
Apple piti tänään syksyn toisen ison julkaisutilaisuutensa. Apple Unleashed -teemaisessa tapahtumassa julkaistiin useimpien odotuksista poiketen peräti kaksi uutta Arm-järjestelmäpiiriä, joista kumpikaan ei ole huhuttu M1X.

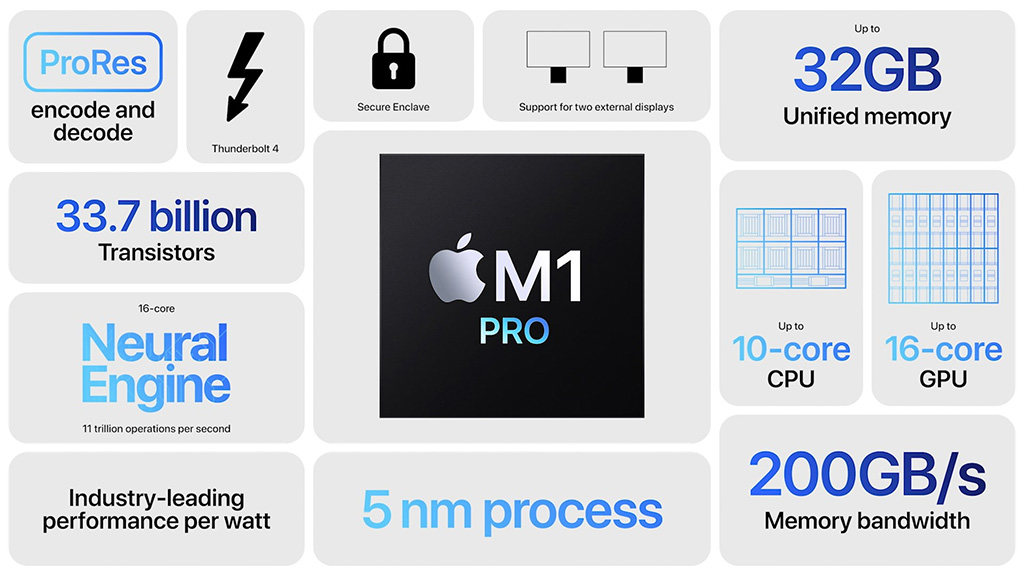
Ensimmäinen uusista järjestelmäpiireistä on M1 Pro. Yhteensä 33,7 miljardista transistorista rakentuvassa 5 nanometrin prosessilla valmistettavassa sirussa on kahdeksan suorituskykyistä ja kaksi energiatehokasta prosessoriydintä, 16-ytiminen Neural Engine, 16-ytiminen grafiikkaohjain, mediayksikkö sekä 256-bittinen muistiväylä 32 gigatavuun jaettua LPDDR5-muistia. Muistikaistaa on tarjolla 200 Gt/s.

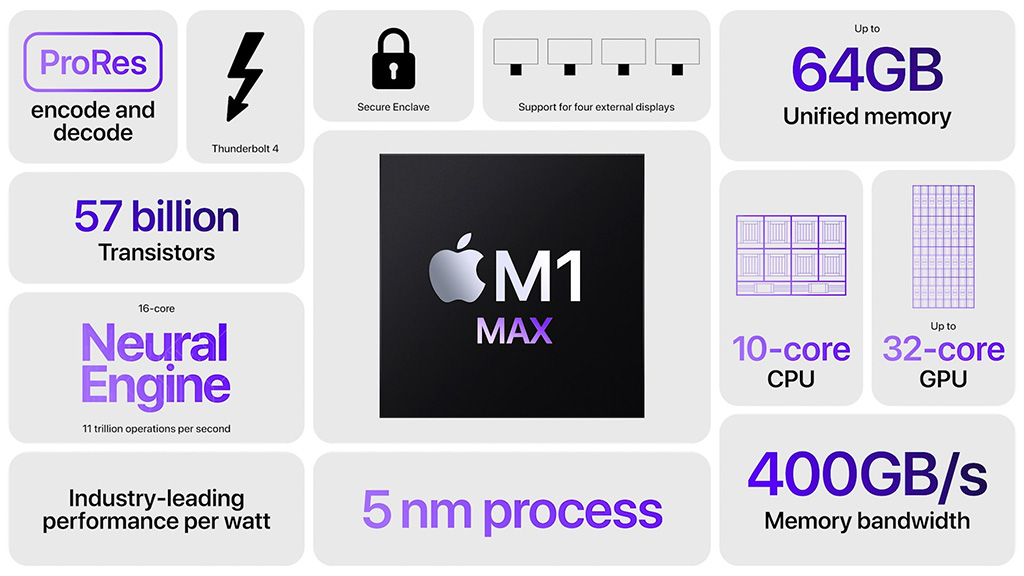
Toinen piireistä tottelee nimeä M1 Max. Peräti 57 miljardista transistorista rakentuva lippulaivapiiri pitää sisällään samat kymmenen prosessoriydintä, mutta sen grafiikkaohjain on nyt 32-ytiminen. Lisäksi LPDDR5-muistiväylä on kasvatettu 512-bittiseksi ja sen jatkeena on 64 Gt muistia, jotka yhdessä tuottavat 400 Gt/s muistikaistaa.
