Microsoft julkaisi vihdoin tänä vuonna DirectStorage-rajapinnan Windowsille. DirectStorage on samaa sukua Xbox Series -konsoleiden Velocity-arkkitehtuurin kanssa ja pyrkii optimoimaan tiedonsiirtoa peleille paremmin sopivaan muotoon Windowsin normaalin levynhallintajärjestelmän ohi.
Vaikka DirectStorage on ollut jo hyvän aikaa saatavilla vapaasti DirectX Agility SDK:n eli ohjelmistokehityskitin mukana, ei markkinoilta löydy vielä yhtään sitä tukevaa peliä. Toisaalta kuten hiljattain on selvinnyt, vaatii DirectStorage optimointeja myös SSD-ohjainpiirienvalmistajilta ja vasta hiljattain on markkinoille ehditty esittelemään ensimmäisiä pelikäyttöön optimoidun firmwaren sisältäviä SSD-asemia.
Microsoft ei kuitenkaan lepää laakereillaan, vaan on nyt esitellyt DirectStorage 1.1:n. Uusi versio tuo mukanaan kenties kaivatuimman ominaisuuden, mikä 1.0:sta uupui, eli GPU-purun tiedostoille. Toisin kuin esimerkiksi Xbox Series -konsoleiden APU-piireissä, PC-puolelta ei löydy tiettyjen pakkausformaattien rautakiihdyttimiä mistään, saati sitten suoraan grafiikkapiirin viereltä.
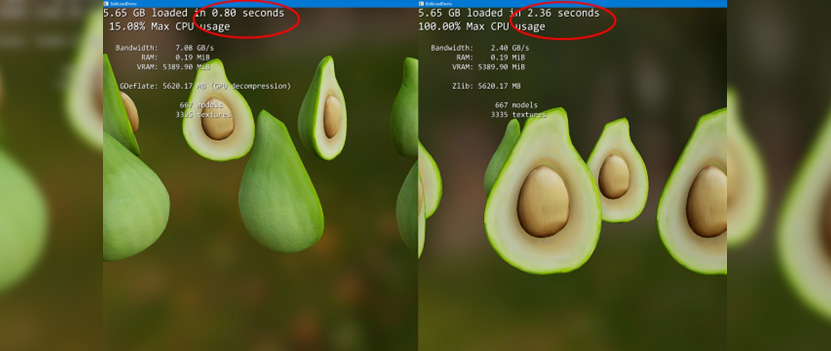
PC-näytönohjaimissa taas on puhtia enemmän kuin tarpeeksi myös purkutehtäviin ja DS 1.1:n myötä data voidaan siirtää pakattuna aina perille asti, kun DS 1.0:lla se puretaan jo prosessorilla, jolloin matkaan tulee ylimääräinen mutka ja muistin ja näytönohjaimen välinen dataliikenne kasvaa merkittävästi. Microsoftin esimerkkikuvassa tuntematon näytönohjain latasi ja purki 5,65 Gt:n edestä demon dataa 0,8 sekunnissa, kun prosessorilla aikaa vierähti 2,36 sekuntia.
DirectStorage 1.1 tuo mukanaan myös uuden pakkausformaatin, GDeflaten. GDeflate on NVIDIAn kehittämä LZ77:aan osin perustuva häviötön pakkaustekniikka, joka on saatavilla avoimena ja luovutettu virallisesti myös Microsoftin DirectX-käyttöön. Microsoft on tehnyt yhteistyötä AMD:n, Intelin ja NVIDIAn kanssa GDeflate-ajureiden parissa ja kaikkien yhtiöiden edustajat peesaavatkin DirectStorage 1.1 -tiedotteessa teknologian hyötyjä yhteen ääneen.
