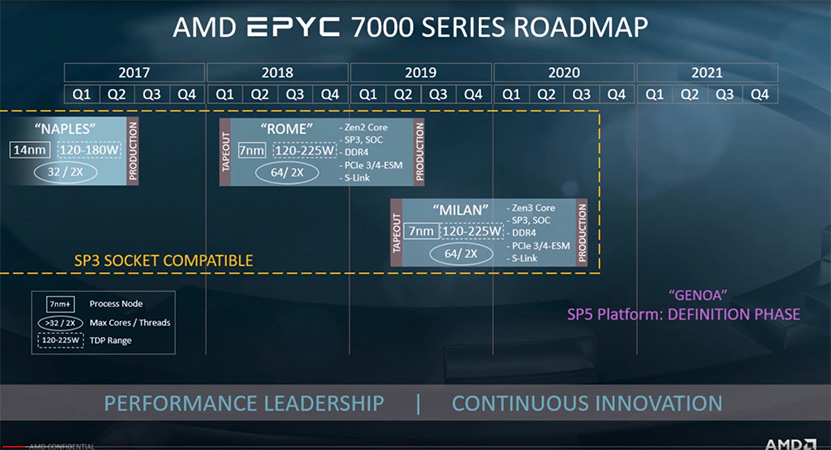
AMD on paljastanut HPC-AI Advisory Council UK -konferenssissa uusia tietoja tulevasta Zen 3 -arkkitehtuurista ja Milan-palvelinprosessoreista. Zen 3 ja Milan tullaan julkaisemaan ensi vuonna.
AMD:n esittelemissä uusissa dioissa saatiin ensimmäistä kertaa tietoa arkkitehtuuritason muutoksista Zen 3:ssa. Vielä tässä vaiheessa tiedonjyväset ovat harvassa, mutta yhtiön mukaan Milan tulee käyttämään samaa paketointia, kuin Rome-palvelinsirut, eli siinä tulee olemaan kahdeksan prosessorisirua (CCD, Core Complex Die) ja I/O-siru (IOD, I/O die).
Prosessori tulee sopimaan tuttuun SP3-kantaan, siinä on kahdeksan DDR4-muistikanavaa ja TDP-arvot tulevat osumaan 120 – 225 watin haarukkaan kuten ennenkin. Dia ampuu lisäksi alas huhut, joiden mukaan Zen 3 -arkkitehtuuri kykenisi suorittamaan neljää säiettä per ydin.
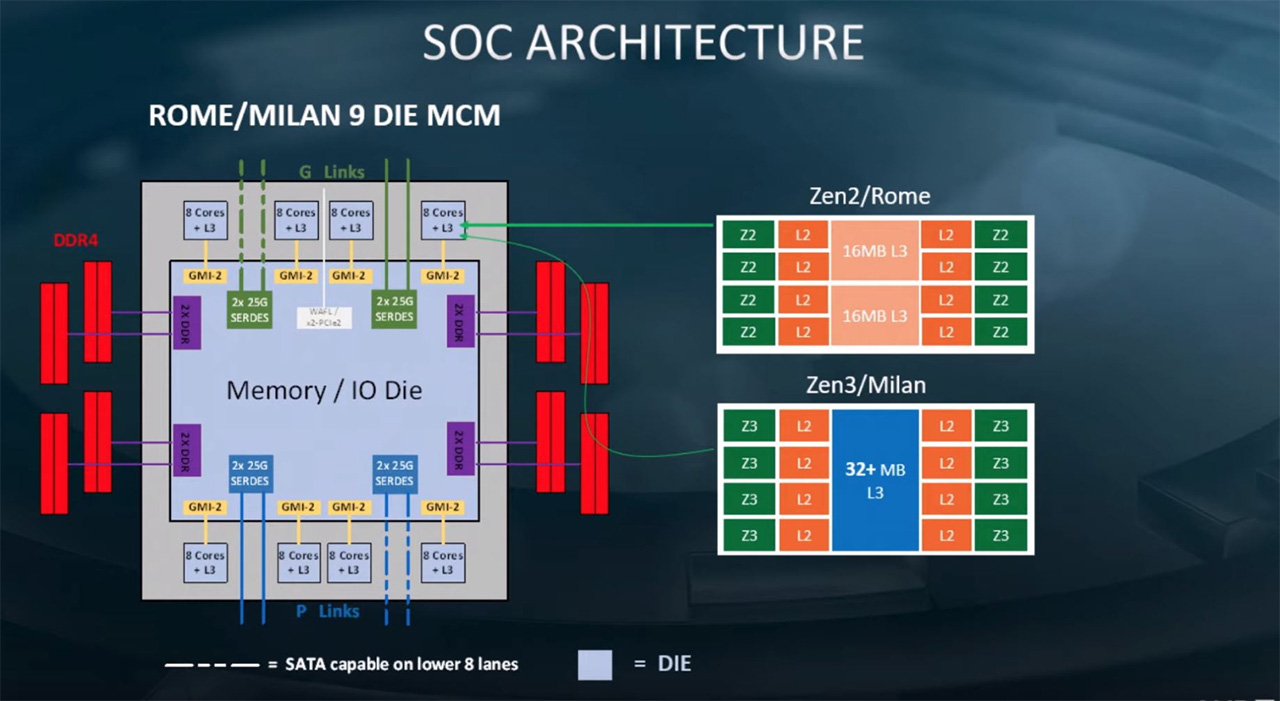
Arkkitehtuuritasolla paljastunut muutos koskee prosessoreiden välimuistia. AMD kertoi tapahtumassa tehneensä merkittäviä muutoksia arkkitehtuurin välimuistirakenteisiin. Siinä missä tähän astisisissa Zen-arkkitehtuureissa kullakin CCX:llä (CPU CompleX, 4 ytimen rypäs) on ollut oma välimuistinsa, tulee Zen 3:ssa saman CCD:n CCX:llä olemaan yhteinen L3-välimuisti. L3-välimuistia tulee olemaan vähintään 32 Mt per CCD, eli ainakin yhtä paljon kuin tällä hetkellä. Yhteinen L3-välimuisti pienentää viiveitä verrattuna tilanteisiin, jossa ydin joutuisi hakemaan tietoa toisen CCX:n L3-välimuistista. Toistaiseksi ei ole tiedossa, onko Zen 3:ssa viilailtu myös muita välimuistirakenteita L3:n lisäksi.