Applen diat paljastivat myös tarkempia tietoja grafiikkaohjaimesta. Yhdessä Applen ”GPU-ytimessä” on 128 suoritusydintä, eli 16-ytimisessä niitä on 2048 ja 32-ytimisessä 4096. M1 Pron 16-ytiminen yltää Applen mukaan 5,2 TFLOPSin ja M1 Maxin 32-ytiminen 10,4 TFLOPSin teoreettiseen laskentanopeuteen. Mediayksikkö kykenee puolestaan kiihdyttämään Apple ProRes -pakkauksen ja -purun ja Neural Engine puskee parhaimmillaan 11 TOPSin edestä laskutoimituksia.
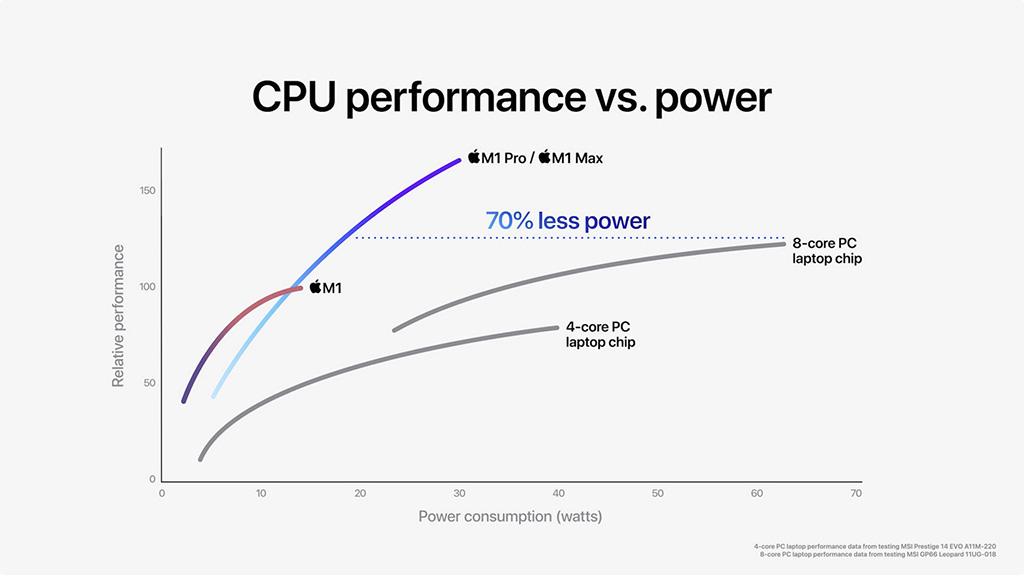
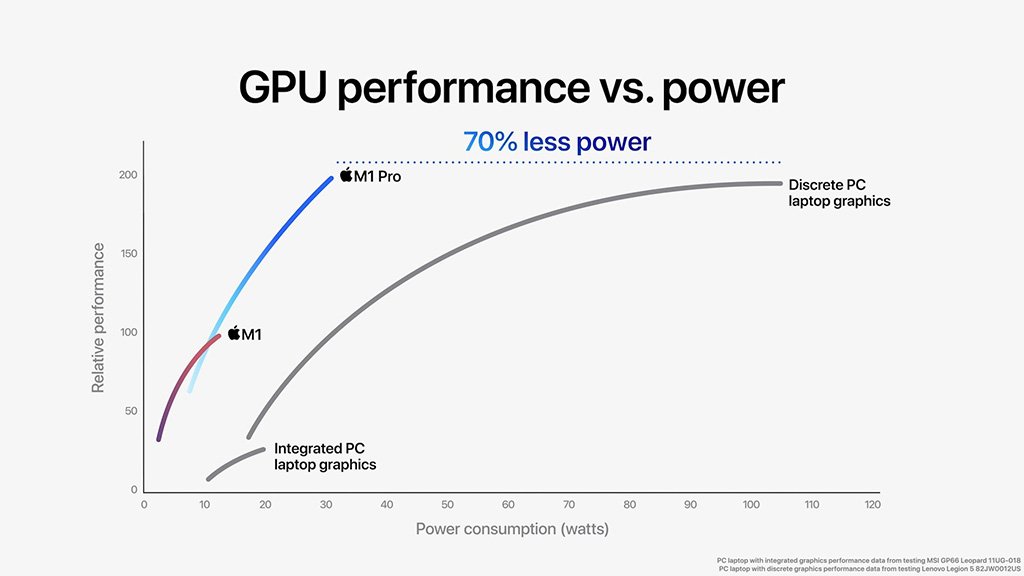
Applen omassa prosessorisuorituskykyvertailussa M1 Pro ja Max tarjoavat yhtiön mukaan 70 % parempaa suorituskykyä samalla tehonkulutuksella, kuin Intelin 8-ytiminen 7. sukupolven Core -prosessori MSI:n G66 Leopard -kannettavassa. Grafiikkasuorituskyvyssä ero on vielä dramaattisempi. Applen mukaan M1 Pron GPU kuluttaa 70 % vähemmän tehoa, kuin GeForce RTX 3050 Ti Lenovon Legion 5 -sarjan kannettavassa, tarjoten kuitenkin samalla aavistuksen parempaa suorituskykyä.
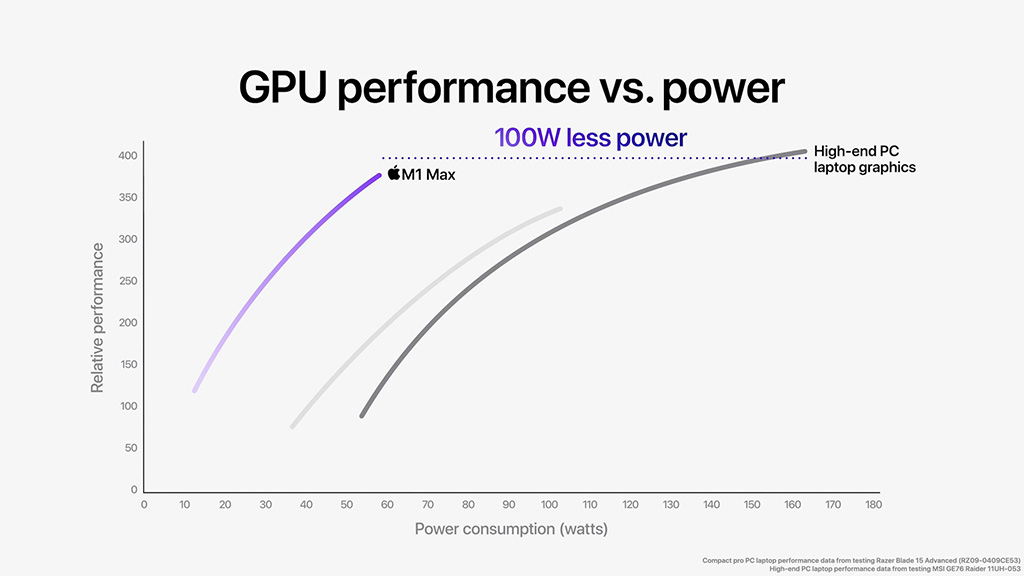