Pelaajan kannalta DirectStorage 1.1 ei tule vaikuttamaan vaatimuksiin mitenkään. Käyttöjärjestelmän pitää olla Windows 10 tai 11 ja vain jälkimmäisessä rajapinta pääsee täysiin oikeuksiinsa. DS toimii millä tahansa tallennusmedialla, mutta NVMe-SSD on käytännössä vaatimus merkittävien hyötyjen saavuttamiseksi. Näytönohjaimeksi riittää puolestaan mikä tahansa DirectX 12 -rajapintaa ja Shader Model 6.0:aa tukeva yksilö. DirectStorage 1.1 julkaistaan vielä tämän vuoden aikana.
Lähde: Microsoft
Taas prosessorilla purettuna aikaa meni yli kaksi sekuntia.
Tuo, tai vastaava taisi pudota kyydistä.
Lisäksi mikä sukupolvi noin suurinpiirtein on DX12 SM6?
Jääköhän lause kesken? Varmaan viittaus tuohon 2,36 sekuntiin.
”
Microsoftin esimerkkikuvassa tuntematon näytönohjain latasi ja purki 5,65 Gt:n edestä demon dataa 0,8 sekunnissa, kun …
”
High-Level Shader Language – Wikipedia
en.wikipedia.org
katso liitettä 971560
Kun raudan tehojen kasvattaminen ei ole energiankulutuksen ja lämmöntuotannon kannalta enää fiksua, tulee näitä koodipuolen optimointeja sitten vastaan. Ihan piristävää laatikon ulkopuolelta ajattelua 🙂
Vai oliko datablobbi massamuistilla oikeasti esim 500MB ja sen siirto meni salamannopeasti ja purku muistiin niin se on 5,8GB?
No luonnollisesti se ladattava data blobbi on levyllä pienempi kuin muistiin puretut tekstuurit ja muodostetut modelit. Tosin suhde nyt ei tuo 1:10 kuvadatalle ole, mutta se nyt on tässä toissijaista.
Tuohonkin saattaa tulla pian muutos, kun tuossa Sapphire Rapids Xeonien demossa oli esitelty suorittimen sisäänrakennettua QATzip-yhteensopivuutta (enää ei siis tarvitse erillistä lisäkorttia tätä varten). Tosin menee varmaan useampi vuosi, että tuo ominaisuus valuu kuluttajasuorittimiin, jos se sieltä edes tulee kuluttajille
https://images.anandtech.com/doci/17596/VIP%20Acceleration%20Experience%20Slides%2023.png
Se on sinänsä hyvä että hitaallakin lerppu ja korppuasaemalla varustetulla tallennusmedialla Windows 10/11 kone voi tuota testata ja nähdä miten se toimii. Itse hankin kyllä jo Samsungin 980 NVMe-SSD:n testailua varten kunhan tuo joskus ilmestynee…
Odotan kyllä mielenkiinnolla testejä miten paljon eroja tulee lerppu, korppu, USB-tikku, RW-CD jne jne verrattuna perinteisiin kiintolevyihin, sitten SSD levyihin ja lopulta NVMe-SSD:n.
Tuo windows 11 ”toimii paremmin” väite taisi pyöriä jo 1.0 aikaan. Onko se tekninen detaili selvillä miksi?
Kerran pari olen etsiskellyt, mutta ei ole tärpännyt. Jos kukaan ei tiedä mikä se on, niin ehkä se olisi syytä jättää pois pelkkänä Microsoftin Windows 11 promona.
Windows 11:ssä on uusittu koko storage stackia mm. juuri DirectStoragea silmällä pitäen (toki tällainenkin varmasti olisi voitu tuoda Win10 mutta ei tuotu)
Windows 10:
katso liitettä 972097
Windows 11:
katso liitettä 972098
Lähde: Microsoft Reveals Another Piece of Windows 11’s Improved Storage Stack – BypassIO
Kuten tuosta yltä näkee niin erot jaotellaan "NVMe" ja "ne muut", ellet sitten tarkoittanut ylipäätään DS:ää jota voisi testata jo nyt.
Mitään järkeä minkään muun kuin HDD, SATA-SSD ja NVMe-SSD testaamisessa ei luonnollisesti ole (no ehkä joku ulkoinen asema USB:n läpi vielä) mutta mahtuuhan maailmaan testausta jos joku katsoo asiakseen.
