1-cachesta lukemaan data, ja Intelin tapauksessa esimerkiksi se käyttöoikeus tarkastetaan vasta liukuhihnan lopussa, varmaan samalla kun tarkistetaan että osittain dekoodattu osoitemuunnos osui. Tästä sitten seuraa että aikaa ajaa spekulatiivisia käskyjä hyödyntäen on tietty osa liukuhihnan pituutta, 48 kellojaksoa (optimistinen arvio pagewalkille) on varmasti riittävän pitkä aika vesittämään tuon idean, varsinkin kun ainakaan esimerkeissä ei ole käytetty mitään poikkeuksellisen pitkiä suoritusaikoja omaavia käskyjä, kaikki tapahtunee normaalin liukuhihnan pituudella.
Saat pistää referenssiä jos joku muu on kanssasi samaa mieltä.
Pitää näköjään pitää oppitunti vielä L1-kakunkin toiminnasta…
L1n indeksoimiseen ei järkevästi toteutetulla L1D-välimuistilla tarvita YHTÄÄN bittiä sieltä TLBstä (koska VIPT). Ja intel ei ole ainakaan 486n jälkeen tehnyt muita VIPT-välimuisteja.
Virtuaalimuistisivu on 4096 tavua. Osoitteen 12 alinta bittiä(tai oikeastaan bitit 6:11, alimmat 6 voi vielä ignorata, koska välimuistilinjat) kertoo suoraan, missä indekseissä data voi välimuistissa olla. 8-tie-joukkoassosiatiivisessa välimuistissa on 8 kohtaa, joilla on tämä sama indeksi.
(ei ole sattumaa, että välimuistin koko on 32kiB ja sen assosiatiivisuus on 8, tämä on erittäin tarkkaan suunntieltu ominaisuus)
Näiden kahdeksan kohdan lukeminen (sekä data että tag-bitit) voidaan(*) siis aloittaa HETI odottamatta yhtään mitään TLBltä.
Eli samaan aikaan voidaan rinnakkain tehdä seuraavat asiat:
* lukea 8stä mahdollisesta (saman indeksin omaavasta kohdasta) paikasta välimuistista data ja tagit
* lukea TLB.
JA sitten seuraavalla kellojaksolla, kun nämä on tehty, tehdään tarkastus, vastaako jonkun kahdeksasta ladatusta välimuistilinjasta tag-bitit sitä arvoa, mikä TLBltä saatiin.
Ja tähän tarvitaan ihan kokonaan se fyysinen osoite.
Jos jonkun ladatun välimuistilinjan tagit osuu, sitten meillä on osuma, ja sen sisältö (alimpien kuuden osoitebitin osoittamasta kohdasta) välitetään lataukselle datana, ja muiden välimuistilinjojen data ifnorataan.
Jos taas minkään ladatun välimuistilinjan tagit ei osu, meillä on huti, ja sitten pitää lähteä huhuilemaan dataa seuraavalta välimuistitasolta.
Että mistä ihmeen osittain dekoodatusta osoitteenmuunnoksesta nyt oikein höpiset?
(*)
Käytännössä tosin virran säästämiseksi nykyään kaikista kahdeksasta ei välttämättä ainakaan dataa accessoida heti rinnakkain, vaan ehkä ensin vain kaikkien tagit sekä data vain yhdestä, jossa se todennäköisemmin on, ja sitten menee esim. ylimääräinen kellojakso jos se ei ole siellä, vaan jossain muussa (way prediction).
Mielenkiintoista keskustelua. Jotenkin tulee tämä mieleen.
![[IMG]](https://images.duckduckgo.com/iu/?u=http%3A%2F%2Ffarm4.staticflickr.com%2F3414%2F4628611135_d94357c77a_z.jpg&f=1)
😀
No kyllähän ne nyt on aika helvetin isosti rikki vaikka kuinka vänkyttäisit muuta. Lisäksi kuiske kuuluu että nuo workaroundit on jo kierretty joten seuraavaan workaroundia odotellessa ja katsotaan miten sitten taas tulee performance hittiä.
