
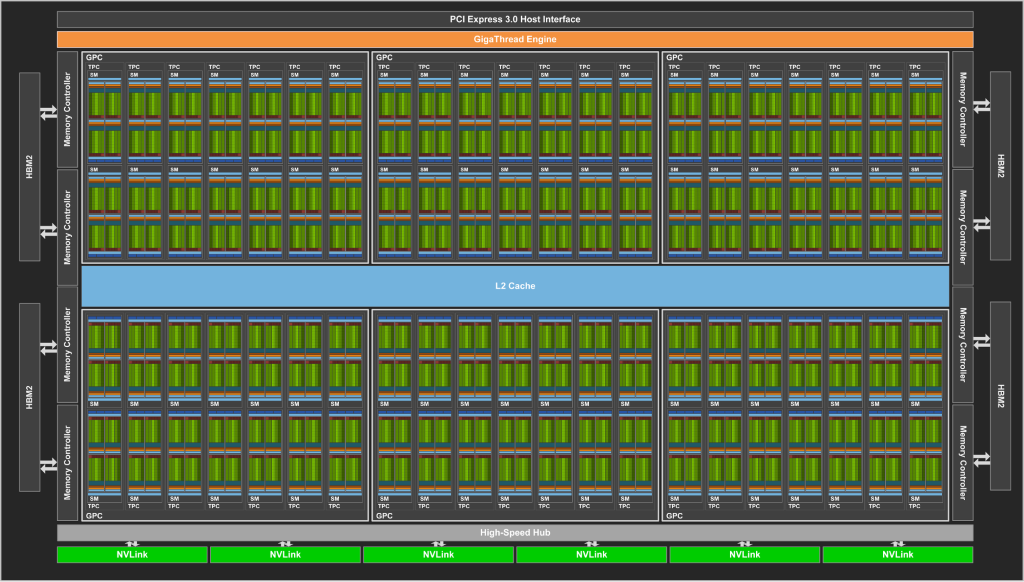
Käytössä on Volta-arkkitehtuuriin perustuva GV100-grafiikkapiiri, joka rakentuu 21,1 miljardista transistorista ja sen pinta-ala on 815 neliömillimetriä. Grafiikkapiiri valmistetaan TSMC:n 12 nanometrin FFN-prosessilla, joka on kustomoitu NVIDIAlle ja piisiru on niin iso kuin valmistuksessa käytettävä fotolitografia tällä hetkellä mahdollistaa.
Tesla V100:n grafiikkapiiri toimii 1455 MHz:n Boost-taajuudella ja siitä on kytketty pois käytöstä neljä SM-yksikköä eli käytössä on 5120 CUDA-ydintä ja 320 tekstuuriyksikköä. Grafiikkapiirin rinnalla on 16 gigatavua Samsungin valmistamaa HBM2-muistia, joka tarjoaa muistiväylän kaistanleveydeksi 900 gigatavua / sekunnissa. Todellisuudessa GV100-grafiikkapiirissä on 84 SM-yksikköä ja erikseen 5376 FP32-ydintä ja 5376 INT32-ydintä, 2688 FP64-ydintä, 672 Tensor-ydintä ja 336 tekstuuriyksikköä.
