
Apple kertoi aiemmin tänä vuonna tulevansa julkaisemaan ensimmäisen yhtiön omaan järjestelmäpiiriin perustuvan Mac-tietokoneen vielä tämän vuoden aikana. Tänään pidetyssä julkaisutilaisuudessa yhtiö julkaisi paitsi uudet Macit, myös niiden järjestelmäpiirin, M1:n.


Apple M1 -järjestelmäpiiri rakentuu yhteensä 16 miljardista transistorista ja se valmistetaan 5 nanometrin prosessilla. Se hyödyntää poikkeuksellista ratkaisua, jossa muistipiirit on istutettu samaan Applen suunnittelemaan paketointiin itse järjestelmäpiirin kanssa. Yhtiö ei tarkentanut, paljonko tai mitä muistia järjestelmäpiirin tukena on, mutta kehuu ratkaisun tarjoavan sekä reilusti muistikaistaa että matalat viiveet. Yhtiö valmistaa järjestelmäpiiristä ilmeisesti kahta eri versiota, joista toisessa on 8 ja toisessa 16 Gt HBM-muistia. Päivitys: Applen Suomen sivuilta löytynyt maininta HBM-muisteista on ilmeisesti virheellinen ja kyseessä on todellisuudessa LPDDR4X-muistit.

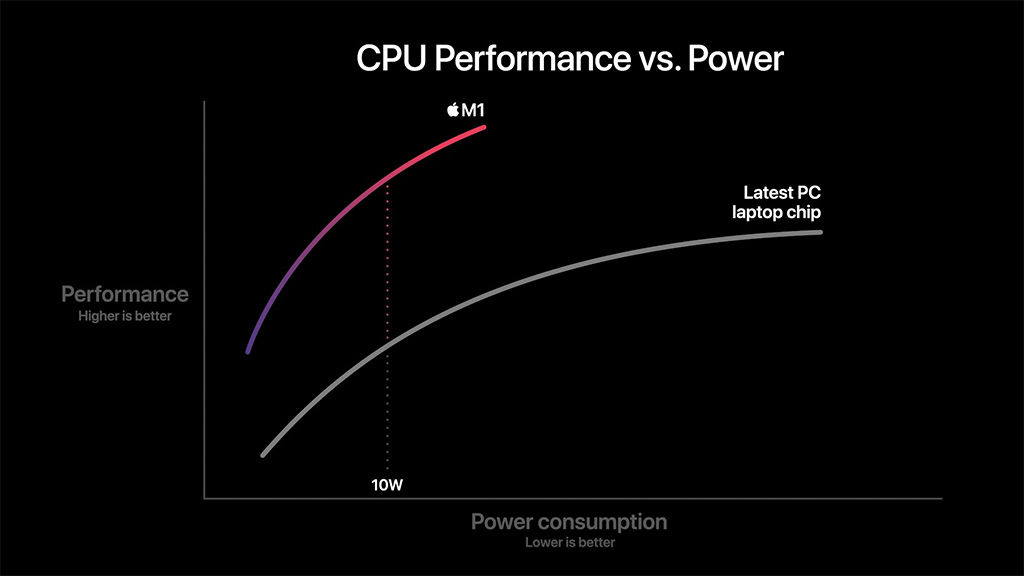
Järjestelmäpiirissä on neljä tehokasta prosessoriydintä erittäin leveällä arkkitehtuurilla ja yhteisellä 12 megatavun L2 -välimuistilla sekä neljä energiatehokasta kapeammalla, mutta edelleen leveällä arkkitehtuurilla ja 4 Mt:n jaetulla L2-välimuistilla. Applen mukaan sen tehoydin on maailman tehokkain prosessoriydin ja M1 tarjoaa parasta prosessorisuorituskykyä per watti. Yhtiön mukaan sen suorituskyky MacBook Airin 10 watin TDP:llä on kaksinkertainen ”viimeisimpään PC-kannettavien siruun” verrattuna.