Ja vaikka sinä kuinka vänkyttäisit, niin intel ei ole rikki eikä amd ole rikki.
Jos intel on rikki, niin siitä seuraa että amd on rikki. Tästä taas seuraa että koko konsepti rikki on merkityksetön. Kaikki on aina rikki.
Jos Intelin prosessorit ei olisi isosti rikki, niin ei olisi nyt mitään meltdown fiaskoa.
Eli koko konsepti rikki on täysin hyödytön. Kaikki on rikki. Logiikallasi mikä tahansa jälkikäteen löydettävissä oleva asia tekee rikkinäiseksi, joten siitä seuraa että kaikki rikki.
Amd:stä löytyi spectre, joten sekin on rikki. Armit on rikki. Jne.
Täyttä paskaa sanon minä.
Kyllä. Lähes kaikki on rikki. Toiset enemmän toiset vähemmän.
Tässä pari huumori kuvaa, intel logo tiimi ollut selvästi aikaansa edellä. 😆
Wanhat prossut saa kuin saakin Spectre päivityksiä, hieman statustietoa täältä: https://newsroom.intel.com/wp-content/uploads/sites/11/2018/02/microcode-update-guidance.pdf
Eli siellä on jo pre-betat olemassa Sandylle ja Ivylle jne. Eli eiköhän lähikuukausina noi tule jakoon ihan suoraan käyttöjärjestelmän päivitysten mukana.
Helpompi tapa käyttää näitä reikiä https://gizmodo.com/researchers-find-new-ways-to-exploit-meltdown-and-spect-1823020029
Vaikuttaa edelleen hyvin hitaalta ja epävarmalta nyhräämiseltä..
Ja sillähän ei ole mitään väliä, koska koneen korkkaajan tarvitsee perinteisesti onnistua hommassa vain kerran jolloin omistajan peli on menetetty
Toki sillä on paljonkin väliä, miten tuota voidaan hyödyntää suuressa mittakaavassa. Hitaalla nyhräyksellä on se paha riski, että käyttäjä vittuuntuu ja siivoaa nyhräävän haitakkeen pois ja tekee myös ilmoituksen korkatuusta sivustosta ja lähettää mahdollisesti näytteen virustorjuntafirmaan joka yrittää työntää haitakkeen koneelle.
Itsekin olen jokusen ilmoituksen tehnyt. Fiksut haitakkeen työntäjät eivät tosin yritä saada samaa konetta tekemään epämääräisyyksiä montaa kertaa peräkkäin / päivä.
Optimoit sitten koko TLB:n pois, muuten hyvä mutta ilman TLB:tä cache voi osoittaa sen 12 bitin verran, 4kilotavua assosiaktiivisuudesta riippumatta, se ei liity tähän. Intelin L1D-TLB taulukko 4KB:n sivuille taitaa nykyään olla 128, eli 7 bittiä ja 8 bitin cachelinjat eli jokainen cachelinja pystytään ohjaamaan omaan osoitteeseensa TLB:n avulla. TLB sitten voidaan optimoida, eli 36 virtuaalimuistibittiä on aivan turha dekoodata, esimerkiksi 9 eli sivutaulun mukainen määrä antaa 2megatavun alueen jolle voidaan mapata 128 cachelinjaa, assosiaktiivisuus vain pilkkoo nuo pienemmiksi osiksi eli koko TLB:tä ja välimuistia ei tarvitse käydä läpi haussa, ainoastaan se assosiaktiivisuuden osa joka voi sisältää tuloksen.
