
NVIDIA julkaisi viime yönä SIGGRAPH-messuilla uuden Turing-arkkitehtuurin ja esitteli ensimmäisen siihen perustuvan, toistaiseksi nimettömän grafiikkapiirin. Uusi Turing-arkkitehtuuriin perustuva grafiikkapiiri tullaan näkemään Quadro-sarjassa vuoden viimeisellä neljänneksellä.
NVIDIAn uusi grafiikkapiiri on kooltaan 754 neliömillimetriä, mikä kertoo sen suuntaavan suoraan markkinoiden tehokkaimpaan ja kalleimpaan päätyyn. Transistoreja piirissä on peräti 18,6 miljardia ja grafiikkapiiri valmistetaan edelleen TSMC:n 12 nanometrin valmistusprosessilla. Grafiikkapiiri on varustettu 4608 CUDA-ytimellä, 384-bittisellä GDDR6-muistiväylällä, 576 Tensor-ytimellä ja täysin uudella säteenseurantalaskuihin keskittyvällä RT Core -yksiköllä. L2-muistia piirissä on 6 megatavua. NVLink-liitännän avulla näytönohjainten muistimäärä on periaatteessa kaksinkertaistettavissa ja näytönohjainten väliseen kommunikaatioon on varattu kaistaa 100 Gt/s. Samsung on ehtinyt jo ilmoittautua uusien Quadrojen GDDR6-muistien toimittajaksi.
Turing-grafiikkapiirin näyttöohjaimessa on odotetusti tuki hiljattain esitellylle VirtualLink-näyttöliittimelle. VirtualLinkin lisäksi ainakin Quadro-malleissa näyttöliittimiksi on valittu neljä DisplayPort-liitäntää, mutta toistaiseksi ei ole tiedossa onko tämä grafiikkapiirin määräämä ratkaisu, vain yksinkertaisesti valinta NVIDIAn toimesta.
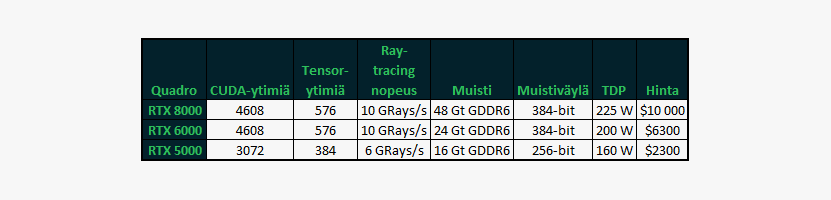
NVIDIAn mukaan markkinoille tullaan tuomaan kolme eri mallia, jotka perustuvat samaan grafiikkapiiriin: Quadro RTX 8000, RTX 6000 ja RTX 5000. Lippulaivamalli Quadro RTX 8000 on varustettu 48 gigatavulla GDDR6-muistia ja sen hinta on 10000 dollaria. Kokosimme oleellisimmat tiedossa olevat tekniset ominaisuudet yllä olevaan taulukkoon.
Nyt julkaistu arkkitehtuuri ja Quadro-näytönohjaimet nostivat pinnalle luultavasti enemmän kysymyksiä kuin vastauksia. Turing-arkkitehtuurin oli pitkään spekuloitu olevan nimenomaan pelikäyttöön suunnattu arkkitehtuuri, mutta ainakin ensimmäiset julkaistut näytönohjaimet ovat ammattikäyttöön suunnattuja. Erikoista on myös Turingin vertailu Voltan sijasta Pascal-arkkitehtuuriin, vaikka tämän hetken nopeimmat Quadrot perustuvat nimenomaan Voltaan ja GV100-grafiikkapiiriin.