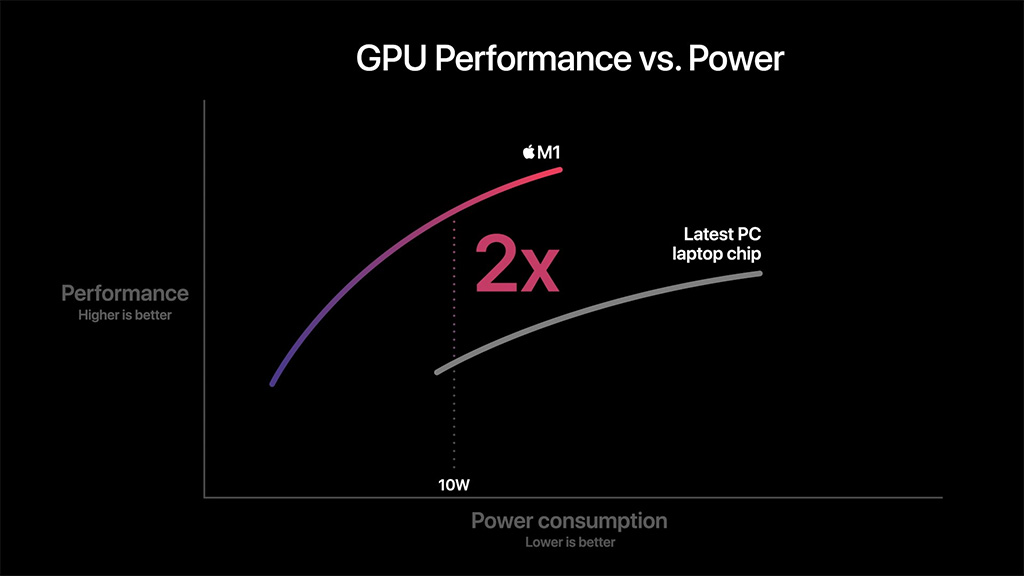
Järjestelmäpiirin grafiikkaohjain on 8-ytiminen ja sisältää 128 suoritusyksikköä. Se kykenee suorittamaan parhaimmillaan 24 576 säiettä samanaikaisesti ja tarjoaa jopa 2,6 TFLOPSin laskentatehon. Applen mukaan kyseessä on maailman nopein integroitu grafiikkaohjain, mikä pitää paikkansa ainakin teoreettisen laskentatehon osalta. Yhtiön omien testien mukaan M1 tarjoaa myös grafiikkasuorituskykyä kaksinkertaisesti ”viimeisimpään PC-kannettavan siruun” verrattuna 10 watin TDP-arvolla.
M1:een on integroitu myös 16-ytiminen Neural Engine tekoälytehtäville, kehittynyt ISP-kuvaprosessori, median pakkaus- ja purkuyksiköt sekä Thunderbolt / USB 4 -ohjain. Mukana on luonnollisesti myös Applen Secure Enclave -tietoturvaprosessori sekä tuki PCI Express 4.0 -standardille, mitä hyödynnettäneen ainakin NVMe-tallennustilan kanssa.
Lähde: Apple
Ensinnäkin, sen TAG-taulukon koko, mistä se tarkastus tehdään, on 4-kertainen, mikäli välimuistilinjan koko on sama.
Toisekseen: Sen kunkin välimuistitien data-arrayn koko on myös 4-kertainen.
Kun muisti on 4 kertaa isompi, se tarkoittaa 2 kertaa suurempaa molemmissa dimensioissa. Datan kulkeminen kauimmaisesta nurkasta kestää tällöin 2 kertaa kauemmin. Lisäksi samassa johdossa on enemmän kytkentöjä, mikä vaatii vahvemmat transistorit niitä ajamaan.
Että se välimuisti ei todellakaan ole "sama".
Lisäksi se L1D-access on osa sitä prosessorin liukuhihnaa. Ihan samanlailla se on jaettu liukuhihnavaiheisiin kuin kaikki muukin. Käytännössä menee (noiden kolmen näkyvän vaiheen osalta) suurinpiirtein siten, että ekassa vaiheessa lasketaan osoite, toisessa vaiheessa 1) aloitetaan TLB lookup sekä sen kanssa rinnakkain 2) way prediction ja aloitetaan sen jälkeen sen perusteella access jonnekin rinnakkain sekä data- että tag-arrayhin, kolmannessa vaiheessa sitten saadaan TLB-lookupin tulos, verrataan sitä TAGiin ja sen perusteella joko annetaan luettu data eteenpäin tai nostataan pystyyn hutiflägi.
