
NVIDIA on koetellut viimeisimmillä laskentasiruillaan TSMC:n tuotantoprosessien rajoja. Uusi 7 nanometrin prosessilla valmistettu A100 rakentuu 54,2 miljardista transistorista ja on kooltaan 826 neliömilliä.
Isolle yleisölle epäilemättä tuntematon Graphcore on nyt lyönyt uuden vaihteen silmään ja julkaissut tekoälylaskentaan suunnitellun Colossus Mk2 GC200 IPU:n (Intelligence Processing Unit). Se rakentuu 59,4 miljardista transistorista, mitkä on saatu ahdettua hieman A100:aa pienempään tilaan 823 neliömillin alalle. Myös Graphcore käyttää TSMC:n 7 nanometrin valmistusprosessia.
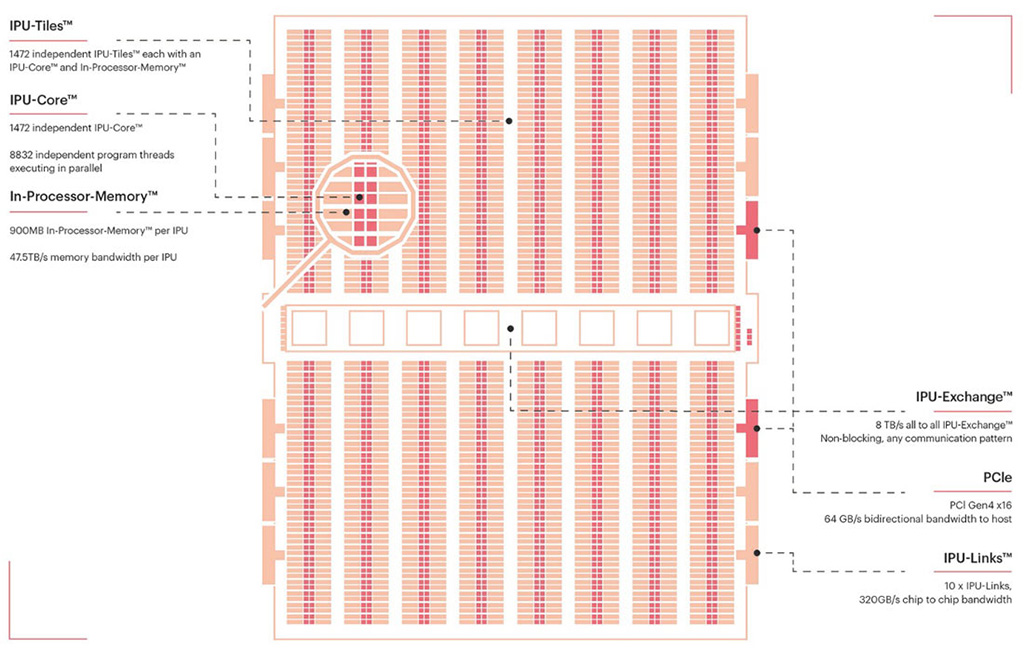
GC200 on sisällä jaettu 1472 erilliseen IPU-ytimeen, jotka kykenevät suorittamaan samanaikaisesti 8832 rinnakkaista säiettä. IPU-ydinten tukena on yhteensä 900 Mt sirun sisäistä muistia ja kullakin IPU:lla on omaan muistilohkoonsa 47,5 Tt/s:n kaista. Tekoälyprosessorissa hyödynnetään Graphcoren omaa AI-Float-teknologiaa, minkä se kehuu mahdollistavan peräti petaFLOPSin laskentatehon 1U-kokoluokan korttipalvelimessa (blade) neljän sirun voimin.
Valitettavasti Graphcore ei kerro tarkkaan, minkälaisia tarkkuuksia se todellisuudessa tukee. Yhtiö mainostaa tukea IEEE-standardille FP32-formaatille, minkä lisäksi tuettuina ovat FP16.32 (16-bittinen kertolasku, 32-bittinen summaus) ja FP16.16 (16-bittinen kertolasku ja summaus). Lisäksi sirut tukevat stokastista pyöristystä, minkä avulla kaikki aritmetiikka voidaan pitää 16-bittisenä uhraamatta tulosten tarkkuutta.
Suorituskyvystä Graphcore on paljastaonut sen verran, että EfficientNet-B4 kuvan luokittelu opetuksessa kahdeksan IPU-M2000 1U-korttipalvelinta paketti vastaa suorituskyvyltään peräti 16 NVIDIA DGX A100 6U-palvelinta murto-osalla niiden hinnasta. Yksi IPU-M200-korttipalvelin sisältää neljä Colossus Mk2 GC200 IPUa.
No huhhuh. 8832:1472=6, eli kuusi säiettä per ydin.
Ei vaan yhteensä 900 megatavua, eli alle megatavu per ydin. Toi on vähän hämäävä kun kaikki on IPU sitä IPU tätä.
