
NVIDIA pitää parhaillaan GPU Technology Conference- eli GTC-tapahtumaansa. Osana tekoälyyn ja palvelimiin keskittyvää tapahtumaa yhtiön nahkatakkinen toimitusjohtaja Jensen Huang esitteli myös uuden Hopper-arkkitehtuurin.
Hopper on NVIDIAn uusi palvelin- ja supertietokonekäyttöön suunnattu ns. HPC-arkkitehtuuri. Arkkitehtuurin kruununjalokivi on GH100-piiri ja siitä jalostettu H100-kiihdytin. GH100 valmistetaan TSMC:n 5 nanometrin luokkaan kuuluvalla NVIDIAlle kustomoidulla 4N-prosessilla ja se rakentuu yhteensä jopa 80 miljardista transistorista. Piirin pinta-ala on 814 mm2.
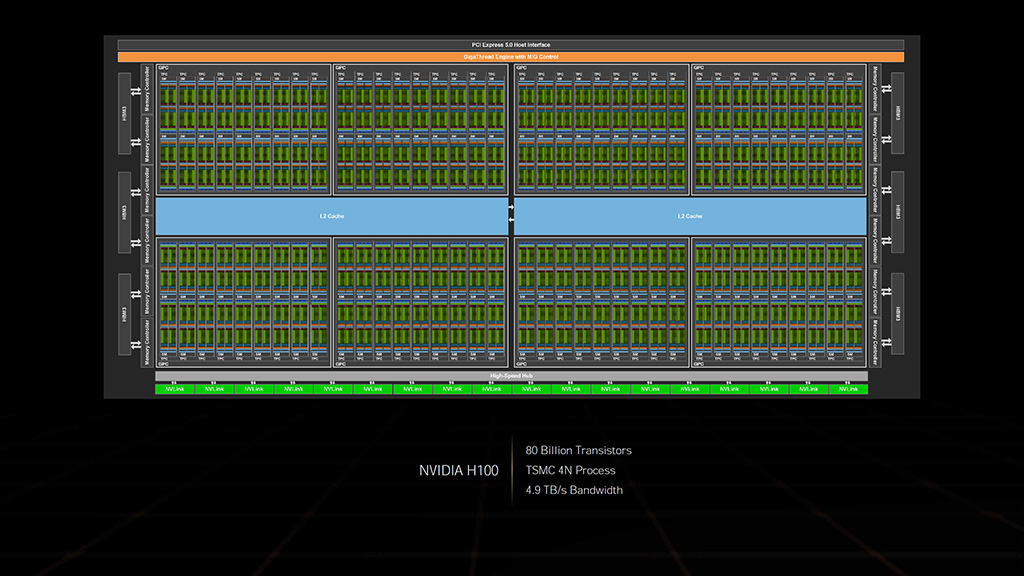
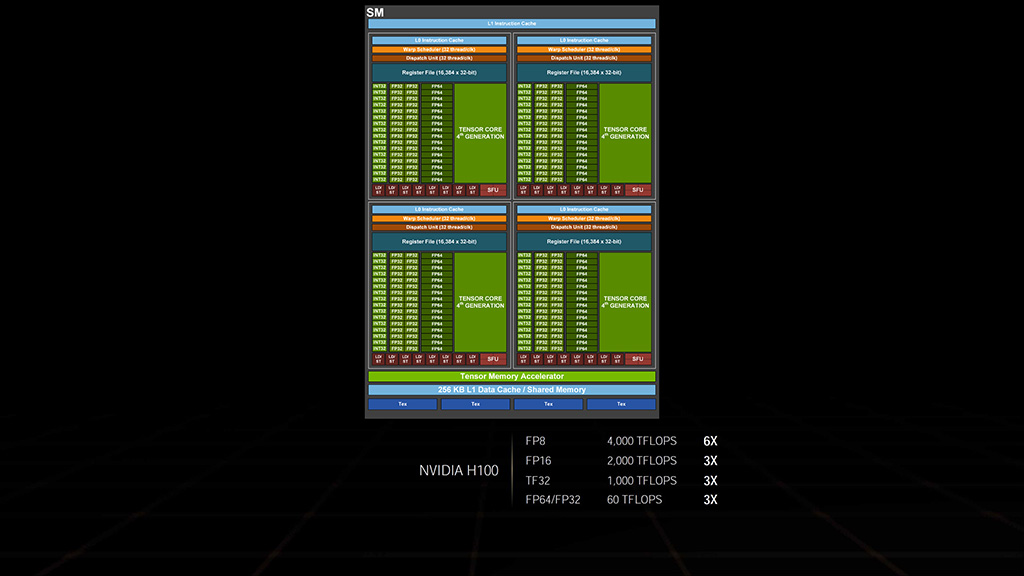
GH100 sisältää yhteensä 8 GPC-yksikköä, 72 TPC-yksikköä tai 144 SM-yksikköä. SM-yksiköissä on 128 FP32 CUDA-ydintä, 64 INT32-ydintä ja 64 FP64-ydintä, jolloin koko piirissä on yhteensä 18 432 CUDA-ydintä. Uusia 4. sukupolven tensoriytimiä on neljä per SM-yksikkö eli yhteensä 576. Tensoriyksiköitä on lisäksi tukemassa uusi Transformer Engine, joka on suunniteltu nopeuttamaan tekoälytehtäviä large language -malleilla. Muistipuolella on käytössä 60 Mt L2-välimuistia ja kaksitoista 512-bittistä muistiohjainta, jotka ohjaavat maksimissaan kuutta HBM3- tai HBM2e-muistipinoa. Ulkopuolisesta kommunikaatiosta on vastuussa 4. sukupolven NVLink ja PCI Express 5.0. NVIDIA on eriyttämässä laskentapiirejään entisestään grafiikkapuolesta ja nyt vain kaksi TPC-yksiköistä tukee grafiikkatehtäviä, kuten pikseli-, verteksi ja geometriavarjostimia.