AMD paljasti tapahtumassa lisäksi, että Milan-prosessoreiden tapeout tapahtui jo kuluvan vuoden toisella neljänneksellä. Tämän hetkisen roadmapin mukaan Milan-koodinimelliset palvelinprosessorit saapuvat markkinoille ensi vuonna kuukautta tai paria myöhemmin, kuin Rome tänä vuonna.
Lisäksi tapahtumassa varmistettiin jälleen kerran jo käytännössä tiedetyt seikat Zen 4:stä. Zen 4 -arkkitehtuuriin perustuvan palvelinprosessorin nimi tulee olemaan Genoa ja se on parhaillaan suunnitteluvaiheessa. Genoa tulee sopimaan uuteen SP5-prosessorikantaan ja tukemaan uusia muisteja, mikä tarkoittaa käytännössä varmuudella DDR5-muisteja.
Lähde: Tom’s Hardware
AMD:n Papermaster sanoo Zen2:sta seuraavaa:
"The optimization that we worked with the industry as we first rolled out Ryzen was our core complex," Papermaster said, "We very successfully worked across the OS, with Windows and Linux, so there is a recognition of AMD’s core complex, and so you can really have your workloads leverage that organization. As we go forward into this next-generation with Zen 2-based products, we actually just make it easier because as you have cores going into a common I/O die, it is the same core complex approach that we had before, and you actually just have a very centralized path."[/quote]
Zen2:sta löytyy sama vanha rakenne, joten olennainen pätee tänäänkin ihan täysin. CCX on sama kuin aiemmin ja myös välimuistirakenne on sama siltä osin kuin sanotaan.
