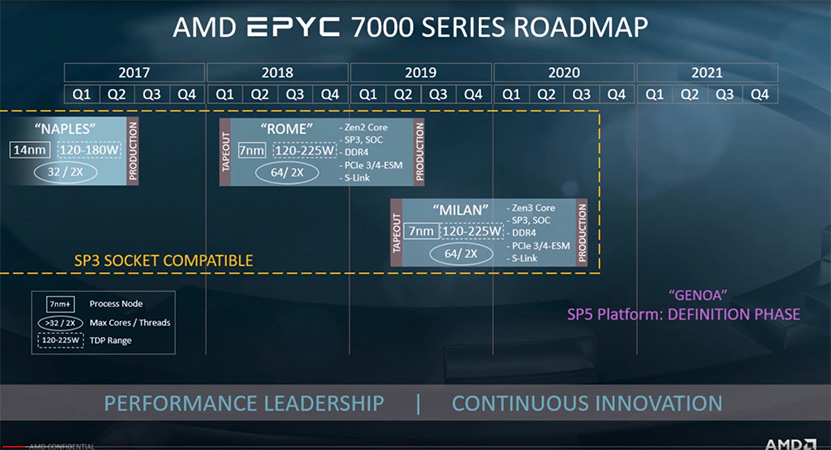
AMD on paljastanut HPC-AI Advisory Council UK -konferenssissa uusia tietoja tulevasta Zen 3 -arkkitehtuurista ja Milan-palvelinprosessoreista. Zen 3 ja Milan tullaan julkaisemaan ensi vuonna.
AMD:n esittelemissä uusissa dioissa saatiin ensimmäistä kertaa tietoa arkkitehtuuritason muutoksista Zen 3:ssa. Vielä tässä vaiheessa tiedonjyväset ovat harvassa, mutta yhtiön mukaan Milan tulee käyttämään samaa paketointia, kuin Rome-palvelinsirut, eli siinä tulee olemaan kahdeksan prosessorisirua (CCD, Core Complex Die) ja I/O-siru (IOD, I/O die).
Prosessori tulee sopimaan tuttuun SP3-kantaan, siinä on kahdeksan DDR4-muistikanavaa ja TDP-arvot tulevat osumaan 120 – 225 watin haarukkaan kuten ennenkin. Dia ampuu lisäksi alas huhut, joiden mukaan Zen 3 -arkkitehtuuri kykenisi suorittamaan neljää säiettä per ydin.
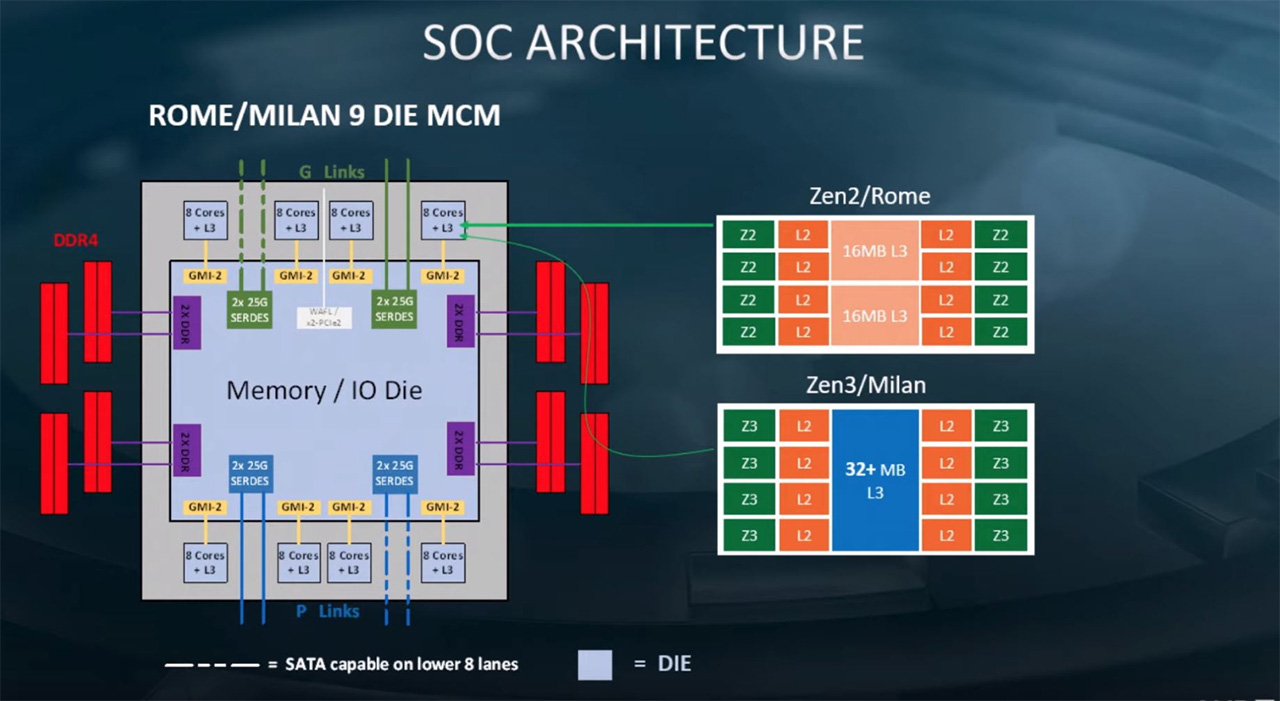
Arkkitehtuuritasolla paljastunut muutos koskee prosessoreiden välimuistia. AMD kertoi tapahtumassa tehneensä merkittäviä muutoksia arkkitehtuurin välimuistirakenteisiin. Siinä missä tähän astisisissa Zen-arkkitehtuureissa kullakin CCX:llä (CPU CompleX, 4 ytimen rypäs) on ollut oma välimuistinsa, tulee Zen 3:ssa saman CCD:n CCX:llä olemaan yhteinen L3-välimuisti. L3-välimuistia tulee olemaan vähintään 32 Mt per CCD, eli ainakin yhtä paljon kuin tällä hetkellä. Yhteinen L3-välimuisti pienentää viiveitä verrattuna tilanteisiin, jossa ydin joutuisi hakemaan tietoa toisen CCX:n L3-välimuistista. Toistaiseksi ei ole tiedossa, onko Zen 3:ssa viilailtu myös muita välimuistirakenteita L3:n lisäksi.