Varmaan ihan yksi syy on, että Win10 ja 11 ovat jo aika erilaisia ja muunneltua kerneliä ei ole haluttu lähteä tuomaan Win10. Ihan mahdoton testata kattavasti, joten ongelmia tulisi ihan varmasti. Rautaa jolla Win10 saa pyörimään on niin pirusti erilaista.
Vielä kun olisivat tuoneet AES purun sinne GPUlle, ettei olisi tarvinnut jättää bitlockeria tuosta välistä pois. Ei tule itsellä käyttöön, en halua koneelleni salaamatonta levypintaa.
Osa levyistähän hoitaa aes-purun suoraan itse. Bitlockerin saa käyttämään sitä. Uskoisin olevan GPU:ta nopeampi vaihtoehto jos niissä on siihen dedikoitu hw….En ole kyllä törmännyt testeihin kun kerran tätä etsiskelin.
Win10 ja 11 käyttää ihan samaa WinNT 10.0 ydintä ja Win11 insiderversioissa puhutaan edelleen Win10stä joka puolella. Noiden käyttisten erot on kaikin tavoin keinotekoisia, mutta niillä saatiin "pakotettua" tietoturvaa taas eteenpäin. Positiivisena puolena Win10 antaa mahdollisuuden ettei ole kaikkia uudistuksia pakko ottaa (koska osa niistä poistaa joitain ominaisuuksia) tässä vaiheessa.
Eiväthän ne voi laitttaa tuota koska uutisen mukaan "DS toimii millä tahansa tallennusmedialla" eli hitainkin lerppuasema vaikka USB 1.0 lävitse ulkoisena ja kyllä toimii. Miten tuolla sitten saataisiin se salaus toimimaan ja miten paljon lisää se hidastaisi prosessia?
Lopeta tuollainen lillukanvarsiin tarttuminen uutisen sanamuotojen vuoksi.
Niin paitsi kun tuo IO stackki ohittaa koko bitlockerin, niin et voi silti sitä käyttää vaikka AES offloadattaisiin sen SSD:n raudalle. Itse tosin en SSD:n rautaa käytä, kun osassa SSD:tä se avainten käsittley on aivan rikki, sama kuin ei olisi salausta. Enkä jaksa joka asemasta tutkia, kumpaa pitäisi käyttää. Helpompi vaan suoraan pakottaa CPU:lle kun ei se nyky prossuilla tunnu missään. Tämäkin pilipali Ryzen 5 4500U jaksaa cryptata 7,9GiB/s ja decryptata 9,0GiB/s AES-IN tuen ansiosta. (Muistista suoraan, ei ole tarpeeksi nopeaa SSD:tä tai väylää, että sen kautta edes kannattaisi benchmarkia ajaa).
Ja GPU:lla kyllä riittää vääntö AES:n auki laskentaa, josko sitä ei ehkä kannata purku rautana käyttää normaalin tiedostojärjestelmän käyttötapauksessa, koska salattua ja purettua dataa pitää sitten siirrellä CPU->GPU->CPU.
Vaan tämä tapaus on vähän eri, data kulutetaan lokaalisti GPU:lla, joten se saöais voitaisiin myös avata siellä sinne latauksen yhteydessä (ihan samalla tavalla kun Gdeflate purkaa pakatun datan GPU:lla). Ehkä sitten jossain tulevaisuuden versiossa.
AES cryptausta/decpryptausta GPU:lla käsitteleviä tutkimuksia on useita.
https://eprint.iacr.org/2021/646.pdf
– GPU Purulla 0.8s lataus.
– CPU purulla 1,1s lataus.
Intelin Arc A770:llä + i9-12900K:lla 9,14 Gt setti GPUlla 0,42s CPUlla 1,16s
https://www.intel.com/content/www/us/en/developer/articles/news/directstorage-on-intel-gpus.html
edit: Microsoftin artikkelissahan tästä mainittiinkin:
Toisessa kohtaa mainitaan myös juurikin "improved open world streaming".