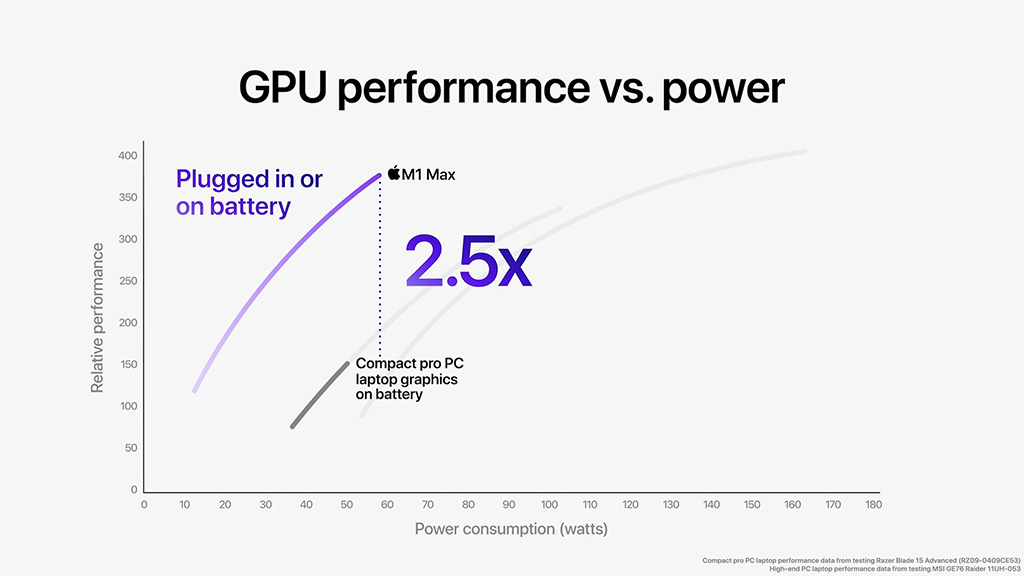
M1 Maxin taas kerrotaan tarjoavan parempaa suorituskykyä kuin GeForce RTX 3080:n mobiiliversion Razer Blade 15 Advancedissa ja lähes yhtä hyvää kuin sama näytönohjain MSI:n GE76 Raiderissa kuluttaen samalla 100 wattia vähemmän tehoa. Akun varassa M1 Maxin suorituskyvyn luvataan olevan 2,5-kertainen Razerin RTX 3080:iin verrattuna.
Uudet järjestelmäpiirit tulevat ainakin ensimmäisenä käyttöön uusissa 14- ja 16-tuumaisissa MacBook Pro -sarjan kannettavissa. Järjestelmäpiireistä tulee saataville myös ydinmääriltään karsittuja malleja täydentämään valikoimaa.
Lähde: Apple
Olisi kiva nähdä vertailu kovimpaan Xeoniin ja Alder Lake prossuihin.
Myös AMD:n lippulaivaa vastaan.
Tiedän. M1 riittää minulle, mutta teho on tehoa. Sitä ei koskaan ole liikaa.
Voiko arvioida miten tehokas tuo M1 Max -piiri on jos sitä vertaa esim 11900K / AMD 5900X / 5950X. Jos M1 Max on 100% niin paljonko nuo huippu pöytäkoneen prossut ovat? 140%, 180% tms?
Hankala hahmottaa kun ei niin tarkasti seuraa.
