
Tekoäly ja koneoppiminen ovat olleet viime aikoina liki kaikkien prosessorivalmistajien huulilla. Nyt mukaan on liittymässä Fujitsu, joka tunnetaan prosessoripiireissä lähinnä supertietokoneisiin ja palvelimiin suunnatuista SPARC-prosessoreistaan.
Top500.org-sivustolla julkaistun artikkelin mukaan Fujitsu kehittää parhaillaan DLU- eli Deep Learning Unit -prosessoria, joka on suunnattu yksinomaan tekoäly- ja koneoppimistehtäviin. Fujitsu on asettanut DLU-prosessorin tavoitteeksi kymmenkertaisen suorituskyvyn wattia kohden kilpailijoiden piireihin nähden.
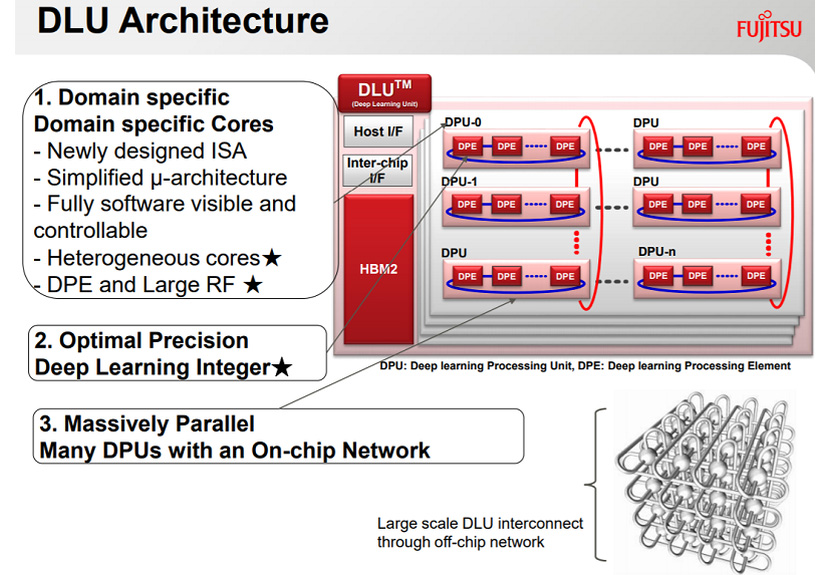
DLU-piiri tukee natiivisti FP32-, FP16-, INT16- ja INT8-tarkkuuksia. Fujitsun mukaan INT8- ja INT16-tarkkuudet ovat riittäviä moniin syväoppimistehtäviin ja niiden käyttö puolestaan kuluttaa vähemmän energiaa kuin FP16- tai FP32-tarkkuuksien.
Deep Learning Unit -prosessori on arkkitehtuuriltaan heterogeeninen. Se hyödyntää yhtä tai useampaa ”Master”-ydintä, jotka hallitsevat laskentatehtäviä suorittavia DPU-yksiköitä (Deep learning Processing Unit). Kukin DPU-yksikkö rakentuu kuudestatoista DPE- eli Deep learning Processing Element -yksiköstä. Dataa suoritusyksiköille syötetään samalle hartsialustalle integroidusta HBM2-muistista. Deep Learning Unit tukee Fujitsun Tofu-väylää, joka mahdollistaa useampien piirien yhdistämisen toisiinsa.
Fujitsun tämän hetkisten suunnitelmien mukaan ensimmäisen sukupolven Deep Learning Unit -prosessorit julkaistaan yhtiön seuraavan fiskaalivuoden aikana. Ne tulevat toimimaan apuprosessoreina yhtiön SPARC-prosessoreiden rinnalla. Toisen sukupolven DLU-prosessorit on tarkoitus integroida suoraan osaksi muita prosessoreita.
Lähteet: Top500.org, Guru3D
Lähinnä taitaa siis kilpailla Nvidian kanssa?
Meinaakohan 10 kertaisella erolla Vs edellinen sukupolvi? Nykyinen sukupolvi on kuitenkin senverran uusi, jotta lie ollut hankala keretä testata / arvioida..
Tietysti aina on helpompi tehdä "erikoispiiri" GPU on kuitenkin enemmän "yleiskäyttöinen", vs tuo.
Vain Google on aikaisemmin kehitttänyt prosessorin nimenomaan tähän käyttötarkoitukseen, Nvidialla on tuotteita tähän käyttötarkoitukseen mutta nekin on pohjimmiltaan Nvidian GPU ytimiin perustuvia pienellä lisä ytmellä varustettuna niitä ei ole alusta-alkaen kehitety juuri tähän käytöön, eli Fujitsu on esimmäin joka kehittää prosessorin juuri tähän käyttöön ja tulee ilmeisti myymään sitä prosessoriaan vapaasti (Googlen prossu on vain Googlen käytössä).