NVIDIAn samaan syssyyn julkaisema kiusoitteluvideo viittaisi, että ensi viikolla julkaistavat GeForce-näytönohjaimet perustuisivat mahdollisesti samaan arkkitehtuuriin ja ne käyttäisivät NVIDIAn hiljattain rekisteröimää GeForce RTX -nimeä perinteisen GTX:n sijasta. Numeroinnin on vihjattu myös olevan 20-sarjaa eikä aiemmin kesällä esimerkiksi Lenovon vinkkaamaa 11-sarjaa. Samalla jää avoimeksi kysymys, mihin käyttöön useamman ohjelman viimeisimpien päivitysten listaamat GV102- ja GV104-grafiikkapiirit on tarkoitettu.
Mahdollisia selityksiä ristiriitaisuuksille on useita. Yksi spekuloitu mahdollisuus on GeForce RTX 20 -sarja aivan näytönohjainten terävimpään kärkeen, jonka alapuolelle sijoittuisivat Volta-arkkitehtuuriin perustuvat hieman hitaammat mallit perinteisemmällä GTX-nimellä – tämä teoria voisi tukea myös vertailua Voltan sijasta Pascal-arkkitehtuuriin. Toinen vaihtoehto on luonnollisesti koko GTX-sarjan vaihto RTX-sarjaksi ja virheelliset tiedot eri ohjelmien päivityksissä piirien koodinimistä. Lisää asiasta saamme kuulla 20. päivä, kun NVIDIA tulee esittelemään uudet GeForce-näytönohjaimet.
Uutinen tulee päivittymään illalla, jonka lisäksi julkaistaan katsaus itse arkkitehtuuriin ja mitä siitä tiedetään sekä ihmetellyä mikä tilanne on pelivehkeiden suhteen.
Vaikuttaisi siltä, että näistä RTX8000 ja RTX6000 sijoittuvat GV100:n alapuolelle, malliston toiseksi järein piiri, ja RTX4000 on sitten pienempi piiri.
Vaikka piiri on pienempi se on joka tavalla kovempi kuin GV100 poislukien muistikaista
Eli Turing tulikin sitten Quadroihin ja RTX-sarjaan vaikka huhut (IIRC) povailivat sitä GTX-sarjan arkkitehtuurin uudeksi nimeksi.
Paitsi se tuplatarkkuuslaskenta. Kellot tuohon 16Tflopsiin on 1,736GHz, eli kohtuu korkea boost lukema.
Tuplatarkkuudesta ei ole kerrottu käsittääkseni mitään, joten tuota johtopäätöstä ei voi vielä tehdä (vaikka toki se on todennäköistä)
Ei ole.
GV100ssa on 5120 shader-linjaa, tuossa "vain" 4608.
ROPien määrä on myös suurempi, 128 vs 96.
Muistiakin GV100ssa on järeimmässä mallissa enemmän, 32 GiB, tuossa järein malli 24 GiB.
Neuroverkkovääntöä tosin tässä uudessa voi monessa käytännön sovelluksessa olla enemmän, vaikka tensoriyksiköitä on vähemmän, koska uudet tensoriyksiköt pystyvät suurempaan nopeuteen pienillä lukutarkkuuksilla.
Muistia tuossa RTX8000 on kylläkin 48G
ROPien määrästä ei ole varmuutta. Olet oikeassa CUDA-ytimien määrästä, mutta sitä kompensoidaan korkeammilla kellotaajuuksilla niin että lopputulos on enemmän vääntöä kuin GV100ssa (FP32, muista tarkkuuksista ei varmuutta)
Myös tensoriytimistä irtoaa enemmän laskentavoimaa sillä vanhallakin tarkkuudella korkeampien kellojen vuoksi
Kuvassa RTX 4000, tekstissä RTX 5000..
En valitettavasti pääse korjaamaan taulukkoa ennen kuin joskus kahdeksan jälkeen
Toki näinkin, mutta nvidialla ei ole ollut kovinkaan tapana piilotella tietoa, mikä saisi heidän tuotteensa näyttämään paremmalta.
Uutista päivitetty aika rajulla kädellä. Arkkitehtuurisilmäys joutuu kuitenkin odottamaan vähän pidemmälle, koska esimerkiksi whitepaperia Turingista ei ole vielä julkaistu.