AMD paljasti tapahtumassa lisäksi, että Milan-prosessoreiden tapeout tapahtui jo kuluvan vuoden toisella neljänneksellä. Tämän hetkisen roadmapin mukaan Milan-koodinimelliset palvelinprosessorit saapuvat markkinoille ensi vuonna kuukautta tai paria myöhemmin, kuin Rome tänä vuonna.
Lisäksi tapahtumassa varmistettiin jälleen kerran jo käytännössä tiedetyt seikat Zen 4:stä. Zen 4 -arkkitehtuuriin perustuvan palvelinprosessorin nimi tulee olemaan Genoa ja se on parhaillaan suunnitteluvaiheessa. Genoa tulee sopimaan uuteen SP5-prosessorikantaan ja tukemaan uusia muisteja, mikä tarkoittaa käytännössä varmuudella DDR5-muisteja.
Lähde: Tom’s Hardware
Miksi tehdä asiasta liian vaikeaa? AMD on sanonut tuota "täytä CCX ennen toisen käyttöä" aika monta vuotta. Mikäli CCX määritellään 8-ytimiseksi, ohje pitäisi muuttaa seuraavasti: Täytä CCX ennen toisen käyttöä, mikäli CCX:a on vain yksi, täytä (tähän joku uusi termi ytimien ryhmälle) ensin ja sitten täytä (se toisen ryhmän termi) sitten.
Tai sitten ei keksitä uutta termiä vaan todetaan sen neljän ytimen ryhmän olevan CCX ja mitään muutosta ei tarvita. Edelleen täytetään toinen CCX ensin.
Katsotaan miten käy.
Siitähän tässä onkin kyse ettei esim. tuossa sanota CCX:n määräytyvän jaettujen resurssien mukaan:
Kaikki on yksikössä, ei monikossa. Joten on täysin turha alkaa selittämään minun olevan yksiselitteisesti väärässä. Jos se olisi noin:
A Core Complex (CCX) is formed from groups of CPU cores that share L3 cache resources
Ei tässä olisi mitään keskustelemista. Mutta kun se ei ole.
Luepa keskustelua taaksepäin. Tässä on kyse juurikin siitä miten ne on piirretty. Eli kommunikaatio vasemman puolen ytimen ja oikean puolen ytimen välillä vaatii koko L3 cachen läpäisyä. Siinä ei ole järisyttävää eroa nykyiseen ratkaisuun.
Mitään suoraa kommunikaatiota ytimien välillä ei ole! Ytimet kommunikoivat keskenään käyttäen muistiosotteita, joka käytännössä tapahtuu L3 cachen ohjaimen läpi.
Eikä pitäisi. CCX on tällä hetkellä yhden L3:n yhdistämät prosessoriytimet, niitä sattuu olemaan neljä. Niitä voisi olla ihan yhtä hyvin kaksi, kahdeksan tai vaikka 666 ydintä, eikä se muuttaisi sitä. Sama sääntö pätisi aina, "täytä CCX ennen toisen käyttöä".
Sillä aivan käsittämättömällä logiikalla millä sinä näet tuossa Zen3:ssa nyt "kaksi ryhmää", olisi myös nykyisessä neljän ytimen CCX:ssä "kaksi ryhmää".
Jospa kysyisit tätä ihan itseltäsi.
Kaikille muille tämä asia on ihan päivänselvä.
:facepalm:
Ei ole mitään "toista ryhmää". L3-välimuisti on aina ollut sen CCXn keskellä, eli puolet CCXn ytimistä on (ja on aina ollut) sen L3-välimuistin toisella puolella, puolet toisella puolella, mutta kaikki ovat loogisesti ja kytkennöiltään ihan samaa ryhmää.
Ei ole mitään toista neljän ytimen ryhmää.
On vain kahdeksan aivan samalla tasolla olevaa, aivan samalla tavalla kytkettyä ydintä isommassa CCXssä. Toiset sattuvat sijaitsemaan piirillä fyysisesti hiukan eri paikassa, ihan vaan sen takia, että on fyysisesti mahdotonta sijoittaa ne samaan paikkaan, ja tuollaisella rakenteella minimoidaan kaikkien oleellisten väylien pituudet.
:facepalm:
Siellä on crossbar johon on aivan samalle tasolle kytketty kaikki ytimet sekä L3-välimuisti. "vasen ja oikea puoli" eivät eroa toisistaan mitenkään muuten kuin fyysisen paikan suhteen. Siellä niiden välimuistilohkojen välissä sijaitsee sen kaiken toisiinsa kytkevän crossbarin logiikkaa. Lisäksi crossbarin johtoja saattaa ehkä kulkea myös ylemmissä johtokerroksissa niiden välimusitilohkojen yläpuolella (tästä en ole varma).
Ja kiinnostaisi myös tietää, että mitähän kommunikaatiota sinä kuvittelet niiden ydinten kommunikoivan keskenään. Olen aika varma, että et osaa nimetä mitään. Prosessorin käskykannasta ei nimittäin löydy mitään sellaisia käskyjä kuin "lähetä tämä data ytimelle X".
(tähän kysymykseen saa sitten vastata vain threadripper, älkää muut spoilatko 😉 )
[/QUOTE]
Bootin yhteydessä ne voi hei ehkä teoriassa kirjoitella toistensa konfigurointirekistereihin!!! :rofl:
Mistä tiedät miten asia tulee olemaan Milanissa? Varsinkin että latenssi on sama riippumatta siitä kummalla puolella L3 cachea ollaan.
Jos on vain yksi CCX, silloin ei voida täyttää ensin "toista CCX:a", koska sitä ei ole. Tarvitaan toinen sääntö täyttämiseen.
Kun katsoo Milanin kuvaa, siinä esitetään selkeästi kaksi ydinryhmää. Täysin mahdoton ymmärtää miten siitä voi olla näkemättä kahta ydinryhmää: toinen L3 cachen vasemmalla puolella, toinen oikealla puolella.
Voi olla ettei lopullinen toteutus ole se mitä kuva esittää. Valitettavasti mitään parempaa ei juuri nyt ole tarjolla. Vai onko?
Pari muuta = kaikki, OK.
Ne jotka sijaitsevat samalla puolella L3 cachea ovat samalla puolella L3 cachea (mikäli L3 cache on keskellä). Niiden ytimien keskinäinen kommunikaatio voidaan saada(!) nopeammaksi kuin kommunikaatio L3 cachen toisella puolella olevien ytimien kanssa.