Sandy esimerkki oli vain osoittamaan ettei koko cachea ole pakko lukea, kuten väitettiin.
AMD:n tapauksessa kokonaisviive kasvaa tietyissä tilanteissa ja juuri optimoinneilla on paljon merkitystä.
Nyt et kyllä ole ymmärtänyt ollenkaan mitä tuolla on jälkimmäisellä boldauksella on haettu takaa.
Zen/Zen+ threadripperit ja epycit oli tosi pahasti NUMA "vammaisia".
ZEN2 toi suuren parannuksen siinä että jokainen ydin on samanarvoinen dramiin päin huudellessa.
AMD:n sisäisissä arkkitehtuurikuvissa voi aivan hyvin olla ollut 8 ytimen CCX:iä jo vaikka kahden vuoden takaa, kun Zen 3:sta on alettu väkertämään. Emmekä me edes oikeasti tiedä, käyttääkö AMD:n insinöörit koko CCX termiä, vai onko se pelkkää markkinointiosaston keksimää viihteellistä brändäystä. Tämäkään ei yllättäisi.
Tässä ei ole kyseessä nyt edes mikään "industry standard" terminologia, vaan yhden yrityksen (markkinointi)nimi.
@Threadripper nyt loppuu tuo jatkuva vänkäys. Sinä olet väärässä, @hkultala ja muut jotka samaa asiaa sinulle täällä koittaneet tolkuttaa oikeassa. Asiassa ei ole mitään epäselvää tai keskusteltavaa tämän pidemmälle.
Jos ohjelma käyttää useampaa säiettä käsittelemään samoja muuttujia, niin toisen CCX:n L3 cachessa voi muistikirjoitusten hitauden takia olla uudempi versio samasta muuttujasta kuin mitä CCX:n omassa L3 muistissa. Tästä syystä ne pitää aina kaikki koluta läpi säikeistetyissä softissa semmoisten muuttujien kohdalla jotka on merkattu jaetuiksi. toi CCX optimointisetti johon jatkuvasti viittaat perustuu juuri tähän, eli täytä ensin yksi CCX (zen2:ssa 2-4 ydintä, milanissa 100% varmuudella annettujen tietojen mukaan max 8 ydintä), jotta ei jouduttaisi tonkimaan muidenkin CCX:ien L3 cacheja läpi joka kerta kun luetaan jotain yhteistä muuttujaa.
Tossa aika hyvä luento jossa käydään asiaa läpi ilman että tarvii mitään esitietoja perus ohjelmointijargonin lisäksi:
Sandyssä ringbussin takia jotkut latenssit ei oo symmetrisiä. ´ytimien´välinen viive on siis pidempi jos ydin 1 kirjoittaa viestin ytimen 8 luettavaksi verrattuna siihen että ydin 8 kirjoittaisi viestin ytimen 1 luettavaksi, sillä fyysinen etäisyys näille matkoille ydin-L3-ydin on eri mittainen näissä. Zen arkkitehtuurissa crossbarin takia latenssit on aina identtiset CCX:n sisällä identtisten signaalivetojen pituuksien takia. Toi siivuhomma lienee joku erikoinen optimointi, pitäisi lukea jostain tarkemmin että tietäisi mistä on kyse.
Synkronisessa logiikassa, joita kuluttajakäytössä olevista prosessoreista on 100%, ei tarvi signaalivetojen olla "samanmittaisiaja ja identtisiä". Riittää kun saadaan kellonreunalla data talteen.
AMD:n tai Intelin CPU:issa väylät eivät ole asynkroonisia eli signaalijohtmen pituudella ei ole mitään tekemistä montako kellojaksoa kestää hakea data jostain tai kirjoittaa se jonnekin ASIC:n sisällä. Pitkät vedot vaikuttavat ainoastaan maksimitaajuuteen jolla saadaan data fliparilta fliparille kellojakson sisällä. Tämä on digitaalitekniikan peruskauraa.