NVIDIA and RED Digital Cinema Solve 8K Bottleneck | NVIDIA Blog
Herättäkää kun ne mainostaa jotain mitä ei olisi tehty jo aiemmin, jopa NVIDIA ite on esitellyt kauan sitten 8K-editointia reaaliajassa, AMD samoin :facepalm:
"reaching greater than 24 frames per second using just a single-processor PC with one Quadro RTX GPU"
Tuo taitaa olla se jutun ydin.
Ei mitään uutta, molemmat esitteli vastaavaa jo vuosi sitten ellei ylikin
Niin siis pointtina tuossa oli se että aiemmin se star wars pätkä ajettiin 4xvolta quatrolla ja nyt nvidia väittää ajavansa saman yhdellä kortilla. Ei niinkään se että mimmosia CPU:ta koneessa on.
Öö? Tossa puhutaan reaaliaikaisesta 8K-videoeditoinnista eikä mistään Star Wars demon pyörittämisestä?
Nvidian strategiana näyttää olevan käyttää tämänhetkistä johtavaa markkina-asemaa tuomaan lisää ja lisää omia custom rajapintoja omaan kustom hardwareen jotka sitten lukitsevat asiakkaat heidän tuotteisiinsa jatkossakin. AMD:llä ja Intelillä voi olla aika kova ylämäki saada markkinaosuutta takaisin vaikka saisivat jotain kilpailukykyistä rautaa ulos.
Oiskohan tossa avainasanana RED matskun leikkaus fullresolla 8k:na, se on nimittäin suhteellisen raskasta kamaa.
"Working with leading camera maker RED Digital Cinema, Turing makes it possible for video editors and color graders to work with 8K footage in full resolution"
Mikä ihme ne asiakkaat lukitsee Nvidiaan jatkossa? RTX-tukea on tehty esim. Vulkanille (NVIDIA's Work On Adding Ray-Tracing To Vulkan – Phoronix) eikä ole kovin kummoinen homma kutsua toista säteenseurannan toteuttavaa rajapintaa siinä kohtaa kun kilpailijoilta on sellaista rautaa ulkona millä se säteenseuranta onnistuu järjellisellä nopeudella.
Tuo säteenseuranta kun ei tosiaan ole mikään uusi juttu, ja siihen on olemassa varmasti ties miten monta erilaista ratkaisua ja rajapintaa. Kyse on vaan siitä, millä nopeudella tuota onnistutaan tuottamaan, ja millä aikataululla se siihen kykenevä rauta on kuluttajien saatavilla riittävän huokeaan hintaan.
Näyttäisi olleen ainakin Radeon Pro SSG:llä REDinkin setit reaaliaikaisia keväästä lähtien
Noissa on vähän semmosta markkinointipöhinää. Tsekkaas Radeon pro ssg:n manuaali:
https://www.amd.com/Documents/radeon-pro-ssg-premiere-pro-cc-solution-guide.pdf
"At this stage of the workflow, typical users should be able to play back and edit using the R3D source clips at 1/4 preview resolution smoothly. This setting downsamples the preview resolution to 4K, in this case, to trade visual fidelity for playback performance. "
Eli tuo 8k pyöritetään 4k:na (ja aika moni näyttishän kykenee siihen). Radeon Pro SSG pystyy cachettamaan 180 sekuntia 8k matskua sulavaa playbackia varten.
Mutta se tosiaan on cachetusta, ei suoraa 8k realtime playbackkia.
Niin AMD demosi tuota hommaa jo vuosi sitten kuten @Kaotik mainitsi.
nVidia ilmeisesti tekee tuon jotenkin toisin, AMD:llä se raakavideo ajetaan sinne kortin SSD:lle jolloin siihen päästään suoremmin käsiksi, mielenkiintoista tuossa on että miten nVidia tuon on toteuttanut vai onko tuo 24G muistia sitten se avainsana että sinne saadaan riittävästi puskuroitua.
