
HBM-muistit integroidaan interposer-alustalle grafiikkapiirin välittömään läheisyyteen. Ainoissa markkinoille julkaistuissa HBM-muisteja käyttävissä näytönohjaimissa eli Radeon R9 Fury -sarjassa HBM-muistipiiripinoja on neljä kappaletta Fiji-grafiikkapiirin ympärillä (kuvassa), HBM-piirejä on ladottu päällekkäin neljä kappaletta ja ne toimivat 500 MHz:n kellotaajuudella.
HBM-muistien sisällä ei kuitenkaan käytetä useita eri kellotaajuuksia, jotka vaikuttaisivat muistien nopeuteen merkittävissä määrin, kuten GDDR5-, GDDR5X- ja GDDR6-muististandardeissa muun muassa command clock (CK) ja write clock (WCK).
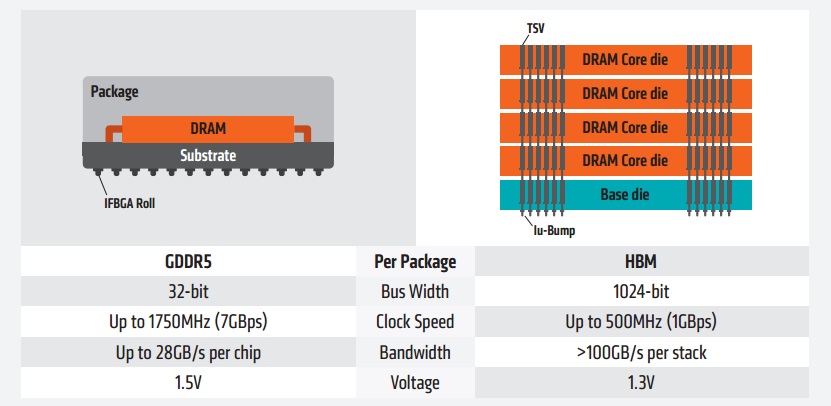
Nopeus voitaisiin siis teoriassa edelleen turvallisin mielin ilmoittaa kellotaajuutena esim. 500 MHz tai tehollisena 1000 MHz:n kellotaajuutena (DDR, Double Data Rate), jolla viitataan mahdollisuuteen siirtää tietoa kaksi kertaa kellojaksossa.
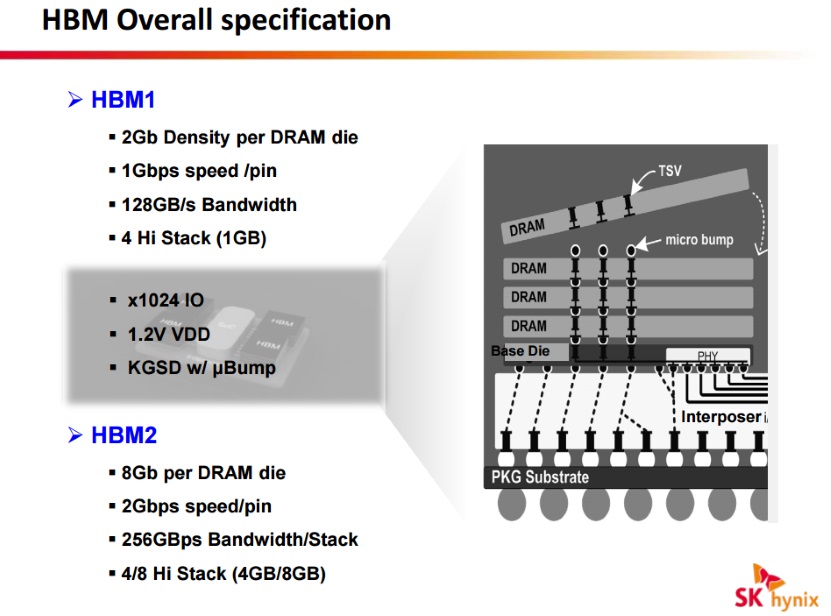
Jos halutaan käyttää siirtonopeutta, HBM-muisteissa 500 MHz:n kellotaajuudella siirtonopeus on 1 Gbps per pinni. Yhdessä HBM-pinossa on yhteensä 1024 data- eli I/O-pinniä, joten yhden pinon kaistanleveys on 128 gigatavua sekunnissa (1 Gbps/pin * 1024 pinniä / 8). Neljällä 500 MHz:n kellotaajuudella toimivalla HBM-piirin pinolla muistiväylän kokonaiskaistanleveydeksi muodostuu 4 * 128 Gt/s = 512 Gt/s.