Ihan samasta asiasta kyse tässä, 1.0 oli askel Xboxin Velocity -arkkitehtuuriin ja tässä tuli GPU-kiihdytetty purku sille datalle
Tarviiko siihen erikseen mitään vertailua? Koko prosessin (data, siirto, purku) efektiivinen siirtonopeus massamuistilta GPU muistiin 6-7 GB/s vaikka itse levy pystyy optimitilanteessa siirtämään 3GB/s. Kyseessä oli siis Gen3 nvme. Pelkkään siirtoon olisi mennyt pakkaamattomalla datalla yli 2s. GPU purulla meni siis 0,8s ja CPU purulla 1,1s.
Siis peleissä kaikki data mielellään pakattuna ja kun dataa haetaan niin mitä isompi pommi yhdellä kutsulla haetaan niin sen parempi. Esim yhden levelin data kokonaisuudessaan yhdellä kutsulla muistiin. Paradigmoja ja best-practices koko file I/O:lle pelin sisällä tietenkin on lukemattomia ja niitä ne pelinkehittäjät jyrsii siellä devatessa mikä on paras mihinkin tilanteeseen.
IO:n kannalta on parempi hakea yksi iso palikka vs 10000 kpl pieniä palikoita. Jokaiseen hakuun tulee latauksen lisäksi viivettä pyynnöstä ja datan "löytämisestä" tallennusmedialta. Toki liian isot haut kerrallaan eivät nekään ole optimaalisia.
Pakkausalgoritmeja voidaan yleensä parametrisoimalla säätää siten, että ne käsittelevät streamina tietynmittaisen pätkän dataa jonka yritetään pakata, joten siinä mielessä tuo IO ja pakkaus on toisistaan erillinen ongelma. Toki streamin pituuden ja pakkausalgoritmin muiden parametrien kuten dictrionaryn kasvatus kasvattaa myös pakkauksessa ja purussa tarvittavan muistin määrää.
"…ASDF…..ASDFASDF…..JKLÖ…"
Voitaisiin sanakirjana merkitä
$1 = ASDF
$2 = JKLÖ
Ja pakata se malliin:
"…ASDF…..ASDFASDF…..JKLÖ…"
->
"…$1…..$1$1…..$2…"
Jos taas on enemmän resursseja käytössä voitaisiin tehdä sanakirja malliin
$1 = ASDF
$2 = ASDFASDF
$3 = JKLÖ
Ja pakata se malliin:
"…ASDF…..ASDFASDF…..JKLÖ…"
->
"…$1…..$2…..$3…"
Tuon näet helposti vaikka leikkimällä 7zipin LZMA2 pakkaus optioiden kanssa. Normi asetuksella tarvitset pakkaukseen 200MB (per threadi) muistia ja purkuun 20MB. Jos nakkaat sen Ultralle niin pakkaukseen tarvitaan giga luokalla rammia ja purkuun satoja megoja.
Asia on oikeasti ikkupikkusen monimutkaisempi, joten jos aihe oikeasti kiinnostaa niin tuosta iltalukemista.")
Understanding zlib
Tän takia siinä rajapinnassa kasataan haut yhteen pyyntöön ja kuitataan haut massana. Voi hakea pienempiä palasia ilman järjetöntä määrää ylimääräisiä kutsuja.
PS5:en matskuissa puhuttiin 512kB palasista optimaalisena nykypeleille, kun mietitään millainen on pakkauksen tiukkuus versus haettavien palasten koko(ei liikaa ylimääräistä dataa). En jaksa kaivaa tälle 512kB palaselle lähdettä, mutta tuo se koko mun muistin mukaan oli jossain devaaja-esityksessä.
ue5:en kompressio/striimaus on hyvä pätkä aiheesta. Linkki kompressioon aikaleilamma. Tuota aikaisemmin on esitetty mitä striimataan ja miks ja miten cachetetaan
RTX IO Open Source Technology
developer.nvidia.com
DirectStorage/GDeflate at main · microsoft/DirectStorage
github.com