Se puskurointi tarkoittaa sitä että kama vaan rendataan pakkaamattomana nopealle levylle jolloin voi sitä pyörittää reaaliaikaisesti. Samaa metodia on käytetty iät ja ajat kun premierellä on rendattu matskua cachelevyille. Paras tapa on silti saada se playback vauhti realtimeen ilman että sitä rendausta tarttee suorittaa.
Se on se oikeastaan vähän markkinointikusetusta sanoa, että tämänkaltainen metodi:
"Select the sections of the timeline you wish to cache by using the ‘I’ and ‘O’ keys to set the Mark In and Mark Out points on the timeline. Ensure that the Program pane is still set to 1/4 resolution playback to retain real-time playback of the non-cached sections."
on jotenkin "oikeaa 8k playbackia" kun sitä se ei ole.
Niin, tuossa uutisessa puhutaan Nvidian itse tekemästä Vulcan extensionista joka tukee ainoastaan Nvidian omaa rautaa, ja jota he nähtävästi yrittävät tyrkyttää standardin pohjaksi. Jos standardi tehdään heidän oman API:n pohjalta se luonnollisesti antaa heille huomattavaa kilpailuetua.
Jos siitä tulee avoin standardi, ei siinä ole mitään ongelmaa. Eikä se kilpailuetu ole kuin hetkellisesti, ELLEI siihen standardiin tule jotain rajoituksia jotka selvästi liittyy nvidian raudan spekseihin tai tietorakenteita joita (vain) nvidia kiihdyttää raudalla.
Jos taas nvidia houkuttelee kaikki käyttämään omaa extensiotaan, EIKÄ siitä tule avaointa standardia, on siinä selvä ongelma.
Ja jos joku avoin standardi tulee, parempi se on tehdä yhden jo toimivaksi todetun rajapinnan pohjalta kuin alkaa tekemään täysin tyhjästä komiteatuotoksena. Komiteatuotoksiin helpommin tulee mukaan kaikkea typerää.
Vaikka standardista tulisi avoin niin kyllä Nvidia saa siitä aika huomattavaa hyötyä. Ensinnäkin heillä on jo API käytännössä valmiina siinä missä muut valmistajat joutuvat nyt väsäämään oman rajapinnan tuon standardin ja heidän oman toteutuksensa väliin. Tämän lisäksi Nvidia varmistaa että standardin speksit ovat mahdollisimman lähellä heidän omaa rautatoteutustaan, tuoden heille potentiaalisesti lisää etua.
Komiteatuotokset ovat toki usein sitä itseään, mutta joskus se on parempi vaihtoehto, kuin se että ylivoimaisessa markkina-asemassa oleva firma sanelee speksit puhtaasti omien tarpeidensa mukaan.
Hyötyä kyllä, mutta tämä hyöty ei ole muilta pois (ellei siihen tule mukaajn jotain selvästi nvidian rauta-spesifistä/sille optimoitua).
Ei standardeja pidä tehdä eri tavalla vain sen takia, että alettaisiin tasaamaan eri tahojen välisiä kilpailuetuja. Tasapäistäminen on loputon suo jossa vaan lopulta kaikki häviää.
Niin Vulkan olisi aika tyhjä API, ilman noita. Suurin piirtein kaikki VK_KHR_ extensionit ovat alun perin lähtöisin joltain itsenäiseltä vendorilta. Nvidia on alusta lähtien tarkoittanut tuosta tulevan multivendor extension ja vastaavan aika pitkälti microsoftin DXRää vulkanin puolella.
Jos asioita ei tehdä yhdessä (isot firmat eivät yleensä tee), niin aina on joku, joka keksii asian ensin. Nyt kun on yleinen, avoin standardi, niin jos ko ominaisuus todetaan hyväksi, niin muutkin toteuttavat sen.
Ja sinällään, jos ei ole patentein blokattu onnistuneesti, niin muut toteuttavat myös suljetut kikat omilla tavoillaan, jos ko asia on hyödyllinen.