Vaikka HBM-muisteilla yksittäisen pinnin siirtonopeus on siis alhaisempi kuin esimerkiksi GDDR5-muisteilla (esim. 1 vs 7 Gbps), HBM-muistipiiripinossa on I/O-pinnejä huomattavasti enemmän kuin yhdessä GDDR5-muistipiirissä (1024 vs 32 kpl), joten lopputuloksena HBM-muisteilla kaistanleveys on korkeampi.
HBM2-muisteilla kellotaajuus voi olla standardin mukaan maksimissaan 1000 MHz ja siirtonopeus 2 Gbps / pinni eli yhden HBM2-pinon kaistanleveys on maksimissaan 256 Gt/s.
Kun jatkossa käsittelemme HBM-muisteja io-techissä, saatamme mainita siirtonopeuden rinnalla myös kellotaajuuden.
Jälleen hienosti taklattu aiemmasta esiin nousseet kysymykset 🙂 Hienoa, kun tuodaan sitä tietoa (vielä suomeksi), jota lukijat kaipaavat.
512 Gt/s. Tämä on mielestäni selkein. Kellotaajuuden voi myös mainita, mutta todellinen siirtonopeus olisi hyvä aina löytyä.
Itse kannatan myös koko pakan todellisen siirtonopeuden käyttöä.
Muistien kellotaajuus on vähän harhaanjohtava HBM muisteista puhuttaessa.
Siirtonopeus ja vaikkapa suluissa kellotaajuus. 🙂
Eiköhän tuo siirtonopeus ole selkein kun vertailee muihin muisteihin.
Kokonaiskaista kyllä, yhden pinnin ei jos lukija ei tiedä kunkin muistityypin pinnien määrää.
Itse joka tapauksessa suosisin myös HBM-muisteista yhden pinnin Gbps-nopeutta kunhan uutisessa/artikkelissa tulee ilmi myös näytönohjaimen tai muun laitteen kokonaismuistikaista
Isoin kysymys tämän suhteen enää on.. DX12 tai Vulcanin toiminta.
Minkä tasoista GDDR-korttia sitten HBM-kortti vastaa? Miten näiden korttien kehittyvyys mahdollisuudet elää?
Onko HBM vain Fiji-piirien pituinen kokeilu? Vai onko tämä jotain uutta ja hienoa?
Itse sanoisin että jotain uutta ja hienoa, koska (käsittääkseni) GDDR5-, GDDR5X- tai edes GDDR6 ei pääse edes lähelle HBM (puhumattakaan HBM2) muistin kaistanopeuksiin.
Toki voi olla että joudutaan odottamaan (kuten tupla/dual/sli-kortteja erään tietyn Nvidian syödessä Voodoo kortteja valmistavan tekijän) mutta näkisin että tuossa on tulevaisuus. Hieman samoin kuin yhden ytimen nopeuksien nosto alkaa olla nähty prosessorien ytimissä ja moniydin prosessorit ovat tämän vuosituhannen juttu.