Eroavat fyysisen paikan eli etäisyys ytimestä toiseen on erilainen. Toteutuksesta riippuen sillä voi olla merkitystä. Uutisen mukaan Milanissa on tehty merkittäviä muutoksia välimuistikäytäntöihin, joten se mikä pätee Zeniin, ei välttämättä päde Milaniin.
Haetaan vaikkapa toisen ytimen L3 cachesta tietoa, koska L3 cache on ydinkohtainen mutta silti jaettu kaikkien kesken.
:facepalm:
Ei ole ydinkohtainen vaan kaikille CCXn ytimille yhteinen.
Että väärä vastaus.
Ja dataa haettaessa ei muutenkaan voida heti aluksi tietää, mistä se tulee löytymään. Pitää tarkastaa jokaisen wayn TAGit että tiedetään, mistä se löytyy.
AMD ei ole antanut mitään viitteitä siitä, että se olisi tekemässä jotain uutta x86 käskykantalaajennusta. Voihan sieltä sellainen toki tulla, joka sitten mahdollistaisi näiden ytimien välisen suoran kommunikaation. :bored:
Niinpä, yleensä uusista käskykantalaajennoksista kuitenkin julkaistaan tietoja pari vuotta etukäteen, jotta kääntäjien kehittäjät saavat niille väsättyä tukea ja softakehittäjät osaavat varautua niiden tulemiseen.
Ja millaisiakohan ne uudet käskykantalaajennokset oikein olisivat, millaisen järkevän semantiikan niille voisi oikein keksiä? Kun ei kuitenkaan tiedetä, kuka siellä toisella ytimellä on ajossa…
Koko milan-paketissa on kahdeksan kappaletta niitä CCXiä. Kalliimmissa kuluttajakantaan tulevissa kuluttajamalleissakin tulee olemaan kaksi.
Ja muutenkin, luet nyt vanhaa optimointiopasta ja sen perusteella päättelet jotain tulevien prossujen rakenteesta? :facepalm:
Kuten on sanottu jo hyvin selvästi, loogisesti siellä ei ole mitään kahta eri ryhmää sen enempää kuin nykyisten CCXien sisällä on kahta eir ryhmää. Se on vain fyysistä ytumien sijoittelua.
Edelleenkään et ole kertonut (paikkaansapitävää vastausta) siitä, mitä se kommunikaatio voisi olla.
Se, minkä kommunikaation nopeudella on väliä on sillä, kuinka nopeasti ydin saa luettua dataa sieltä L3-välimusitilta. Ja kun välimuisti (jonne kaikki tekee hakuja) on keskellä, viiveet ytimiltä sinne on kaikkein pienimmät. Tällöin puolet ytimistä on luonnollisesti sen toisella puolella, puolet toisella puolella.
Toteutus on yksi crossbar, jonka kautta kaikki on kytketty toisiinsa. Tällöin sillä ei ole merkitystä.
Se merkittävä muutos on juuri se CCXn koon tuplaaminen.
Yksi laajennos voisi olla "tee threadripper tyytyväiseksi". 😉
Ei vaan ydinkohtainen JA jaettu. Yhdellä ytimellä CCX:ssa on tietty määrä L3 cachea kaikesta mutta kaikkien ytimien L3 cache on kaikkien ytimien kesken jaettu. Yhteinen välimuisti löytyy vaikka Core 2 Duosta, siinä ei ole mitään ydinkohtaista jakoa. Se on yhteinen.
En tiedä mitä taas yrität selittää mutta yleisesti ottaen mitä pidemmän matkan signaali joutuu kulkemaan, sitä kauemmin signaali kulkee. Kuten vaikka Intelin ring busista voi havaita.
Miten ajattelit tämmöisen toteuttaa käytännössä?
Ja miksi AMD tekisi jotain tämmöistä kun ZEN2 heikkous on juuri tuo CCX ryppäiden kesken jaettu L3? Näkyy aika makeasti latensseissa. Se, että joka ydin on samanarvoinen L3 koko kapasiteetin suhteen on pelkästään etu.
Höpöhöpö.
Se koko L3-välimuisti on ihan kaikkien ytimien yhteistä. Ja se sijaitsee juuri siinä ytimien välissä, jotta sinne on mahdollisimman lyhyt matka kaikilta ytimiltä.
Jos sinulla olisi yhtään hajua siitä, miten välimuistit toimivat, tajuaisit tämän, mutta kun on pihalla kuin lumiukko on helppo heitellä absurdeja väitteitä.
Ps. Suosittelen myös tutustumaan esim malleihin ryzen 5 1600, ryzen 5 1600X, ryzen 5 1500X. Niiden ydin- ja välimuistimääriin.
Se on ihan yhtä yhteinen kuin ryzeninkin L3-välimuisti. Väylärakenne miten se on kytketty on vaan hiukan erilainen.
Ja meni muutenkin nyt melkoiseksi maalitolppien siirtelyksi tämä. Kun et keksinyt, mitä liikennettä niiden ytimien välillä oikeasti voi olla, rupesit sotkemaan L3-välimuistia tähän mukaan, ja uudelleenmäärittelemään sitä, mitä ydin tarkoittaa.
L3-välimuisti ei ole osa ydintä. Ja matka kaikilta ytimiltä koko L3-välimuistille minimoidaan nimenomaan nykyisellä rakenteella.
Aika hyvin tiedät asiat yhden dian perusteella. Jossa ei edes sanota sanaakaan kuluttajamalleista :facepalm:
AMD on tehnyt ison työn saadakseen optimointeja prosessoreilleen. Miten sitä edistäisivät jatkuvat muutokset? Huonosti.
Ainoa mitä on tiedossa on yksi kuva. Ja sen perusteella luulet tietäväsi mitä tulee olemaan :confused:
Entä jos on eri toteutus? Ring bus vaikka? Silloin sillä on merkitystä.
Miksi pitäisi toteuttaa?
Se L3 välimuisti on ytimessä kiinni, joten se on ydinkohtaista mutta jaettu kaikkien ytimien kesken.
Spekuloitu Zen2 IO die:n L4 cache (jota ei tullut) olisi yhteistä. Koska 1. ydinkohtaista välimuistia käyttää nopemmin (ainakin on mahdollista saada käyttämään) se ydin jonka yhteydessä se on 2. kaikki ytimet saavat käytettyä sitä yhtä nopeasti jos homma toteutetaan optimaalisesti.