McBook M1 Max piirillä tais olla selkeesti tehokkain + virtapihein kannettava. Ja Apple tehoasemissa olikin sitten Intelin XEON yms. sisuksissa (?).
Tiedot varauksella, tarkemmat sitten kun alkaa vahvistettuja virallisia tulemaan, mutta Geekbenchin mukaan verrattuna nyt vaikka 5900x. Hyvältähän se vaikuttaa, mutta muitakin testejä odotellessa.
Ja toistaiseksi Mac Pro tulee Xeon W:llä, mutta eiköhän nuokin jo ensivuonna siirry Applen omiin siruihin. Kuten varmasti vielä päivittämätön iMac 27":nenkin.
Single-core: Multi-core:
M1 Max 1749 pts M1 Max 11 542 pts
5900x 1670 pts 5900x 14 094 pts
Yllättävän hyvin suoriutuu.
GPU puolella taitaa laahata sitten, jos RX 6900 / 3080Ti / 3090 vertaa pöytäkonemalleihin niin taideta olla likimainkaan. Mutta tuollainen M1 sirulla varustettu MacBook on siis tehokas laite jo ihan pöytäkoneisiin nähden myös.
M1: 1750@single 7500@multi
Eli M1 nähden sama singlecore ja noin 50% korotus multicore perffiin. Ei nyt ihan vastaan Applen kalvojen hypeä ja kertoimia, mutta onhan toi aivan poikkeuksellinen peto läppäriksi ja kilpailee käytännössä highend pöytäkoneiden kanssa.