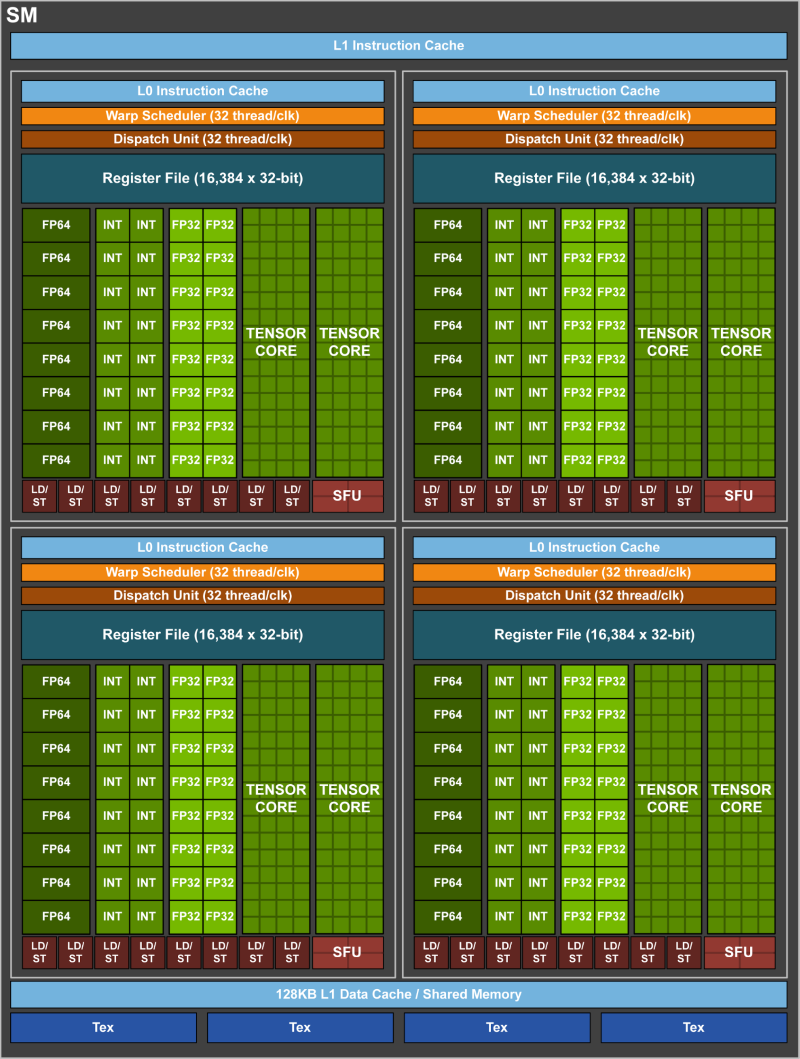
Uutta V100:n SM-yksiköissä ovat Tensor-ytimet. Tensor-ytimet ovat koneoppimiselle pyhitettyjä yksiköitä, jotka ovat erikoistuneet tensoreiden laskentaan. Käytännössä kukin Tensor-ydin suorittaa ”D = A x B + C” -laskutoimituksia 4 x 4 -matriiseilla ja kykenee yhteensä 64 FMA-operaatioon ((Fused Multiply-Add) FP16-kertolasku, FP32-akkumulaatio) kellojaksossa. NVIDIAn mukaan erikoistuneet yksiköt mahdollistavat peräti 12-kertaisen suorituskyvyn viime sukupolven P100:n nähden opetus- ja päättelytehtävissä (FP32) tai kuusinkertaisen suorituskyvyn syväoppimisessa (FP16).
FP32-suorituskyvyksi kerrottiin 15 TeraFLOPSia ja FP64-suorituskyvyksi 7,5 TeraFLOPSia.
SXM2-kokoluokan kiihdyttimessä piirilevyllä on BGA-koteloitu interposer-alusta, jonka päällä on GV100-grafiikkapiiri ja HBM2-muistit. Grafiikkapiirin molemmilla puolin on virransyöttö. Tesla V100 on yhteydessä muihin grafiikkapiireihin NVLink 2-väylän kautta, joka mahdollistaa teoriassa maksimissaan 300 Gt/s tiedonsiirtonopeuden. Maximum Performance -tilassa kiihdyttimen TDP-arvo on 300 wattia.
Tesla V100:n tutkimus- ja kehitysbudjetiksi kerrottiin 3 miljardia dollaria. Kiihdyttimet ovat käytössä muun muassa 149 000 dollarin hintaisessa neuroverkkojen käsittelyyn tarkoitetussa DGX-1V-supertietokoneessa, joka on varustettu kahdeksalla Tesla V100:lla.


Lähde: NVIDIA
Tuo kortti maksaa luultavasti toistakymmentätuhatta dollaria kappale. Jossain väitettiin, että edellistä sukupolvea sai 4kpl / 69000 dollaria ja tuo tuskin on halvempi.
https://devblogs.nvidia.com/parallelforall/inside-volta/
Eipä ole tuollaista termiä tullut vastaan aikaisemmin, mutta tensori ilmeisesti viittaisia koneoppimisessa käytettyihin metodeihin. (Pidemmälle ku lukee niin näköjään kerrotaan vastaus)
Koneoppiminen nyt tällä hetkellä tuntuu olevan se hot-topic, mutta varmaan tuolla on muuallakin käyttöä. Ihan mielenkiintoista nähdä, miten tuo 12nm FFN prosessi vaikuttaa kuluttajakortteihin, sitten kun niitä tulee.