Ei ole, CCX ei ole jokin satunnainen maantieteellien alue jolla on satunaisesti mudostuneet rajat sen sijaan CCX on looginen toimintojen kokonaisuus ja yksi osa tuota kokonaisuutta on L3 muisti.
:srofl:
Niitä slidejä oli kaksi kappaletta, ja tuo Milan-CCXien määrä paketissa kyllä kävi hyvin selväksi niistä.
Milanin ytimien määrä itseasiassa mainittiin molemmissa slideissä.
Ja kehityksen suunta on looginen, AMD:lle jaetusta L3:sta on vain haittaa. Varmasti jos pystyisivät niin CCX olisi 64 corea ja 256M L3 kaikille ytimille yhteinen.
Näen slideissä pelkkää Epycia.
Epyc Naples
Epyc Rome
Epyc Milan
Mistä olet lukenut että osa L3 välimuistista olisi ytimessä ’kiinni’ tai että se ei olisi kaikki saman CCX:n yhteisessä käytössä? Jos näin olisi (ei ole), niin esim. 6 ytimisissä zen prossuissa olisi vähemmän L3 cachea kuin 8 ytimisissä.
kirjoittelit myös, että missään ei lue etteikö milanissa olisi ringbus arkkitehtuuria.. nämä on just sellasia juttuja joista kerrottaisiin erittäin aikaisessa vaiheessa, sillä ne vaikuttavat voimakkaasti optimointistrategioihin, samoin kuin että CCX:n alle speksattaisiin joku uusi matalempi visuaaliseen layouttiin perustuva rakenne.
Jos nyt vaikka lähtis lukemaan tosta kappaleesta 4 eiäppäin http://ac.aua.am/arm/public/2017-Sp…mputerOrganizationAndDesign5thEdition2014.pdf.
Kyllå siellä ne kakutkin tulevat sitten vastaan ennen pitkää, niin asia selkenee. Olen tässä asian joukon/joukkion kannalla. Tarjoo tääkin keskustelu näinkin silti omat huvinsa :cigar2:
Kuluttajaprosessoreita?
Se L3 on jaettu osiin, 1, 2 tai 4 megaa. Osat ovat ytimien vieressä eli käytännössä fyysisesti ytimessä kiinni. Ne cachethan ovat saman CCX:n käytössä ja vieläpä samalla latenssilla, sanoinko jossakin muuta? Mutta niinhän sen ei tarvitsisi olla, voitaisiin tarjota nopein pääsy siihen osaan joka on ydintä lähinnä.
Ring bus oli vain yksi esimerkki mahdollisesta muutoksesta, tässä vaiheessahan ei tiedetä edes sitä missä L3 välimuisti sijaitsee. Eikä se ole yksinkertaista. "32+" eli 64 MB cachea ytimiin jolla kisaisi Inteliä vastaan? Chiplet on noin 74 mm2. 16MB cache vie tilaa karkeasti 16mm2, ihanaa, 1mm2 per mega. 64 megaa veisi 64 mm2 tilaa ja chiplet olisi 122mm2. Se ei ole enää "pieni". Koska tuo slide koski vain ja ainoastaan Milania, olisiko mitään 58mm2 chiplet ja L3 cache I/O piiriin ja 64-ytimen CCX.
Juuri siihen optimointiin liittyen, AMD on toitottanut vuosia CCX:n olevan 4 ydintä ja CCX:a olevan 2. Mitä tapahtuu jos CCX:n koon edes kerrotaan olevan jotain muuta kuin 4? Siitä seuraa paljon negatiivisia asioita kehittäjiltä.
Voisitko täsmentää, miksi CCX:n koon kasvaminen 8 ytimeen olisi ohjelmistokehittäjien kannalta huono juttu?
Juuh, kantsii vähän lukea siitä miten eri cache-tasot toimivat. Vinkkinä, että saman tason cachea voi käyttää vain jos sen koko sisällön tarkistaa aina kun sieltä lukee jotakin. Cacheen kirjoitettaessa ei sen nopeudella ole mitään merkitystä.
CCX:ien koko on aivan alusta asti vaihdellut ainakin välillä 3-4. Mikä käytännön ongelma on laajentaa tätä skaalaa esim. kahdeksaan asti?
Ring Bus ja Crossbar ovat kaksi eri asiaa. AMD:n käyttämästä Crossbarista emme saa todennäköisesti tietää koskaan kaikkia yksityiskohtia. Yhdysvalloissa kun voi patentoida aivan triviaaleja asioita.
Matkalla lohkojen välillä layoutissa ei ole juurikaan merkitystä tässä casessa vs Ringbus. Oletus on että hitaampi lenkki on L3 kontrollilogiikka kuin dataväylä "kauimmaiselle corelle". Ei tässä kuuhun asti olla menossa. Sillä on synkronisessa logiikassa merkitystä on ehtiikö data seuraavaan nousevaan/laskevaan kellonreunaan. Jätetääs tästä kuitenkin kellopuun balansointi, hajakapasitanssit ja parasiittiset ilmiöt pois yksinkertaisuuden vuoksi, ne ovat enemmän backend kaverien ongelmia.
Arvaus: Eivät ole siirtämässä sitä IO-dielle.
Ihan välihuomautuksena, kun luen tätä vaikka moni asia menee yli oman osaamisen enkä siksi voi itse osallistua:
Threadripper vastaa asiallisesti argumentoi perustelee näkemyksen ja pohdinnan tulevasta ilman ylimääräistä ja henkilökohtaista huttua.
Hänen kanssaan/vastaan keskustelevat, joko alussa, keskellä tai lopussa, viljelee näitä lapsellisia emoji naamoja tai "höpöhöpö" "lopeta jo" "mene lukemaan/opettelemaan" ym turhaa huttua, joka tekee ikävää luottevaa keskustelusta joka voisi muuten olla asiallinen ja opettava.
Esim. hkultala ei ole yhtä ainoaa viestiä pystynyt kirjoittamaan ilman jotain edellä mainituista, yleensä ei ilman useampaa :facepalm:
Miten tämä liittyy siihen ettei cachen nopeus voi riippua siitä mistä luetaan? Cachen latenssi voi olla erilainen riippuen siitä mikä ydin lukee mistä vaikka cache olisi jaettu kaikkien ytimien kesken.