Tässä on aika monta (osittain peräkkäistäkin) asiaa tehtäväksi aika pienessä ajassa. Se, että esim. way predictionille voidaan pyhittää oma vaihe ja aloittaa accessit sinne data- ja tag-arrayihin heti seuraavan kellojakson alussa (eikä vasta kellojakson loppupuolella) voi helpottaa aika paljon sitä millä kellojaksolla homma vielä toimii. Ja mitä enemmän on aikaa TLB-lookupille, sitä isompi (ja paremman osumatarkkuuden omaava) ensimmäisen tason DTLB ytimelle voidaan laittaa
Intelillä joissain prossuissa taitaa nuo muistiaccessien liukuhinavaiheet mennä siten, että yksinkertaisemmilla osoitusmuodoilla osoitteenlaskennalle on yksi vaihe ja L1D-viive on 4 kellojaksoa, monimutkaisemmilla osoitusmuodoilla osoitteenlaskennalle on kaksi vaihetta, L1Dn kokonaisviive tällöin 5 kellojaksoa.
Mutta eikös ollut jotain että liian pitkä liukuhihna heikentää IPC arvoa, näinhän kävi ymmärtääkseni netburstin arkkitehtuurin kanssa, kun tehtiin jotain kompromissejä, jotta saadaan kovat kellotaajuudet.
Liukuhihnan pituus vaikuttaa käytännössä aina haarautumisennustushudin pituuteen, eli siihen, että kuinka paljon keskeneräistä työtä joudutaan heittämään menemään ja kuinka monen kellojakson päästä saadaan taas prossun liukuhihnalla käskyjä suoritukseen asti.
Lisäksi pidempi liukuhihna tarkoittaa pidempiä viiveitä joillekin käskyille(yleensä yksinkertaisilämmilla käskyillä on silti vain yhden kellojakson viive), eli aiemman käskyn tulosta odottavat käskyt joutuvat odottelemaan kauemmin.
Mikäli kellotaajuus skaalautuisi suoraan liukuhihnavaiheiden suhteessa, kumpikaan näistä ei olisi hidaste, kun niihin ei absoluuttista aikaa menisi sen enempää.
Mutta koska kellotaajuus ei skaalaudu suoraan liukuhihnavaiheiden määrän mukaan, nämä hidastavat.
Pentium4lla suurin ongelma liian pitkästä liukuhihnasta oli kuitenkin siinä, että siinä jouduttiin tietyt asiat toteuttamaan "huonommin" koska niitä ei vaan voinut liukuhihnoittaa enempää tai niiden liiallinen liukuhihnoitus monimutkaisti aisoita selvästi:
1) p4n L1D-välimuisti oli läpikirjoittava eli kun sinne kirjoitettiin, kirjoitus meni heti L2lle asti. Tämä mm. aiheutti turhaa liikennettä (mm haaskasi virtaa). Bulldozerissa sama juttu.
2) Käskyskedulerin liukuhihnoitus on hyvin ongelmallista kun skedulointi pitäisi tehdä sen mukaan, stallaako aiempi käsky jolta dataa odotellaan vai ei, mutta se voi stallata liian myöhään. p4 oli optimisti ja skeduloi käskyt oletuksella että aiempi käsky ei stallannut. Ja jos se stallasi, siltä saatiin väärä arvo. Jolloin jo skeduloidun ja suorituksessa olevan käskyn suoritus piti perua ja tämä käsky suorittaa uudelleen myöhemmin. Haaskattiin sekä suorituskapasiteettia että virtaa.
Ja niin, p4n nopeat alut joilla ei sinänsä ollut mitään tekemistä pitkän liukuhihnan kanssa tarkoitti sitä, että bit-shiftaukset oli hitaita. Ja maailma sattui olemaan täynnä koodia jossa bitshiftausta käytettiin esim kahdella tai neljällä kertomiseen (tämä olisi p4lla ollut nopeampaa yhteenlaskulla)
Apple Silicon M1 Chip in MacBook Air Outperforms High-End 16-Inch MacBook Pro
http://www.macrumors.com
Ja jos ensi vuonna tulee vielä useamman ytimen malleja, niin lisää jytkyjä on kyllä luvassa.
Kyseiset testit on ajettu Geekbenchin macOS AArch64-versiolla eli natiivilla ARM-softalla. Olisi mielenkiintoista nähdä tuloksia myös macOS x86 (64-bit) versiolla, että saisi jotain käsitystä Rosetta2:n toimivuudesta.