Intelin prosessorit tekevät täysin uskomattoman typeriä juttua MMU:n ja spekulatiivisten lukujen suhteen. KPTI korjaa vain kernelin suorat muistiosoitukset pois, koko userspace on silti aivan täysin haavoittuva. Oletko kattonut miten Intelin prossut vuotavat datan, ei tarvii kuin osoittaa haluamaansa osoitetta ja käyttää sitä johonkin aktivoimaan cachelinja. Eli ei minkäänlaista suojausta, spekulatiivinen muistihaku rikkoo kaiken. Toimivat Meltdown-mikrokoodipäivitykset vain sitten joutuvat ottamaan myös spekulatiivisen muistinkäsittelyn pois päältä ja tämä syö suorituskykyä niin että tuntuu.
Meltdown-attack onnistuu melkein keltä tahansa joka saa hello worldin koodattua. Meltdown-paperissa koodia ei käytetä kuin kernelidatan vuotamiseen mutta sama tapahan toimii Spectrenä eli userspacen vakoiluna, kaikki userspaceen sandboxattu koodi pystyy lukemaan isäntäohjelman kaiken datan. Webbiselaimiinhan tuli "Fixi" jossa ajoitustarkkuutta laskettiin jotta aivan naurettavan helppo reiän hyödyntäminen ei onnistu, mutta se ei varmasti ole kovinkaan pitävä paikkaus.
:facepalm:
Yritä nyt ymmärtää, miten välimuistin osoitteistus ja kirjanpito toimii. Lue vaikka viestini uudestaan ajatuksella läpi.
Siihen, että katsotaan mistä paikasta välimuistia jotain data löytyy jos se sieltä löytyy ei tarvita muita kuin niitä alimpia bittejä. Se määräytyy tuollaisessa välimuistissa vain niiden 12 alimman bitin perusteella.
Siihen, että tarkastetaan että osoittaako tämä data välimusitissa siihen paikkaan mihin nyt tehdään access tarvitaan sitten koko osoitetietoa.
Tämä mahdollistetaan että itse dataa (ja tagibittejä) voidaan hakea rinnakkain välimuistista ja sen osoitteen ylompiä bittejä TLBstä.
Mutta se osumantarkastus voidaan tehdä vasta kun osoitteenkuunnos on tehty.
Näin toimii VIPT-välimuisti.
Se, millainen on TLBn rakenne ja se, millainen sen L1D-välimuistin rakenne on kaksi täysin eri asiaa.
Tässä puhuttiin datavälimuistin rakenteesta, ei data-TLBn rakenteesta.
:facepalm:
Ei ole mitään yhtenäistä 2 megatavun aluetta missään jos käytetään 4 kiB virtuaalimuistisivuja. Jokainen 4 kiB virtuaalimuistisivu voi osoittaa fyysisessä muistissa aivan eri paikkaan.
Ja sen sivun fyysinen osoite on kokonaisuudessaan siellä sivutaulun viimeisellä tasolla. Sivutaulun aiemmissa tasoissa on pointteri siihen seuraavaan tasoon, ei mitään fyysisen osoitteen "sillä kohdalla" olevia bittejä
(ja millä ihmeen laskuopilla saat jotain 128 välimuistilinjaa johonkin?)
Ja siinä vaiheessa kun tarkastetaan, onko välimuistissä indeksiin numero 0 säilötty osoitteiden 32768-32831 data vai osoitteiden 2147483648-2147483711 sisätämä data, tarvitaan kyllä ihan jokaista osoitteen yläbittiä. Jos siellä puuttuisi yksikin bitti, sitten sen bitin kohdan verran toisistaan eroavat eri osoitteet sotkeentuisi välimuistin kirjanpidossa.
Ja sitä "osaa" välimuistista jossa se data voi olla, kutsutaan nimellä "setti" ja sen järjestysnumeroon (alkaen nollasta) viitataan termillä "indeksi".
Ja vaikuttaa muutenkin siltä, että olet tainnut käsittänyt assosiatiivisuuden aivan väärinpäin.
Pitää nimenomaan vääntää VIELÄ enemmän rautalankaa välimuistista.