Ei taida PC-puolelta löytyä mitään vastaavaa. Tiger Lake-U kuulemma tukee periaatteessa 128-bittistä LPDDR5-5400-muistia, mutta markkinoilla on toistaiseksi vain LPDDR4X-ratkaisuja, ja muistikaista on tietysti kapeampi.
Yksi etu tuosta integroidusta gpu:sta on, että sama keskusmuisti jaetaan gpu:n ja cpu:n kesken. Jos jokin ohjelma haluaa jakaa työtä cpu/gpu välillä niin dataa ei tarvi pallotella ees+taas. Toivottavasti amd/intel seuraa perästä ja tekee samankaltaisen järeän APU:n peliläppäreihin. Mulle riittäisi tuollainen 10tflops integroitu ps5/xbox tason APU peliläppäriin. DGPU on monella tapaa ärsyttävä läppärikäytössä vaikka hybrid moodi joitain ärsyttävyyksiä korjaakub(joskin suorituskyky huononee).
Alder Lakeissa ja AMDn seuraavan sukupolven mobiiliprossussa tulee ainakin olemaan LPDDR5-tuki, samoin Valven Steam Deckin AMD-prossu käyttää nimenomaan LPDDR5:ttä
Joudutaan odottamaan arvosteluja tuon suhteen. Videoeditointi todennäköisesti menee isoilta osin rautakiihdytetysti eikä pelkästään cpu:lla. Alla yhden vakavastiotettavan sisällöntuottajan mielipide applen julkaisusta + referoi applen materiaalia mukavasti mielipiteen tueksi
Linkissä perus m1:sta benchmarkkia versus intel apple. Iso osa tuota m1:sta on lämmöntuotto, kone ei ala throttlettamaan pidemmänkään renderöinnin aikana/akku kestää. Mielenkiintoista nähdä miten m1 pro ja max suoriutuvat ja onko softatuki parantunut keväästä.
Tests Showed Premiere Pro Almost 80% Faster on M1 Compared to Intel – Y.M.Cinema – News & Insights on Digital Cinema
ymcinema.com
Taas kuten aina, niin teoriassa luvut näyttää nätiltä paperilla mutta kun siirrytään toteutus puolelle, niin Applella ei tällä hetkellä ole vielä optimointi puoli kunnossa. Parin vuoden päästä tilanne saattaa tosin olla aivan toisin.
Hienoa mutua
Se, että Applella CPU ja. GPU käyttää yhteistä muistia tarkoittaa nimenomaan sitä, että GPUta voi OIKEASTI käyttää vaikka minkä rinnakkaislaskennan kiihdyttämiseen, ilman pahoja datansiirto-overheadeja jotka erillisnäyttiksellä tulisi.
Että tositilanne menee nimenomaan applella suhteessa paremmin kuin teoreettiset luvut.
Mielenkiitoista. Näyttää Applella olevan pullat hyvin uunissa. Lisäksi muistikaistaa CPU:lle on hirveästi, yli 10–20 kertaa enemmän mitä PC:llä DDR4:ssa. Se on eri asia, että mitä käytännön merkitystä tällä on, mutta yhdellä suoirtuskykyisellä kannettavalla voi tehdä vaativat työt telakoituna multimonotor setuppiin tai mobiilisti.
Siellä on kans lisää näyttöjen io kamaa, lisää cachea ja jotain videokiihdyttimiä. Tiedä sitten että mikä osa noistakin on käytössä vs. vain parantamassa saantoja.
Anandtechin mukaan siellä on myös oletettavasti 16MB per muistiohjain cachea eli 64MB yhteensä. Jos toi pitää paikkansa niin ei ole pelkästään hyvä muistikaista vaan myös infinity cachea vastaava cachetus olemassa(slc-palikat kuvasta).
Apple Announces M1 Pro & M1 Max: Giant New Arm SoCs with All-Out Performance
http://www.anandtech.com
Ja sitten odottelemaan Reddit kuvia kun jengi farmaa näilläkin kryptokolikoita.
Teknisesti varmasti mahdollista, mutta tuskin kovin kustannustehokasta, jos ei teholäppärille ole muuten käyttöä.
Satunnaisen lähteen mukaan m1 Max:ssa pinta-alaa on n. 432 mm^2.
Tästä n. 80% on joko CPUta tai GPUta, eli sellaista, jonka koko oltaisiisin tuplaamassa.