Jos patenttikikkailu toimii, niin yleinen kehitys ottaa helposti takapakkia esim 10 vuotta. Esim 3D tulostuksessa on käynyt näin.
Taitaa näytönohjainmarkkinat olla senverran lähellä nollasummapeliä että sanoisin että yden osapuolen hyöty on lähes välttämättä muilta pois.
Ja en nyt tiedä mitä ajat tässä takaa. Onko mielestäsi siis hyvä asia jos Nvidian omia API:ja käytetään standardien pohjana ja näin maksimoidaan jo johtavassa asemassa olevan valmistajan kilpailuetu? Minun mielestäni standardit ovat parhaita kun ne kehitetään olemaan parhaita mahdollisia standardeja käyttäjän kannalta, sensijaan että niiden olemassaolon tarkoitus on myydä tietyn valmistajan rautaa.
Nyt ei ole yleistä avointa standardia (ellet puhu MS:n DXR:stä) vaan NVIDIA ehdottaa sen oman rajapinnan käyttämistä Vulkanissa "yleisenä standardina". Ennen kuin tuosta rajapinnasta tiedetään oikeasti enemmän on paha sanoa yhtään mitään siitä onko se edes muiden toteutettavissa
Jotenkin vaikea uskoa että nvidia olisi tekemässä mitään vapaaehtoisesti avoimeksi. Vähän kuin MS office XML formaatti on "avointa". Kyllä kyllä. On se avointa, mutta microsoftin omat office tuotteet ei sitä oikeaa versiota tue vaan tallentavat asiat vähän sinne päin. Aiheuttaa ongelmia muille jotka standardia noudattavat. MS itse taas mainostaa tietenkin tukevansa sitä "avointa" standardia, joka ei oikeasti olekkaan niin avointa. (Is DOCX really an open standard?)
En yhtään ihmettelisi että nvidia julkaisisi "avointa" standardia ja pelinkehittäjille helpot hyvät työkalut. Toisille näyttisvalmistajille sitten 10001 dokumentoimatonta virheellistä tietoa jota sitten "korjaillaan" ajan saatossa. Sitten joskus monta vuotta myöhemmin kun se eka versio on vihdoin saatu kilpailijalle niin nvidia puskeekin jo seuraavaa tjsp. Noh aika näyttää miten tuon kanssa käy. Toivottavasti saataisiin oikeasti avoin standardi eikä mitään yhden pussiin pelaamista.
Ja tämä eroaa mistä tahansa VK_AMD, VK_IMG, VK_NV, yms. extensionista miten?
Sitä ei vielä tiedetä, mutta harvassapa taitaa olla valmistajien omat laajennokset jotka olisivat päässeet "yleisiksi standardeiksi"
Luonnollisesti puhun MS:n DXR:stä, kun ei ole olemassa muita toimijoita windowspuolella, joka voi luoda melko helposti standardin, jota muut sitten noudattavat.
No lukaseppas noita:
Vulkan® 1.1.83 – A Specification (with all registered Vulkan extensions)
Meillä on vissiin eri käsitys "yleisestä standardista", toki vulkanissa (ja opengl, cl jne) on lukemattomia valmistajien omia laajennoksia hyvättynä itse speksiin.
Siinä vaiheessa jos NVIDIA tarjoaisi NV_sitätätä laajennoksen vaikka nyt raytracing-standardiksi ja Khronos esittelisi sen Vulkanin uutena raytracing-kikkareena vk_sitätätä nimellä oltaisiin jossain siellä päin mitä minä tarkoitin.
Tuo nyt eroa mistään edellisestäkään VK_NV_ laajennoksesta, eikä siitä koskaan tule VK_KHR_ laajennosta ilman muiden hyväksyntää. Jos se osoittautuu hyväksi laajennokseksi se lisätään speksiin, jos taas ei se jää elämään vk_nv_nä jota kukaan ei käytä ja lopulta tippuu pois. Vähän kuin olisivat alussa ajattelleet, että vitut me mitään mantlea tarvita tehdään sama pyörä ite.