Tosin Dunning-Kruger-efekti taitaa olla sillä tasolla että mikään rautalanka ei taida mennä perille, että miksi edes yritän..
Seuraava ei liity vielä mitenkään virtuaalimuistiin eikä TLBhen:
Ilman assosiatiivisuutta oleva välimuisti == direct mapped, "suorasijoittava"
Direct-mapped-välimuistissa jokaiselle muistiosoitteelle on tällöin tasan yksi mahdollinen paikka(indeksi), missä se voi välimuistissa olla. Tällöin osoitteen N alinta bittiä kertoo SUORAAN ja TARKKAAN sen, mihin kohtaan välimuistia se data menee, jos se sinne menee.
Välimuisti jossa on 64 tavun linjat, 32 kilotavun kapasiteetti, tarkoittaa että eli indeksejä on 512 kappaletta(0-511). 6 alinta bittiä(0:5) valitsee tällöin tavun välimuistilinjalta, seuraavat 9 bittiä(5:14) osoitetta valitsee suoraan indeksin, jolta data löytyy, JOS se välimusitista löytyy. Ja kaikki ylemmät bitit tallennetaan välimuistin tagikenttään..
Eli tällöin muistiosoitteet esim. 0x0, 0x8000, 0x10000, 0x18000, 0x2000, 0x10000000, 0x20000000, 0x400000000000 mevät kaikki välimusiti-indeksiin, eli indeksiiin 0. Ainoastaan yksi niistä voi kerrallaan olla tallennettuna välimuistilinjaan. Ja osoitteet 0x40, 0x8040, 0x18040, 0x2040, 0x10000040, 0x20000040, 0x400000000040 menevät kaikki välimuisti-indeksiin 1. Ainoastaan yksi niistä voi kerrallaaan olla tallennettuna välimuistiin.
Kun sitten tulee musitiaccess vaikka osoitteeseen 0x50000000, otetaan esin osoitteesta ne bitit, joitka muodostavat indeksin, accessoidaan välimusitia siitä indeksista, ja verrataan, mitä välimuistin tag-kentästä löytyy siitä indeksistä. Löytyykö sieltä samat ylimmät bitit kuin mihin nyt halutaan osoittaa, jolloin välimuisti sisältää sen osoitteen mitä haluttiin hakea, vai löytyykö sieltä jotkut muut bitit, jolloin välimuistissa on talletettuna jonkun muun osoitteen data, ja meillä on huti.
Tämän tarkastamiseen tarvitaan osoitteen kaikki ylimmät bitit. Jos sieltä jätettäisiin joku ylempi bitti pois, sitten sen bitin position verran tosistaan eroavia osoitteita ei välimuistin kirjanpidossa voisi eroittaa toisistaan, ja välimuistista annettaisiin toisen data toisen osoitteella.
Suorasijoittavan välimuistin pahin huono puoli on, että usein tehdään accesseja välimuistin koon kerrannaisen päähän toisitaan(kaikki kiva on kahden potensseissa, sekä välimuistien koot että yleiset taulukkokoon koodissa jne). Accessit peräkkäin osoitteisiin 0x8000 ja 0x10000 ja sitten taas 0x8000 ja sitten taas 0x100000 johtaa siihen, että 0x10000 menee välimuistissa samaan kohtaan (indeksi numero 0) kuin missä 0x8000 oli eli 0x8000 heitetään välimusitista pihalle. Sitten se joudutaan kolmatta accessia varten jälleen lataaman välimuistiin, ja heittää samalla osoitteen 0x10000 datan pihalle välimuistista. Ja sitten jälleen viimeinenkin access on tämän takia huti.