Ostaminen on toki ihan hieno teko. Jälkimmäinen on sitten käytännössä oikeuden vääntämistä omaksi hyväksi loputtoman lakimiesarmeijan kanssa, kuten Nvidia ja Intel yleensä tekee.
Voi tosin olla että kannattajakunta kaikkoaa tuollaisesta touhusta, kun saa rottailijan maineen.
Hyvinkin monet firmat tuota tekevät. Esim 3D tulostus on pysähtynyt patenttiviritysten takia "kivikaudelle".
Ja älä huoli, myös esim AMD tuota tekisi, jos sille vain tulisi tilaisuus, missä se hyötyisi siitä ja pystyisi kiristämään kilpailijoita.
Jos joku pikkufirma tekee jonkun tuotteen, jolla on potentiaalia, niin se kannattaa hoitaa vielä, kun se on halpaa ja yleensä kilpailuviranomaisetkaan eivät moiseen puutu.
Kuten teki vaikka Mantlen ja Freesyncin kanssa.
AMD ei ole kyllä paljoa lakifirman kautta hoitanut voittoja itselleen. Epäsuorasti tosin AMD on hyötynyt esim. Aikanaan intelin kartelli sakoista.
Mitenkä Freesync tähän liittyy? Sehän perustuu avoimeen standardiin jolle Nvidiakin koodaa omat ajurinsa. Mantle taasen tunnetaan nykyään nimellä Vulkan, joka on myös avoin standardi kaikille.
Mantlessa oli samoja ominaisuuksia kuin DX12:ssa, jolla oli siis tarkoitus kaventaa pullonkauloja CPU:lta ja GPU:lta. Esim. Nykyisissä konsoleissa on jo sisäänrakennettu tuki Mantle:lle.
AMD ei missään vaiheessa kieltänyt Nvidiaa hyödyntämästä Mantle:a, vaan Nvidia kieltäytyi siitä avoimesti.
Se avoin standardi perustuu AMD:n ehdotukselle avoimesta standardista (ts AMD sanoi VESAlle että tää ois kiva ja oikeestaan tää speksi vähän niinku mahdollistaakin sen jo > VESA julkaisee Adaptive-syncin ja AMD markkinoi FreeSyncinä)
Juu ja Nvidia tekee erillisen piirin kyseiselle sync-toiminnolle, vaikka se on useissa näytöissä periaatteessa ollut sisäänrakennettuna jos jossain muodossa.
AMD siis oman käsityksen mukaan otti vain tuon standardin käyttöön vähän kuin vastavetona Nvidian rahastus g-syncille.
G-sync Ultimate näytöt onkin sitten kumman kalliita, vaikka koko toiminnolle ei etenkään uudemmissa näytöissä ole oikeastaan enää mitää tarvettakaan. Syncit päällä moni muu peliominaisuus disabloituu, jolloin hyöty on pyöreät 0.
Se on syytä huomioida, että Nvidian ratkaisu toimi selkeästi freesyncciä paremmin, hyvinkin pitkään. Siinä vaiheessa, kun freesync kävi lopulta toimimaan yhtähyvin, Nvidia kävi avaamaan tukea myös hyvin toimiville FS näytöille.
Ja mitä mantleen / freesyncciin tulee, niin eipä AMD:n:llä ollut vara tehdä niiden kanssa, muuta, kuin se teki. DX12 olisi tullut jokatapauksessa ja jos AMD olisi kitsastellut mantlen kanssa yhtään, niin sitä ei olisi tukenut tasan kukaan. Samoin olisi ollut FS:n kanssa.
Muistelisin muuten, että jonkinlainen adaptive sync oli jokatapauksessa tulossa silloin aikoinaan, AMD vain lähinnä joudutti sitä / sen käyttöönottoa.
Juu toimi, mutta jos vertaa nykyistä g-sync 2.0 edelliseen, niin ollaan milteinpä menty takapakkia. Kaveri joutui palauttamaan tällaisen näytön, kun paljastui että g-sync piirin takia oli pari erittäin kovaäänistä huuvaa näytön takana jäähdyttämässä kyseistä piiriä.
Itse tein kompromissin sitten ja hankin freesync 2 näytön, mutta toistaiseksi olen todennut että tarvetta ei ainakaan 240Hz näytöllä low input lag ja response time (fastest MBR) asetuksilla ole moiselle.
Kaikki Nvidian jälkeenpäin g-sync verifoimat näytöt ei kyllä performoi ollenkaan, tai todella huonosti taasen.
Gsync piirihän ei aluksi toiminut lainkaan 2d moodissa ainakaan ensimmäisellä versionumerolla. 2.0:sta en ole edelleenkään varma, mutta pelitarkoitukseen sitä on ainakin markkinoitu.
Molemmat ovat AMD:n tekemiä?
Mukava kyllä nähdä uusia kilpailijoita markkinoilla. Toivottavasti joku iso möhkö ei vaan syö tuota heti pois kuljeksimasta.