Sanoisin että nyt eletään murroskautta hieman samoin kuin 2-ydin prosessorien (esim. Intel® Core™2 Duo E4300 vs Intel® Core™2 Quad Q6600 KAIKKI sanoivat 2007-2008 että IKINÄ ei tulisi päivää tai tilannetta että 4-ydintä tarvittaisi kotikäyttäjän, edes tehokäyttäjän näkökulmasta poislukien serverihuoneet, vs. paremmin kellottuva 2-ydin prosessori ja vain idiootti ikinä tuhlaisi rahojaan 4-ydin prosessoriin..) yleistyessä 2007.
Määrittelisitkö "hieman" tarkemmin tuon KAIKKI väitteesi? Emme elä todellakaan mitään murroskautta, se data liikkuu edelleen ihan yhtä nopeasti ja tehokkaasti kuin sitä pystyy syöttämään. Se miten hyvin sitä pystytään hyödyntämään on toinen tarina. Tästä on hyviä esimerkkejä vaikka transitiot DDR2->DDR4 missä erot oli käytännön tasolla pitkään marginaalisia. Sama pätee mm. PCI-E väylään, missä näytönohjaimen nopeuserot oli aivan marginaalisia muistaakseni 2x jälkeen. Tämä ei toki pidä paikkaansa enää, ainakaan samassa mittakaavassa, mutta oli pitkään täyttä totta.
Samalla tavalla jo P4 aikaan oli varsin hyvin tiedossa, että vain määrättyyn rajaan asti voi ihan fysiikan puitteissa sitä kellotaajuutta viedä ja jossain vaiheessa on pakko alkaa monisäikeistään. Se muutos ja raja vain tuli vastaan paljon nopeammin kuin kukaan kuvitteli, yli 10 gigan kun kuviteltiin menevän ennen kuin se tie olisi kaluttu loppuun, muistelisin että spekulaatiot oli jossain 12 gigan paikkeilla (GHz). Muutos dualeihin vähän yllätti kaikki, mikä sitten johti siihen että kehityksellä kesti aikaa julmetusti ottaa se ytimien määrä kiinni, eikä vieläkään olla päästy edes lähelle optimaalista tilannetta. Mutta tälle on myös looginen syy siinä miten hankalaa usealle ytimelle on koodata.
En kyllä ihan näe siinä miten jonkin asia nimetään sitä samaa mitä tuossa kaikessa oli. Ennemminkin pitäisi hyväksyä ajatusmalli, että toinen on eri asia, kuin toinen. Näiden pakottaminen samaan muottiin on aivan turhaa, koska se on käytännössä mahdotonta. Se sitten johtaa vain johonkin AMD 6400+ tyyliseen kikkailuun, millä yritetään jäljitellä sitä muka oikeaa. Ei, tälle tielle ei pidä lähteä ollenkaan. Nimeämisen pitäisi olla yksinkertaista ja mahdollisimman simppeliä, sen ei edes pidä pyrkiä olemaan jokin verrannollinnen suure, koska se on aina kompromissi jomman kumman tahon suuntaan. Ennemmin sitten ilmaisee sen asian tehokkuuden ja toimivuuden käytännössä. Antaa sitten markkinoijien keksiä jotain umbba bumbba termejä joilla verrata vastustajaan, se menkööt maallikoille ja suurelle yleisölle, täällä odotan että asiat on sitä mitä ne on ja niiden nimet on juurikin sitä mitä ne oikeasti on. Se 10GHz kun ei meinaa yhtään mitään jos siitä oikeasti hyödynnetään 1%.
Vastaan siis tähän ketjuun, että ilmoitetaan ne asiat niin yksinkertaisessa muodossa kuin mahdollista, kaikki laskukaavat ja muut vastaavat minimiin. Ihan maksimi on tuo tyyli, että DDR 500MHz (1000MHz). Siitä pitäisi jo jokaisen edes vähän ymmärtävän se asia tajuta. Nämä kaikki Gbps, Gflopsit yms. on lähes yhtä tyhjän kanssa, kun niiden näkyminen käytännössä on täysin tilanneriippuvaista ja ne eivät korreloi tuloksien kanssa samassa suhteessa. Ne on enempi sitä meidän isien pippelienvertailuja ja markkinointikamaa, kuin mitään muuta. Oikeasti kaikkia kiinnostaa vain se, että mitä se tarkoittaa käytännössä ja siihen ei yhdelläkään laskukaavalla ja numero/kirjain kombolla saada vastausta.