Top500 linkissä kerrotaan noista kilpailijoista enemmän, eli nVidia dominoi vahvasti. Tuo 10x suorituskyky wattia kohden, verrataan varmaankin tuohon K-tietsikkaan. On aika selvää että päästään helposti ihan eri suorituskykyyn kun kyseessä on täysin eri arkkitehtuuri, vanha CPU jää rinnalle.
NVIDIAn, AMD:n, Intelin ja Googlen nyt ainakin
Nvidiallahan on "erikoisyksikköjä" tuota ajatellen uusimmassa GPU:ssa (ammattilaisversiossa) käsittääkseni, jotka nostivat suorituskykyä reippaasti.
Mites AMD, Intel ja Google minkäslaisia ratkaisuja niillä on tuohon?
Erikoisyksiköitä ei taida AMD:lla olla, mutta tuki kaikenmoisille laskuille, myös niille tensoreille, löytyy.
Intelillä ei taida myöskään olla erikoisyksiköitä, mutta on mahdollisuus pistää FPGA-piirejä mukaan.
Googlella on nimenomaan Tensor-laskuihin erikoistuneita piirejä (ts. samoihin laskuihin mihin ne GV100:n uudet Tensor-coret on), nyt mennään jo 2. sukupolven piirissä vissiin
Onkos noista Googlen piireistä mitään parempaa dataa?
Building an AI Chip Saved Google From Building a Dozen New Data Centers
An in-depth look at Google’s first Tensor Processing Unit (TPU) | Google Cloud Big Data and Machine Learning Blog | Google Cloud Platform
Elikkä tuossa on siis useampi taho jo hyvin pitkällä..
Sehän on täysin selvää, että GPU ei pysty kilpailemaan tuollaiselle ratkaisulle, joka on erikoistettu (hmmm. onko tämä oikea sana) tuohon hommaan.
GPU:n kilpailukyky riippuu tietysti osittain siitä, jos tarvitaan lisäksi muita, kuin tuollaisia suuria matriisi operaatioita kohtuu suuria määriä (100-10000 rinnakkaista) noissa sovellutuksissa..
Jos ei tarvita, niin GPU:t tippuvat täysin tuosta kilpailusta ja Nvidia, jos aikoo jatkaa joutuu erottamaan GPU:n ja kutsutaan tuota nyt sitten TPU:ksi (kuten artikkelissa) täysin toisistaan tai joutuu luopumaan leikistä. Nythän nuo ovat jo kohtuudella erillään.. Tuskimpa näyttiksiin tulee tensori yksiköitä, koska sehän ilmeisesti olisi GPU:ssa lähinnä piitilan tuhlausta (mutu)? GPU puolella olisi tosin kiva, jos kävisivät kehittelemään GPU:ita s.e. raytracing toimisi, kuten nykyiset menetelmät. Ainankin ekalla titanilla Nvidian demo raytracing peliengine oli ihan liian hidas..
Tietysti GPU:t ovat hyviä kaikessa muussa laskennassa, johon tuollainen erikoisratkaisu ei taivu tai joihin ei ole muuta erikoisratkaisua (vielä).
Tosin Nvidia otti viimeisessä sukupolvessaan voimakkaan askelen samaan suuntaan, lisäämällä GPU:hun tensoriyksiköt. Jos fujitsu vertasi mainosmateriaalissaan edelliseen sukupolveen, ja varsinkin jos laskennassa tarvitaan muunkintyyppistä rinnakkaista suoritusta, niin Nvidian GPU voi silti olla vahvoilla.. Jos taas laskennassa tarvitaan vain noita matriisilasku yksiköitä ja loppu on hyvin yksinkertaista, ei rinnakkaistuvaa suoritusta, niin GPU:ssa onkin sitten hukattu paljon piipinta-alaa ja Fujitsun normi prossu siinä kaverina on kokonaissuorituskykyisempi ratkaisu. Lisäksi on tietysti jonkinverran ensialkuun myös se, kumpi tarjoaa paremmat työkalut ja tuen.
—————–
Kannattaakohan noissa muuten tehdä mahdollisimman nopea "yksikerrosleipä", joka laskee esim 100000 toimitusta vai vähemmän virtaa kuluttavalla tekniikalla, pienemmillä kelloilla pino esim 50000 toimitusta laskevia yksiköitä, joita on sitten vaikka 4 kerrosta? Kerroksien lisäyshän loppuu, kun huonosti lämpöä johtava pii ylikuumenee siellä jossain vaiheessa..
DeepMind’s AI became a superhuman chess player in a few hours, just for fun
Uskomatonta kuinka paljon tietoa nuo voi käsitellä ja yhdistää…