Se tensori vaikutti jonkinlaiselta matriisilaskimelta. Luultavasti noilla ei tee mitään normaalilla GPU puolella.
Custom valmistusprosessi, äärimmilleen viety piirin koko ja 50% Pascalin SM yksikköä paremmalla perf/w? NVIDIA:lla tuntuu olevan liikaa rahaa ja se näkyy R&D ja valmistusteknisellä puolella. :dead:
..mutta Nvidian ensimmäinen Volta-tuote on jo ulkona. Onko tässä enää mitään esteitä Voltan tuomiselle kuluttajille 2018?
Tosin, 3 miljardia ja tuote, joka on markkinoilla alle 3 vuotta.. Kova pitää olla liikevaihto..
Nvidia on sanonut aiemmin että uusi tekniikka tuodaan ammattikortteihin ensin. – kuluttajamalleissa määrää myyyninmäärä, jos kauppa vanhalla käy, ei tuoda vuosiin.
Vaikea nähdä etteikö ainakin GV104 nähtäisi 2018.
Jos AMD:lla on ongelmia HBM2:n riittävyydessä (viittaan tuohon 16 000 kappaleen Vegan julkaisuhuhuun), GTX 1080 Ti on ollut markkinoilla vain hetken ja 11Gbps versiot juuri julkaistu muistakin high-endistä kilpailemaan Vegaa vastaan, niin ei kai tässä kiire ole. Veikkaisin, että optio julkaista vuonna 2017 on jätetty auki, riippuen kilpailutilanteesta, mutta enemmän rahaa tekevät, jos jättävät julkaisun ensi vuoteen.
Ihme kun ei tullut Titan XPP.
Uutiseen päivitetty lyhyt kuvaus Tensor-ytimistä
Skynet askelta lähempänä.
Koneoppiminen, hauska käsite itsessään kun sen ihminen on kehittänyt.
No nyt oli sellainen uutinen josta meikällä meni noin 93% yli hilseen 🙂 Semmoista sanastoa että en tajunnut mitään 😛
Sellainen huomio, että kyseessä on sitten vain parannettu (neljäs) versio tuosta "16nm" prosessista (joka sekin on vain "20nm" + finFET).
Eli transistoritiheyttä ei ole saatu yhtään lisää, mutta virrankulutus/nopeus kyllä paranee hiukan noiden pienten viilausten myötä.
(TSMC päätti uudelleennimetä tuon hiukan viilatun prosessin "12nm" prosessiksi kun se on nopeudeltaan/virrankulutukseltaan parempi kuin GFn/Samsungin "14nm" (mutta selvästi huonompi kuin intelin "14nm")
Taitaa johtua että tuotannon tarkkuus ei ole käytetylle tekniikalla tarpeeksi hyvä. Eli piirit tehdään kuten vapisella kädellä tehtäisiin.
Ihminen on kehittänyt sen koneen, mutta se kone oppii itsenäisesti
Kerro toki mitkä asiat menee yli hilseen niin ihmetellään voidaanko niitä avata kansantajuisemmiksi jotenkin
Tulevaisuudessa varmaan voisi miettiä olisiko kysyntää tai tarvetta artikkelille jossa käytäisiin läpi GPC:t, SM-yksiköt, CUDA ytimet, TMU:t, ROP:t, Compute Unitit, stream-prosessorit ja niin edelleen.
Eli sellainen "selitys artikkeli" missä käytäisiin läpi mitä se näytönohjain tekee, mistä se koostuu, AMD/Nvidia/Intel ympäri pyöreästi muttei välttämättä keskittyen mihinkään tiettyyn arkkitehtuuriin.
Tätä voisi sitten tarpeen vaatiessa päivittää/täydentää ja vastaavissa uutisissa kuten tämä ohjata lukijoita sinne jos heitä kiinnostaa ymmärtää mistä ihmeestä uutisessa puhutaan.
Ehkä myös sitten sisällyttää noita eksoottisempia juttuja kuten Tensor ytimet jos sille on tarvetta.