Sitten otetaan virtuaalimuisti ja TLB huomioon:
Ja jos tällaisen 32kiB suorasijoittavan välimuistin kanssa käytetään 4 kiB virtuaalimusitisivuja, osoitteenmuunnos pitää tehdä ennen välimuistista hakemista, koska osoitteenmuunnos vaikuttaa bitteihin 12:14 joita tarvitaan indeksin valitsemiseen, eli ennen osoitteenmuunnosta ei voida tietää, mistä indeksistä se välimusitista löytyy. Ei siis voida käyttää VIPTiä
Jotta direct mapped-cachelle EI tarvi osoitteenmuunnosta tehdä ennen kuin access siihen aloitetaan, tarvii sen koon olla niin pieni, että koko indeksi löytyy sieltä virtuaalimuistisivun sisäisistä biteistä, eli cachen koko maksimissaan virtuaalimuistisivun kokoinen.
Assosiatiivinen välimuisti taas tarkoittaa sitä, että siellä on efektiivisesti monta pienempää välimuistia rinnakkain(jokaista näitä kutsutaan nimellä way/tie). 8-tie-joukkoassosiatiivisessa niitä on 8. Ja data voidaan säilöä mihin tahansa niistä siihen indeksiin, mihin se osoitteeseensa mukaan osuu.
Eli nyt osoitteiden 0x8000 ja 0x10000 data voikin olla yhtä aikaa säilöttynä välimuistiin, koska osoite 0x8000 voi olla vaikka laitettu ensimmäiseen tiehen indeksiin 0 ja 0x10000 toiseen tiehen indeksiin 0.
Yksi setti muodostaa kaikkien näiden kahdeksan rinnakkaisen välimuistien samalla indeksillä olevat välimuistilijat. 0x8000 ja 0x10000 on indeksiltään samat(0) eli osuu samaan settiin, mutta koska jokaisessa setissä on monta välimuistilinjaa, ne voivat olla yhtä aikaa välimuistissa.
Virtuaalimuisti ja joukkoassosiatiivisuus:
Eli 32 kiB 8-tie-joukkoassosiatiivinen välimuisti koostuu kahdeksasta 4 kiB tiestä, eli 64 B linjakoolla jokaisessa tiessä on 64 linjaa. Tällöin osoitteen bittejä 6:11 käytetään linjan valitsemiseen. Kaikki mahtuvat samalle 4kiB virtuaalimuistisivulle. Voidaan käyttää VIPTiä.
ps. yhdessä suunnittelemistani prosessoriytimistä on ollut myös välimuisti.
Oletan, että sinä et sitten saa hello worldiä koodattua.
Toisilla ymmärtäminen prosessorin toiminnasta perustuu tietoon ja ymmärtämiseen, toisilla uskoon ja epämärääräisten yksittäisten tiedonjyvien lukemiseen ymmärtämättä yhtään kokonaiskuvaa ja nidein tiedonjyvästen merkitystä.
Toki kaikki sellainen, mitä ei ymmärrä, kuulostaa uskomattomalta.
Sotket nyt taas meltdownia ja specreä keskenään. Tässä mennään Spectreen, ja näiltä osin Intelin prossut toimivat täysin identtisesti KAIKKIEN spekulatiivista suoritusta tukevien prossujen kanssa. Eli siis kaikkien suorituskyvyltään yhtään järkevällä tasolla olevien prossujen kanssa.
Suosittelen vaihtamaan peruspentiumiin tai ensimmäisen sukupolven atomiin, jos tältä haluat kunnolla suojautua rautatasolla. Tai no, ARM cortex A55 on ehkä modernein tälle immuuni prossu, mutta sillä ei ajeta x86-koodia.
Ja Inteliä vastaan asian tiimoilta nostettujen kanteiden määrä on nyt noussut 35:een:
Spectre and Meltdown are now a legal pain for Intel — the chip maker faces 35 lawsuits over the attacks
Kyllä tästä jokin lasku täytyy kirjata jo ihan taseeseen.
Tätä keskustelua on ollut hauska seurata 🙂 Kieltämättä muutamassa kohtaa on meinannut kahvit tulla ulos nenästä.