Ei nyt ihan näinkään. Fliparien välillä signaali liikkuu gigahertsien kellotaajuuksilla erittäin lyhyen matkan. Kuvailemallasi tavalla kaikkien väylien latenssi olisi tasan yksi kellojakso. Jotta signaali saadaan riittävällä nopeudella jollekin L3 cachelle tarvitaan lukuisia rekisteriasteita (tai usean kellojakson yli kulkevia signaaleita) ennen kuin signaali pääsee määränpäähän asti.
Juu oikeassa olet, kunhan yritin esittää asian siten että Threadripper varmasti pysyy kärryillä.
Selitin aika epäselvästi. Minulle "kaikki väylät" eivät ole viiva markkinointipowerpointissa kahden laatikon välillä.
Väylä kahden rekisteriasteen välissä on yleensä se kellojakso (toki multicycle on mahdollista, miten haluaa suunnitella). Rekisteriasteen lisääminen tuo kellojakson viiveen, multicycle puolittaa kaistan.
20 vuotta ASIC suunnittelua taustalla, joten jokin käsitys minulla on miten digitaalinen mikropiiri toimii.
Älä tule pilaamaan asiallista keskustelua varsinkin kun keskustelia käyttää asiallasta kieltä. Todella puolueellista moderointia kun vielä peukutat hkultalan varoituksen/huomautuksen saanutta tekstiä. Ei edes pelisilmää poistaa tykkäystä :facepalm:
@Sampsa tule laittamaan ylläpidon jäsenesi kuriin.
Ei se nyt ihan noin surkeasti mene, Mesi-protokollassa invalidoidaan ei-nykyiset datat muista L3-cacheista ennen kirjoitusta, yhteisen datan lukemisessa cachesta ei hidastuksia ole. Ja jos kirjoitetaan jaettuun dataan paljon ihan sama mikä cache-järjestelmä systeemissä on, suorituskyky sakkaa. Nykyohjemillä CCX-penalti on aika mitätön Zeneissä, suuremman CCX:n etu tulisi pääosin siitä yhden ytimen käytettävissä olevan cachen suurenemisesta.
Threadripperi on vähän ulalla monestakin asiasta mutta L3 Ryzenissä on ydinkohtaista ja jaettu suorilla väylillä neljän ytimen kesken. Muistiosoitteet on multipleksattu eri ytimien L3:n kesken joten keskimääräinen latenssi on sama, AMD itseasissa taitaa sanoa että jokainen ydin saa datan jokaisesta L3:n palasesta samalla viiveellä. Mutta L3 siis on ydinkohtaista, jokaisen ytimen kirjoitukset menevät omaan L3:een ja siitä eteenpäin, tarvitaan vain 6 väylää L3:n palasten välille täydelliseen kytkentään. Mistä päästään siihen miten Zen3:n L3 on toteutettu? Suorat väylät kasvaa eksponentiaalisesti ydinmäärän mukana samoinkuin L3:ssa tarvittavien IO:n määrä joten sama suora kytkentä ydinkohtaisilla L3:lla lienee epätodennäköinen, itse veikkaan ratkaisuksi että kaksi ydintä jakaa L3:n palasen jolloin sama suora kytkentä onnistuu helposti edelleenkin, mutta toki muitakin vaihtoehtoja on.
No enhän minä niin väittänytkään.
Oho, tämä ketju lähti äkkiä kierroksille…
Tai saattaa muutua kun ei tarvi tasapainottaa kahta CCX:ää kun on vain yksi 8 ydin CCX niin voisi tulla prosessoreja myös parittomilla ydinmäärillä eli 7, 5 ja/tai 3 ytimisiä kuluttaja prosessoreja.
Ja kahta chiplettiä käyttäen voisi tulla 14, 10 ja/tai 6 ytimiset prosessorit.