Joo, joku 12-16 core versio 32-64GB tuella kun tulee niin voi tehokäyttäjätkin ja yrityksetkin alkaa näitä laittamaan.
Koko mäsän ja googlen pakka toiminee hyvin heti julkaisussa, alkuvuodesta sit loput isommat softatalot perässä. Perus toimistohommiin ei nykyään kauheasti noiden lisäksi tarvitse mitään.
Apple on vaihtanut arkkitehtuuria jo aika monta kertaa (MC68000 -> PPC -> x86 -> ARM), ja nuo siirtymät ovat olleet jälkeenpäin ajatellen yllättävänkin kivuttomia käyttäjän kannalta (itsellä ollut aktiivikäytössä noita kaikkia, paitsi luonnollisesti tätä uusinta). Yhteensopimattomuudet on hoidettu emulaattorilla ja koska uusi rautasukupolvi on ollut vanhaan verrattuna niin nopeaa, ei se ole menoa haitannut. En siis keksi, miksi nyt olisi toisin. Joidenkin yksittäisten, rautaa lähellä olevien softien kanssa voi toki olla toinen tilanne.
Microsoft julkaisu jo arm-betan MS Office for Mac:stä eilen illalla, eli natiiviversio varmaan tulossa suht nopeasti. Ehkä jopä ennen vuodenvaihdetta.
Developer Transition Kit (A12Z)
Noiden lukujen perusteella suorituskyky putoaa Rosetta2:lla single coressa 26% ja multi coressa 39%.
Ja Office-softia tosiaan esiteltiin jo WWDC:ssä Apple Siliconilla.
Ainakin vielä tuolloin oli huhuja että kyse oli Rosetta-versiosta
Jotenkin ihanaa, että alan huhut on tasoa "microsoft office muuten pyöri wwdc 2020:n aikana apple silicon -laitteilla oikeasti rosetta 2 -versioina".
Ei minulla mitään asiaa varsinaisesti ollut. Joskus vaan lämmittää huomata kuuluvansa johonkin ihmisryhmään kuin kotiinsa.
Onneksi Officen Web-sovellukset ovat parantuneet huomattavasti ja asennettavien softien tarve pienenee jatkuvasti. Excelissä on tiettyjä ominaisuuksia, joita ei ole online-versiossa, samoin jos on Outlookissa jotain talon sisäisiä plugareita yms. Muussa tapauksessa antaisin online-versioille mahdollisuuden. "Sotkisin" konetta asennuksilla vasta siten kun jokin asia ei oikeasti toimi.
Kumma jos mainostavat tuota natiivina appsina, jos emuloituna pyörii
Jaha, video oli timestampattu sen jälkeen kun tuo sanottiin
Jotekin olen siinä käsityksessä, että Applella on nyt oma rauta ja omat rajapinnat joita vasten sovellukset pitää koodata. Joten mitään muuta alustariippumatonta tapaa tuoda sovelluksia ei ole kuin selainpohjaiset? Ja siinäkin varman ios tyyliin pakotetaan kaikki käyttämään Safarin moottoria , joten Apple loppupeleissä päättää senkin osalta mikä pyörii ja mikä ei.
No enpä tiedä. Jos tekee sovelluskehitystä applen työkaluilla niin tuo tapahtuu kuulemma jotakuinkin automaattisesti. Lisäksi diehard applefanit, jotka on enemmän tai vähemmän vastuussa suurimmasta osasta softakehityksestä kyseisellä alustalla, ovat varmaan ensimmäisenä jonossa vaihtamassa uusiin laitteisiin niiden nopeuden takia. Veikkaan että tammikuuhun mennessä 99% käytetyimmistä softista löytyy natiivituella.
Apple's M1-Based MacBook Air Benchmarked
http://www.techpowerup.com
Tulokset oli linkattu jo ylempänä mutta single coressa M1 näyttäisi olevan kaikkein nopein CPU ja multi core tulos on Ryzen 5 3600X:n tasoa. Tuloksissa kannattaa tosin huomioida ARM vs. x86 eroavaisuus sovellusversiossa. Jos joudutaan emuloimaan, niin M1 ottaa todennököisesti hittiä 30-40% suorituskyvyssä.