Tottakai kyse on myös datan kuljetuksesta. Tällä hetkellä suurin osa esimerkiksi näytönohjaimista on GDDR-kortteja, niin eikö esimerkiksi emolevyjä suunnitella ja rakenneta niitä katsoen?
Onko HBM:llä tulevaisuutta sen puolella että PCI-E väylä antaisi enemmän? Tuleeko se ennen vastaan kun HBM-kortin valtava muistiväylä voittaa korkean kellotaajuuden?
Onko ohjelmointi tai prosessorien käyttö jokin mikä asettaa rajoja näytönohjaimelle?
Ja voi kyllä, olen nuori ja pojan kloppi joka vasta opiskelee. Vääntäkää tämä rautalangasta ja maalatkaa punaiseksi.
Ei. Emolevyt noudattavat ATX, mATX jne speksejä, joihin on määritelty tietty tila lisäkorteille. Sillä mitä muistia joku näyttis esimerkiksi käyttää ei ole merkitystä.
Näytönohjaimen suhteen ainut merkitys muistin kellotaajuudella on sen muistiväylän kasvattaminen. Se on ihan se ja sama onko vaikka 512 Gt/s muistikaistaa toteutettu korkealle kellotetuilla muisteilla ja leveällä muistiväylällä, vai HBM-muisteilla
Riippuu tietenkin vähän mitä tarkoitat, mutta luultavasti vastaus on kyllä. Ei tosin näytönohjaimen käyttämälle muististandardille.
Laitettu spoilereihin koska liittyy ainoastaan määreeseen "kaikki" eikä suoranaisesti HBM muistin nopeuden ilmoittamistapaan.
Toivottavasti nyt ymmärrät mitä tarkoitin määreellä "kaikki"?
Pääseepäs. Esim. Fury X:ssä on 512 GB/s kaistanleveys HBM:llä (128GB/s per piiri, 4 piiriä). Geforce 1080 Ti:ssä kaistanleveys on 484 GB/s vakiokelloilla GDDR5X-muisteilla. HBM2:lla tulee 256GB/s per piiri, ja oletettavasti Vegassa on kaksi 4 gigatavun piiriä, eli kaistanleveys tulisi olemaan sama kuin Fury X:ssä. Erona GDDR-ratkaisuihin on se, että HBM2-ratkaisussa on enemmän "kasvunvaraa", ja tietysti HBM-muisteilla itse kortti on yksinkertaisempi rakenteeltaan.
Niin, nimenomaan on sitä kasvuvaraa, HBM2:lla voi ihan yhtä hyvin pistää sen 4 piiriä (kuten GP100ssa) jolloin 2 Gbps -piireillä kaistaa olisikin jo 1 Tt/s. AMD on ilmeisesti vain laskenut että 512 Gt/s riittää vielä
Mitä jollain siirtonopeudella tai kellotaajuudella ylipäätään tekee?
Jos jotain tiettyä GPU piiriä on tarjolla useampaa eri mallia eri muisteilla ja tällee, niin silloin toki voi olla järkevää ilmoittaa ja mitata jotain muistinopeuksia erilaisilla yksiköillä.
Mutta jos on vain yhtä mallia niin kun se muisti ja GPU muodostaa kokonaisuuden, ei jollain muistin siirtonopeuksilla ole mitään todellista merkitystä. Siis minusta ainakaan.
tässä korostuu se käyttäjän ja harrastajan ero. Käyttäjää kiinnostaa vain lopputulos, harrastajaa mistä se lopputulos syntyy