Tarkoittaisi melkein 800mm^2 pinta-alaa pienemmälle ja melkein 1500m^2 pinta-alaa suuremmalle mallille.
Apple siirtynee ensi vuonna TSMCn "4nm" valmistustekniikkaan mutta se on vain "5nm" tekniikan viilausta, ei uusi oikeasti pienempi prosessi.
Vajaat 800m^2 on koko joka olisi kyllä mahdollista tehdä yhtenä piirinä mutta hinta ja saannot olisi aika kauhea. Ei mahdoton, muttei todennäköinen.
Melkein 1500m^2 olisi sitten aivan liikaa yhdelle piilastulle, vaikka se joku tekoälystartup paljon isompaakin hypettää.
Oma veikkaus on ehkä symmetrinen MCM (NUMA), kaksi tai neljä M1 Max-kokoluokan piilastua, joista jokaisella sitten omat muistipinonsa, ja piirien välinen kytkentä ei perinteisillä paketoinnin kytkentämekanismeilla vaan jotain nopeampaa, alla joko iso interposer tai sitten jotain EMIBin kaltaista.
Montaa sokettia halutaan välttää piilastujen välisen kaistan takia, Apple haluaa enemmän kaistaa ja vähemmän viivettä nodejen välille kuin mitä sokettien välillä olisi saatavissa.
MCMssä tosiaan tulee aina vastaan kysymys, että symmetrinen vai asymmetrinen (UMA vai NUMA).
Asymmetrinen/NUMA (kuten zen2/zen3) tarkoittaa sitä,
1) että kaikki liikenne kiertää muistiohjainpiirin kautta, eli kaikelle liikenteelle tulee aina viive (ja virrankulutus) piilastulta toiselle menevästä liikenteestä
2) yhdelle keskitetylle muistiohjainpiirille on vaikea saada paljon kaistaa
3) muistiviiveet on pituudeltaan deterministisempiä eikä tule odottamattomia "oho, väärä muisti"-viiveitä.
4) muistiohjaimet ja muut IO-ohjaimet joilla on isoja PHYitä voidaan tehdä vanhemmalle (halvemmalla) valmistustekniikalla
5) systeemi on modulaarinen, kumpi tahansa, laskentapiilastu tai IO-piilastu voidaan vaihtaa uudentyyppiseen vaihtamatta toista, jos vaan väylä pysyy ennallaan (zen2 => zen3)
Symmetrinen(NUMA) taas tarkoittaa sitä, että
1) osa muistiaccesseista tapahtuu omaan muistiin, ilman piilastujen välisen liikenteen viiveitä ja virrankulutusta
2) keskimäärin kaistaa saadaan enemmän
3) välillä hommat voi hidastua odottamattomasti väärää muistia käyttäessä, ja jonkun yksittäisen piirin muistiohjain ja siihen kytketyt väylät voi pahimmassa tilanteessa kuormittua pahemmin (koska osoitteet on jaettu eri muistikanaviin yleensä eri logiikalla)
4) Kaikki pitää valmistaa samalla (uudella, kalliilla) valmistustekniikalla
Molemmissa ratkaisussa mahdollinen memory side cache-periaattella toimiva uloimman tason välimuisti on siellä missä muistiohjain, eli accessit siihen menee potentiaalisesti (hitaan ja virtasyöpön) piilastujen välisn linkin yli.
Ja tämä taas voi motivoida lisäämään välimuistia sinne lähemmäs laskentayksiköitä, eli tuomaan esim. yhden välimuistitason lisää tähän väliin.
Applen perfektionismin tuntien ymmärtää sen, että M1 Max on vielä monoliittipiiri, jolloin näitä asioita ei tarvi murehtia, maksetaan vaan TSMClle siitä isosta piiristä ja kärsitään sitten jonkun verran huonommista saannoista.
Luonnollista, että mahdolliset MCM-piriit halutaan tuoda markkinoille viimeisenä, jotta esim käyttiksen ja applen omien softien NUMA-tuki saadaan mahdollisimman hyvään kuntoon jos tuleva piiri on NUMA. Ja jos piirille halutaan joka tapauksessa uusi piilastujen välinen väylätyyppi lisää ja ehkä yksi välimuistitaso lisää, ymmärtää että erilaisen järjestelmäarkkitehuurin sisältävä piiri saadaan kehietttyä valmiiksi viimeisenä