Se edellyttäisi ainakin jonkinlaisia muutoksia: Papermaster: AMD's 3rd-Gen Ryzen Core Complex Design Won’t Require New Optimizations
Tuosta paistaa läpi se ettei AMD halunnut tehdä Zen2:n mitään sellaisia muutoksia Zen:n nähden joka edes vähäisessä määrin tekisi Zenille tehdyistä optimoinneista toimimattomia. AMD haluaa olla hyvissä väleissä ohjelmistopuolen kanssa, joten ymmärrettävää.
Ring busin otin esiin koska se on loistava esimerkki matkan vaikutuksesta nopeuteen. Kaikissa tilanteissahan nopeus ei ole kaikki kaikessa eikä aina edes haeta nopeinta ratkaisua koska usein on pakko valita paras kompromissi. USA:n patenteista joku muu tietää paremmin. Sen perusteella mitä olen lukenut, ei harmita.
Ring bus tarjoaisi vaihtoehdon L3:n kautta kiertämiselle, ja lyhyenä (vähän ytimiä) se todennäköisesti olisi nopeampikin. Miten se kannattaisi transistorikulutuksen ja muiden kannalta on toinen juttu. Todennäköisesti kokonaisuutena ei.
Se missä AMD ei tällä hetkellä pärjää on kuormat jotka haluavat paljon välimuistia. Chipletteihin L3:n lisääminen se nostaa valmistuskustannuksia radikaalisti. Erillinen suuri L3 cache (ja ehkä jopa L3 cache pois chipleteistä jotta säästöä) voisi antaa tietyissä kuormissa Intelille kunnolla kyytiä. Kotikäytössä joku 32+ MB L3 olisi mukava, hieman vaikea uskoa sellaista tuotavan ainakaan massamalleihin. Vaikuttaisi oudolta ratkaisulta valmistaa vain yhtä chiplettiä. Sellaista jossa jättimäinen L3 cache :think:
Mitä tarkoitat matkalla? Fyysistä etäisyyttä? Vai sitä että jokaisessa ringin nodessa on logiikkaa jonka kautta väylä kulkee? Logiikka: lisää kellojaksoja ja latenssia.
Niissä argumenteissa ei vaan ole päätä eikä häntää, ja sen tajuaa jos tietää yhtään mitään tietokonetekniikasta.
Ja maalitolppien siirtely ei muutenkaan ole asiallista argumentointoa
Kun toisen ymmärrys asioista on kolmivuotiaan tasolla ja kyky myöntää sitä puhtaat nolla, siinä missä toiset ovat oikeasti suunnitelleet prosessoreita niin kyllä siinä alkaa hermo mennä tuohon inttämiseen.
dunning-krueger on hyvin vahvoilla tässä.
Olenpas. Jolloin sinä syyllistyt valehteluun tuossa väitteessäsi.
Ainakaan tuossa kuvatussa symmetrisessä rakenteessa on vaikea kuvitella merkittäviä eroja ytimien L3 latenssien välille, vai pystytkö piirtämään yhdeltä ytimeltä L3 muistin siitä kauimpaan kulmaan kuin joltain toiselta ytimeltä? Et, sillä rakenne on symmetrinen näiden etäisyyksien ja siten L3 latenssin suhteen. Edelleenkin, jotta L3 välimuistista voi lukea jotakin, pitää kaikkien CCX:ien L3 välimuistit koluta läpi jopa toisia chiplettejä myöten. Jos tässä on jotakin epäselvää, niin kannattaa ihan oikeasti hieman tutustua cache-hierarkiaan ja miten se toimii. Youtubesta löytyy pari hyvää n. tunnin luentoa jotka voin linkata jos kiinnostaa.
Etenkin serveriprossuissa, joissa ytimet jatkossakin sijaitsevat eri chipleteillä, yhden CCX:n L3 latenssien eroilla ei olisi mitään vaikutusta, sillä pisin etäisyys ja latenssi on kuitenkin jonkun toisen chipletin kauimmaiseen L3 välimuistin nurkkaan.
Alleviivaisitko vielä sen kohdan joka vaikuttaa optimointeihin CCX:n (maksimi)kokoa muutettaessa. Jo nyt ne on erikokoisia riippuen prosessorimallista. Onhan se mahdollista että jotain optimointeja on kovakoodattu toimimaan vain kun n{3,4}, mutta se on nopeasti korjattu.
Nykyiset Zen2 chipletit sisältävät jo 32MB L3 cachea. Piirin koon ei tarvitse muuttua L3 cachejen yhdistyessä, vaan se saattaa jopa kutistua milanissa, kun siirrytään samalla uudempaan valmistustekniikkaan.
Hieno esimerkki virkkeestä, johon saatu kaksi perustavanlaatuista virhettä/väärinkäsitystä tietokonetekniikan asioista.
mitä sieltä kiertäisi? Mitä se liikenne olisi? Minkä seurauksena se liikenne tapahtuisi?
Prosessori tekee sen mitä suorittamat käskyt sen käskee tekemään.
Kuten tässä ollaan pomkin kanssa jo monta kertaa sanottu, x86-käskykannassa ei ole mitään sellaisia käskyjä jotka toimisivat tyyliin "siirrä tämä data tuolle toiselle ytimelle".
Edelleenkään et ole tarjonnut mitään (toimivaa) vastausta tähän kysymykseen vaikka sitä kysyin jo kauan sitten.
Höpiset vaan jostain ydinten välisestä kommuunikaatiosta tajuamatta yhtään, mitä se on. Tajuamatta yhtään, miten ne oikeasti kommunikoivat keskenään.
:facepalm:
Crossbar on nimenomaan se nopein tapa kytkeä pienehkö määrä asioita yhteen. Kaikkialta pääsee kaikkialle ilman mitään välihyppyjä.
Onpas taas tuottavaa, eikä siinä popparit kourassa ja lueskellaan, miten vaikeaksi noinkin simppeli muutos paperilla saadaan tehtyä. #hyvääviidettä
Terkuin se kaveri mikä ei vieläkään ymmärrä mistään, mistä täällä puhutaan. 😀
Eikä edellytä.
Meillä on jo nyt myös kahden ja kolmen ytimen CCXiä eikä pelkästään neljän ytimen CCXiä, ja se, että ydinten määrä CCXssä kasvaa vain helpottaa asioita; Kaikki se koodi, joka on optimoitu neljän ytimen CCXlle toimii vähintään yhtä hyvin kahdeksan ytimen CCXllä.