Täyden piirin konfiguraatiota ei kuitenkaan tulla näkemään ainakaan toistaiseksi tositoimissa, vaan markkinoille tulevat aluksi H100 SXM5 132 SM-yksiköllä eli 16 896 CUDA-ytimellä sekä H100 PCIe Gen 5 114 SM-yksiköllä eli 14 592 CUDA-ytimellä. Huomionarvoisesti PCIe-versiossa on käytössä 7 tai 8 GPC-yksikköä riippuen siitä, mitkä SM-yksiköt on poistettu käytöstä. Kummankin mallin tapauksessa on lisäksi poistettu kaksi muistiohjainta ja sen myötä yksi muistipino sekä 10 Mt L2-välimuistia käytöstä. Paketointiin asennetaan kuitenkin ns. dummy-piiri puuttuvan HBM-pinon paikalle. SXM5-mallissa on käytössä 80 Gt HBM3-muistia ja PCIe Gen 5 -versiossa 80 Gt HBM2e-muistia. SXM5-mallin TDP-arvo on 700 wattia ja PCIe-version puolet siitä eli 350 wattia.
Vaikka NVIDIA mainosti tiettyjä suorituskykylukemia, se painottaa whitepaper-julkaisussa että kyse on arvioista eivätkä ne välttämättä vastaa lopullisia tuotteita. Ainakin kellotaajuudet ovat vielä osittain ilmassa, vaikka muutoin mallien tekniset ominaisuudet onkin tiedossa. Mikäli NVIDIAn tämänhetkiset arviot pitävät kutinsa, H100 SXM5 toimisi noin 1,78 GHz:n kellotaajuudella ja se yltäisi 30 FP64 TFLOPSiin, 60 FP32 TFLOPSiin tai 120 FP16 TFLOPSiin. Uuden sukupolven tensoriytimet yltävät TF32-tarkkuudella 500 TFLOPSiin, FP16-tarkkuudella 1 PFLOPSiin ja uudella FP8-tarkkuudella 2 PFLOPSiin. Sparsity-ominaisuutta tukevilla neuroverkoilla tensoriydinten suorituskyky on kaksinkertaista. Kuuluisaa toimitusjohtajamatematiikkaa käyttämällä NVIDIA on laskenut H100:n olevan 6 kertaa nopeampi, kuin A100.
H100 ja siihen perustuvat uudet DGC- ja HGX-supertietokonenoodit tulevat saataville vuoden kolmannen neljänneksen aikana.
Lähde: NVIDIA GTC
Epäreilua siis esim 6x nopeutus käytettäessä fp8 formaattia, jota ei amperesta löytynyt. Toinen "epäreilu" vertaus oli 256gpu:n pod missä gpu:t on kytketty toisiinsa nvlinkin läpi versus perinteinen verkkoinfra.
Q3:lle oli hopperia luvattu toimituksiin.
Samaisessa gtc keynotessa mainittiin automotive puolesta. Mersun autot ovat edelleen tulossa 2024 nvidian piirillä+softalla ja jaguar land rover seuraa perästä 2025.
Nvidian gtc-esitykset näkee ilmaiseksi, mutta vaatii rekisteröitymisen. Katsoin noita huvin vuoksi eilen muutaman session. Hopper esitys meni ihan mukavasti yksityiskohtiin sen suhteen mitä uutta ohjelmoihan näkökulmasta raudassa on. Paljon on hopperissa parannusta sen suhten miten saadaan tiristettyä parempaa tehoa irti raudasta ilman, että skaalataan pelkkiä flopseja ylöspäin.
GTC 2022: #1 AI Conference
http://www.nvidia.com