UKK grafiikkasuorittimista… mikä ettei! Kuulostaa ihan hyvältä. Tai joku muu vastaava formaatti. Wiki tosin vastaa näihin kysymyksiin jo tällä hetkellä, mutta jos tietotekniikka saitilla on ihan oma faq:nsa niin ei siitä haittaakaan ole.
Aivan juu, tästä on ollutkin paljon keskustelua miten nuo prosessileveydet on nykyään vallan harhaanjohtavia. Oli ehkä hiukan retoorinen kysymys. 😆 Tuo "Nvidialle kustomoitu" taitaa myös olla enemmän markkinoinnin sanahelinää kuin mitään täysin mullistavaa.
Jotenkin GPU-rintamalla tuntuu tapahtuvan enemmän kuin CPU-puolella. Poislukien nää AMD:n refreshit ja Nvidian Titan revisiot, ja tietysti Ryzen oli kaivattu piristysruiske. Laskentatehot kasvaa ja virrankulutus pienenee kiitettävästi. Jotenkin odottaa GPU julkaisuja enemmän mielenkiinnolla, vaikka ei kyllä ole itsellä rahaa laittaa noihin high-end kortteihin.
Tuossa englanninkielisessä artikkelissa minkä -SD- linkkasi on aika paljon avattu noita termejä. Itselläkin kyllä menee hiukan yli hilseen nuo warp scheduloinnit, branch divergence handlingit yms, vaikka olen käynyt yliopistolla yhden kurssinkin, missä oli Nvidian arkkitehtuureista.
Eipä kyllä noille kaikille termeille taida suomalaista wikipedia sivua löytyä.
IO-tech wikin paikka? :p
Niin siis ihan yleisesti ottaen iteltäni menee ohi kun ei tiiä mitä noi kaikki jutut tarkoittaa 🙂 En tarkoittanut kritisoida itse uutista mitenkään 🙂
En sitä sillä ajatellutkaan, vaan ihan vain että totta ihmeessä me avataan eri asioita enemmänkin lukijoille jos se vain on mahdollista
Nimi olisi luultavammin Titan Xv :p
Ennen Titan Xv:tä tulee luonnollisesti Titan X (Volta). ?
Tuolla varmaan pyörii nyt myös MATLAB jouhevammin 😛
Ainakin ne muutama GPU-kiihdytetty funktio varmaan. Voin vain kuvitella, kuinka turhauttavaa tuollaisen kanssa olisi profiloida* ja optimoida pois kaikki muut pullonkaulat. "Miksi tämä koodi ei silti nopeutunut juuri yhtään. Äh. Tuo rivi ei rinnakkaistu. Äh. Tuo funktio ei ole tuettu GPU-laskennassa." Ei sillä, heti ottaisin moisen jos jostain sellaisen saisin, vaikka ei mulla sille mitään oikeaa käyttöä olisikaan**.
* Tutkia kunkin koodin osan ajankäyttöä erikseen.
** Joskus vähän olen klusterilla laskenut asioita, ja onhan se ihan siistiä ajaa samalla kertaa 400 kopiota erittäin laiskasti optimoitua Matlab-koodia, sen sijaan, että olisi tarvinnut optimoida koodi nopeaksi.
PS. Niille joille Matlab ei ole yhtään tuttu, se on sellainen kaupallinen skriptikieli. Huonosti kirjoitetun ja hyvin kirjoitetun koodin nopeusero on enemmän kuin joku kerroin 1000. Huono, hitaampi kuin Python; hyvä, nopeampi kuin mitä itse ikinä jaksaa optimoida oman C++-koodin kulkemaan (siis käyttäen AVX, SSE, … ja muut epä-koodaustavat).
Matlab on kuitenkin tuotenimi vähän samaan tapaan kuin kutsuisi Visual Studiota kieleksi. Varmaan tarkoitit Matlabin C:tä muistuttaavaa M kieltä? Siitä kun viimeksi olen Matlabia käyttänyt alkaa kyllä olemaan niin kauan että ehkäpä kielen nimeksi on vakiintunut Matlab, tiedä häntää …
Tiedän prosessorisuunnittelusta tasan tarkkaan nolla, mutta olisiko periaatteessa mahdollista suunnitella/vaihtaa fyysisellä tasolla nuo INT, FP64 ja tensorytimet FP32 ytimiksi saaden tällä tavoin ~25k FP32 ytimellisen monsteripiirin?