.. Ja siirtyminen kahdeksan ytimen CCXään ei riko yhtään mitään zen-optimointeja. Tämäkin on triviaali asia, kun ymmärtää niistä optimoinneista yhtään mitään.
Ei, vaan ne on ne kuormat joilla zen2 nimenomaan pärjää HYVIN.
Jälleen kerran väärin.
Välimuistit tehdään SRAMista, ja SRAM skaalautuu erinomaisesti valmistusprosessin pienentyessä.
TSMCn "7nm" tekniikalla tehty HD-SRAM-solu on pinta-alaltaan 0.027 um^2.
Globalfoundriesin "14nm" tekniikalla tehty HD-SRAM-solu on pinta-alaltaan 0.064 yum^2.
Eli välimuisti "7nm" tekniikalla tehtynä vie mukavasti n. 42% siitä pinta-alasta mitä se veisi GFn "14nm" prosessilla. "7nm" valmistusprosessin hinta pinta-alaa kohden on käsittääkseni alle 2.37-kertainen "14nm" prosessin hinnasta, eli välimuisti tulee halvemmaksi ydin-chipletillä kuin IO-chipletillä.
Hieno heitellä hatusta tällaisia ymmärtämättä yhtään kokonaiskuvaa.
Jos siellä olisi joku "erillinen suuri L3 cache" ei se olisi L3-cache vaan L4-cache, mikäli niillä chipleteillä olisi edelleen L3-cache.
ja mikäli niillä chipleteillä taas ei olisi edelleen L3-välimuistia, sitten L2-huti olisi kaamean hidas koska sen "erillisen suuren cachen" viive on todella paljon hitaampi kun sen lähellä CCXssä olevn L3-kakun.
Intelin prossujen (joilla on kaikille ytimille yhteinen L3) L3-viive on selvästi suurempi kuin zenin L3-viive, vaikka intelin prossuissa se L3 on edelleen samalla piilastulla.
Kaikki pääsisi helpommalla kun laittaisitte threadripperin ignoreen mihin kuuluu
En väitä olevani mikroprosessoreiden asiantuntija, vaikka aikanaan olenkin elektroniikan harjoitustyönä suunnitellut binääritason tilakoneesta alkaen, ohjelmoinut, simuloinut ja toteuttanut FBGA-toteutuksena yhden pienen (ei ohjelmoitavan) mikropiirin (tai oikeastaan selaisen osasen).
Yhdellä aika pitkällä kurssilla suunnittelimme myös mikroprosessorin arkkitehtuurin jokseenkin yleisellä tasolla. Sen verran muutakin koulutusta digitaalisten mikropiirien suunittelusta kuitenkin hankin, että diplomityöni rahoituksen viivästyminen Suomen Akatemialta vaikutti kauan kauan sitten uravalintaani niin suuntaavasti, että ajauduin mikropiirisuunnittelun sijaan teletoimialalle erilaisiin ohjemisto- ja asiantuntijatehtäviin.
Vaikka tästä koulun penkillä istumisesta on kulunut jo liki 30 vuotta, olen kohtuullisen yleisella harrastustasolla pyrkinyt seuraamaan erityisesti CPUiden arkkitehtuurin kehittymistä.
Niin etevä en kylläkään ole, että osaisin vahvasti argumentoida kaikkia tämän foorumin väittelyissä käytyjä mielipiteitä, mutta sen verran ymmärrän, että osaan perustellusti todeta hkultalan osaamisen näissä keskusteluissa olevan merkittävästi useimpia foorumilaisia edistyneemmällä tasolla.
Sitten on näitä muita keskustelijoita – kuten tämän keskustelun haaran kohteena oleva henkilö – joiden osaaminen – kaikella kunnioituksella – tuntuu olevan eri web-sivustojen uutispalstojen kommenttikenttien perusteella johdettua 'omaa asiantuntemusta'.
Jos osaamisen taso on sitä, että arvioidaan jonkin komponentin (esim. ccx-blokin) toimintaa ja arkkitehtuuria powerpoint -kalvosta kaapatun merkittävästi yksinkertaistetun graafisen kuvan perusteella, lisätään siihen omia ja sekalaisten nettipalstojen / foorumeiden 'asiantuntijoiden mielipiteitä/spekulointeja/toiveita', ei lopputuloksen voikkaan olettaa olevan muuta kuin tässä edellä esitetyt – sanotaan suoraan haihattelut.
Väkisin vänkäämisen ja väärin perustein tapahtuvan argumentoinnin sijaan kannattaisi vaikka kysellä tyyliin 'voisiko tämän xxx-ratkaisun suunnitella tai toteuttaa vaikka tällä tavalla', tai 'toimiiko tuo niin, että…'.
Näihin osaavat ihmiset varmaan vastaavat mielellään.
Kaikkea AMD/Intel/nVidia/jne. eivät toki kerro yksityiskohtaisesti noissa julkistetuissa tai vuotaneissakaan kalvoissa edes kumppaneilleen tai tutkijapiireille, joten aina sinne jää epäselviä asioita pohdittavaksi foorumeillekin.
Näyttää kovasti siltä, että kun joskus tulevaisuudessa @hkultala on väärässä, niin puoli foorumia ei uskalla hänelle siitä sanoa yhtään mitään ja yhtyy väärään olettamukseen.
Tässä kuitenkin @Threadripper on väärässä ja @hkultala yrittää selittää asioiden oikeaa kantaa, mutta se ei mene perille. Sivustakatsojana tästä tulee vähän tylsää ekan sivun jälkeen.
Keskustelu ja väittely tietotekniikkafoorumilla on kivaa, mutta tässä on taas vähän liikaa "painavaa tekstiä" ja osa siitä on spekuloitu puuttellisesta datasta. @demu sanoi, että voisi kysyä kohteliaasti mielipidettä, mutta paljon helpommin saa asioita hkultalasta irti, kun on vaan suoraan väärässä ja esittää asian faktana.
—
Itse artikkelista bongasin vain CCX:n kaksinkertaistumisen, muut tiedot ei itselle riitä tarkempaan spekulaatioon. Ehkä tulevaisuudessa 8-ydin CCX on uusi minimi. Vaikea kuvitella, että siitä sitten disabloidaan coreja hirveästi, että saadaan niitä halpisprosessoreita. Ehkä uusi standardi on 6 ydintä minimi ja vähemmällä ei uudet AAA-julkaisut pyöri?
AMD:ltä on tulossa 7nm APU, joka on joka tapauksessa aivan eri layouttiin perustuva tuote ja joka täyttää desktopilla nimenomaan noita hintaluokkia missä nyt on noita leikatumpia piirejä.
Ei minimi vaan maksimi, ihan samalla tapaa myös uudella rakenteella voidaan poistaa ytimiä käytöstä kuin ennenkin.
edit:
Tarkennus: Yhdessä chipletissä tulee edelleen olemaan 8 ydintä, ne vain näyttäisivät olevan jatkossa kahden sijasta yksi CCX. Ytimiä voidaan kuitenkin poistaa ihan yksi kerrallaan käytöstä, se ei siitä muutu.
Miten ylläpidon jäsen @Kaotik voi tykätä tällaisesta viestistä, kun osa foorumin käyttäjistä saa varoituksen jos kirjoittaa näin?
Ei voi kuin ihmetellä vastauksen sisällön tasoa ja samalla ylläpidon jäsen onnessaan peukuttaa… Voinko tähän sanoa että teidän ymmärrys hyvästä käytöksestä on kolmivuotiaan tasolla, kun yllä kaotik pitää sitä hyvä viestintänä?
Itse asiassa ytimiä voinee poistaa (mahdollisesti) jopa nykyistä monipuolisemmin, kun noissa nykyisissä näyttäisi olevan sama määrä ytimiä kussakin CCX. Toki esimerkiksi jotain 7-ydinprosessoreita epäilen suuresti koskaan markkinoille tuotavan.
Toki vaikea sanoa miten ne yli 8 ytimen olevat (mutta silti vajaat) prosessorit kannattaa tehdä. Yksi hyvä täysi siru ja sen kaveriksi ja yksi huono siru tuottaisi sellaisia nVidian näyttömuistikikkailufiiliksiä, kun se skaalautuminen tietyn ydinmäärän jälkeen olisikin selvästi huonompaa.
Millä perusteella? Kyllä tässäkin ketjussa näyttäisi olevan usempi kirjoittelija, joka olisi sanonut vastaan sille väärässä olevalle osapuolelle, riippumatta kumpi se tässä oli.
Miten tilanne eroaisi nykyisestä? 3900X:ssä on kaksi chiplettiä, joissa on 6+6 ydintä, 3950X:ssä 8+8 ydintä. Neljän toimivan ytimen chipletit menevät halpisprosuihin. Jos toimivia ytimiä on vähemmän, menee siru roskiin.
Tuossa nyt ajettiin takaa sitä että 3900 on 6+6 eikä esimerkiksi 8+4, jolloin toisen chipletin 4 ydintä saisi enemmän L3 cachea verrattuna 8 ytimen chiplettiin.
Ei se 12-ytiminen zen3-sarjan piirikään tule olemaan mikään "8+4". Vaan sekin tulee olemaan "6+6".
Fyysistä etäisyyttä. Esim. Bulldozerin L2 cachea on haukuttu (aiheesta) hitaaksi. Syynä lienee fyysinen etäisyys.
Ei suurta eroa, mutta eroa kuitenkin. Aika pienestä pitää nykyisin puristaa suorituskyvyn rippeitä.
Anna ihmeessä lisätietoa tuosta lihavoidusta. Alkoi kiinnostamaan. Esim. linkki johonkin artikkeliin.
Kiinnostaa siksikin ettei ainakaan Sandy Bridgessä L3 latenssi riippuu siitä mikä core hakee tietoa mistä cachesta, vaikuttaa myös nopeuteen: Intel's Sandy Bridge Architecture Exposed
Samat sanat tähän kuin edelliseen. Kuulostaa mielenkiintoiselta ratkaisulta hakea tietoa cachesta jota ei ole jaettu.
Perussääntö muuttuu. Nyt ei voi mennä pahasti pieleen jos kuorma jaetaan CCX:n sisällä. Tuon muutoksen jälkeen saattaa voida (ei tiedetä tarkasti tässä vaiheessa). Eli nyt riittää yksi perussääntö, muutoksen jälkeen ei välttämättä. Lisäksi Papermaster korosti ettei mitään muutoksia tehty CCX rakenteeseen jotta mitään muutoksia ohjelmissakaan ei tarvittaisi. Eli AMD:n mielestä CCX:n muutos olisi aiheuttanut muutostarpeen ohjelmistoihin.
Maailmassa on hirveä kasa kovokoodattuja asioita jotka OLISI nopeasti korjattu. Kuka ne korjaa ja milloin on täysin toinen juttu.
Niin, 32+ MB joka tietenkin voi olla lähes mitä tahansa. TSMC lupaa 15% säästöä pinta-alassa. 64MB cachella tuskin pienenee.
x86 prosessorissa ei tietääkseni ole käskyjä monelle asialle, kuten lataa Windows ja käynnistä pasianssi. En sitten tiedä hoidetaanko se jollakin dokumentoimattomalla erikoiskäskyllä, kun en itsekään löytänyt sellaista käskyä. Jossain täytyisi olla kattavampi lista prosessorin tukemistä käskyistä, niin tietäisi mitä kaikkia ohjelmia nykyprosessorit pystyvät käynnistämään.
Vitsit vitsinä, jatketaan vihdoin sillä alkuperäisellä aiheella, eli 8-core CCX: http://developer.amd.com/wp-content/resources/56420.pdf
Within each Zeppelin there are 2 Compute Complexes (CCX). Each CCX has•its own L3 cache. Each core has its own L2 and L1i and L1d caches•up to 4 cores per CCX, i.e. 32 cores per socket. Other EPYCcore counts follow
Tuossa annetaan linjaus jonka mukaan CCX:ssa on maksimissaan 4 corea. Siten CCX:ssa ei voi olla yli 4 corea. Lähteenä on AMD:n virallinen dokumentti 12/2018.
Mikä taho päättää CCX:n määritelmän? CCX ei ole käytössä muissa kuin AMD:n prosessoreissa eivätkä muut tahot kuin AMD sitä tuotteissaan käytä. Siten se taho joka määrittelee miten CCX määritellään on AMD.
Koska CCX:ssa ei voi olla yli 4 ydintä, CCX:ssa ei voi olla 8 ydintä. Se on tilanne tällä hetkellä.
Voit täysin vapaasti spekuloida tilanteen olevan erilainen Milanin julkaisun hetkellä tai ennen sitä. Mutta juuri nyt tilanne on se ettei CCX:ssa voi olla yli 4 ydintä. Tietysti voit esittää vastaavan dokumentin, AMD:n työntekijän lausunnon tai AMD:n julkaiseman kuvan jossa kerrotaan jotain muuta. Sitä odotellessa.
Edellyttää mikäli on aiemmin mainittua termiä käyttäen kovokoodattu 4-core CCX:n mukaan.
Toimii jos ne 8 ydintä ovat keskenään suunnilleen "samanarvoiset", ts. on lähes se ja sama miten kuorma niiden kesken jaetaan. Jos niin ei ole, ongelmat ovat taattuja koska kaikki eivät kuitenkaan heti ymmärrä vaihtaa toimintatapojaan vaan muistavan sen slogania jota AMD on vuosia toitottanut: täytä yksi CCX ensin.
Jos kuormanjaolla ytimien kesken ei ole merkitystä, sitten ei. Jos on, sitten tulee ongelmia. Vielä kerran se yleissääntö: täytä yksi CCX ensin. Jos CCX:a on yksi ja CCX on 4-ytiminen, ei voi mennä pahasti pieleen tällä säännöllä. Jos CCX:a on yksi ja CCX on 8-ytiminen JA kuormanjaolla on merkitystä, joku mokaa satavarmasti jossakin vaiheessa.
Kun et kerran minua usko, otetaan AMD:n edustajan mielipide asiaan:
Eli ratkaiseva asia on CCX ja kun se on SAMA CCX kuin aiemmin, ei tarvita optimointeja.
Eikä pärjää. Kun sanoin paljon cachea tarkoitin paljon, eli 50+ MB jaettua kaikkien ytimien kesken.
Tuohon vaikuttavat myös saannot (joista ei tarkkaa tietoa) ja kun vielä huomioidaan ettei AMD tälläkään hetkellä tee kuin yhtä ainoaa chiplettiä mutta tekee kahta eri I/O piiriä kahdella eri prosessilla, niin en olisi ihan varma.
Tarkistaisin nuo välimuistien todelliset koot prosessoreissa mutta en löytänyt kunnollista Zen2 die shottia.
Sanoinkin "ehkä jopa L3 cache pois chipleteistä jotta säästöä". Silloin se olisi L3 cache.
Kokonaiskuvaa katsoen, miksi AMD on julkaissut pelkästään Zen2-prosessoreita joissa on täysi L3 cache. Vai onko tullut muita? Kai niitä cachevikaisiakin tulee, sopisivat tuohon hyvin. En todellakaan usko kaikkien pikkuvikaisten prosessorien olevan sellaisia joissa nimenomaan cache toimii täysin.
Nämä prosessorit olisi tarkoitettu niitä prosessoreita vastaan joille AMD:lla ei ole vastinetta. Niitä joissa on paljon cachea, 60 megatavua ja yli.
Intel pyytää quad coresta suunnilleen saman kuin AMD 64-coresta: Intel® Xeon® Processor E7-8893 v4 (60M Cache, 3.20 GHz) Product Specifications
Sanoin jo tuossa aiemmin siitä cachen määrästä. Joissakin Intelin prosessoreissa kaikkien ytimien kesken jaettua cachea on paljon enemmän. AMD:lle ei vieläkään ole prosessoria jossa kaikille ytimille yhteistä L3/L4 cachea olisi Paljon. AMD hakee Zen2:lla muita kuin niche markkinoita enkä tiedä paljonko noita 50+ megan cache -prosessoreita ostetaan. Silti, yksi chiplet ja karsittu I/O piiri jätticachella ja hintalapuksi 9K$ ei kuulosta kovin pahalta.
Tässä on edelleen ollut kyse siitä voiko CCX olla 8-core. AMD sanoo ettei voi. Oliko muuta asiaan liittyvää?
Se powerpoint -kalvosta kaapatun merkittävästi yksinkertaistettu graafinen kuva on valitettavasti parasta mitä on saatavilla. Sitäpaitsi siitä kyllä näkee asioita kun osaa katsoa, esimerkiksi siitä nähdään kuinka ytimiä voidaan poistaa käytöstä. Enkä väitä että minä näen. Joku muu näkee.
Fakta on edelleen: AMD:n virallisessa dokumentissa viime vuoden joulukuulta linjataan ettei CCX:ssa voi olla yli 4 ydintä. Tuolla perusteella: miten CCX:ssa voi olla 8 ydintä? Vastaisitko tuohon kysymykseen kun kerran minun esitit olevan väärässä, kiitos.
Siinä käsiteltiin tietysti viime vuonna markkinoilla olevia prosessoreita. Yleensä parin vuoden päästä markkinoille tulevien prosessorien speksejä ei ole tapana kertoa kovin tarkalla tasolla. Nyt ilmeisesti alkoi olla jo aika valottaa salaisuuden verhoa.
Niinhän siinä käsiteltiin. Se on kuitenkin AMD:n virallinen kanta, parempaa saa esittää. Kalvoissahan ei sanota CCX:sta tai sen koosta sanaakaan. Siksi niillä kalvoilla voi spekuloida, muttei väittää faktana olevansa oikeassa.
Mutta tuossahan puhutaan vain Zeppelin ytimestä. Jeesuksen vanhaa rautaa näin ZEN 2 aikana.
Samaten sulta unohtui sandyn L3 viipale-viive spekuloinnissa suuruusluokka. Muutama kellojakso sinne tänne ei juuri venettä keikuta.
AMD:n tapauksessa kokonaisviive kasvaa todella rumasti
Ei se mitään perustuslakia ole. Se, että CCX:ssä oli tuolloin neljä corea ei millään tavalla estä, ettei CCX:ssä tulevassa Zen 3:ssa ole neljää corea.
Se on ainakin jo nyt selvää, että nykyisenkaltaista CCX:ää siellä ei julkistettujen tietojen mukaan ole. Millä termillä sitä sitten jatkossa kutsutaan, on ihan täysin yhdentekevää.
Niin ja kun ajattelee sen L3 muistiratkaisun päivittämisen teknisiä perusteita niin siihen kyllä kannattanee uhrata aikaa ettei välimuistissa olisi NUMA tilannetta ollenkaan. Siitä ei suorituskyvyllisesti ole mitään haittaa ja vanhatkin per 4-core ccx optimoidut ohjelmat toimii aivan kuten ennenkin.