MacOS on posix-yhteensopiva käyttöjärjestelmä, joten melkein kaikki yleisimmät linux-sovellukset saa nappia painamalla käännettyä toimimaan Mac:lle. Ongelmia muodostaa lähinnä GUI-osuus, joskin Mac:lle on ainakin aikaisemmin saanut X11-libraryt, joilla monet linux-ohjelmat toimivat suoraan. Yksi mitä olen joskus käyttänyt on wireshark.
Toki käyttöjärjestelmien tarjoamat API-kutsut eivät sitten ole suoraan yhteensopivia.
Mahtaakohan multicore-testissä tulla TDP vastaan? Toisaalta tietty neljä ydintä on niitä vähemmän järeitä (mutta toisaalta vähän virtaa kuluttavia).
Geekbench on ainakin mobiililla sen verran lyhy testi, että jos kylmällä koneella ajaa, niin lämmöt tuskin tulevat ensimmäisellä ajolla vastaan.
Turbot ovat todennäköisesti Macbook Airissa pistetty ylemmäs kuin minne sustained-clockit taipuvat, joten pitäisi testata sekä first-run lukemat, että sustained-lukemat pidemmän ajamisen jälkeen.
Onko mahdollista rakentaa tuollaista Apple tyylistä x86 prossu ydintä jossa olisi yhtä kova IPC kuin Applella alhaisella virrankulutuksella? Anandtechin arittekeleista olen saanut kuvan, että ARM käskykannalla se on muka jotenkin helpompaa kuin x86:lla.
Ja jos sellaisen x86 prosessorin voisi tehdä, niin miksi ei ole tehty? Toki Intel mikroarkitehtuuri kehityksessään nosti jalat pöydälle Sandy Bridgen jälkeen ja AMD lähti Bulldozer harharetkilleen. Nyt Ryzenin myötä x86 maailmassa oikeasti viimein tapahtuu jotain kehitystä.
Kiitoksia erinomaisesta vaikkakin pitkähköstä vastauksesta. Loppukaneetti sisälsi sen olennaisen. Olen kyllä lukenut digitaalisuunnittelua ja mikroelektroniikkaa. Opinnoista alkaa olla vaan yli 20v aikaa ja välissä olen tehnyt jotain ihan muuta.
Olet nyt toistanut tätä aika monta kertaa aivan kuin x86-emulointi olisi jotenkin jatkuvasti pakollista.
Jos nyt tänään tilaa uuden mäkin, niin joo, joutuuhan sitä muutaman viikon/kuukauden emuloimaan jotain, mutta kun joskus ensi keväänä konetta käyttelee, niin monella käyttäjällä menee päiviä tai viikkoja ilman, että yhtääm x86-executablea käynnistyy.
Toki jos tietää tarvitsevansa erikoisempaa softaa, niin tilanne on eri, mutta miksi silloin edes harkitsisi arm-mac:n ostoa? Tai miksi ei harkitsisi softan vaihtoa?
Ei sitä emulointia tietenkään joudu jatkuvasti tekemään mutta ihan hyvä sen vaikutus on tiedostaa. M1 on aivan ylivertainen piiri jos ja kun sovellukset ovat saatavilla ARM:lle käännettynä ja Rosetta2 toimii sulavasti tarpeen vaatiessa. Siinä vaiheessa, kun Apple korvaa Intelin prosessorit myös iMaceissä, niin muutosvaihe ollaan varmaan saatu tehtyä.
Huono juttu, suljettu ympäristö. Et voi paljon iloita siitä. T. MacBook käyttäjä.
Jos tämä on verrannollinen keskimääräiseen suorityskykyyn kautta ohjelmistojen, niin melkoinen pommi on tarjolla. Alkaa houkuttelemaan Apple läppäriksi, enää tuo suljettu ekosysteemi pidättelee. Muuten olisi luottokortti jo vedetty tappiin
Jos tosiaan tuo virrankulutus / tehosuhde on noin hyvä kun väitetään, niin täälläkin hypätään kyllä Applen kelkkaan läppäreissä mahdollisesti – tosin vasta siinä vaiheessa kun Apple laittaa kosketusnäytön noihin Aireihin.. Montakohan vuotta pitää sitä odotella vielä, 2-4v? "The next big thing".
Jos haluat kosketusnäytön, niin osta iPad Pro 12” + magic keyboard.
Siitä on tulossa lähes varmasti versio tuolla M1 piirillä kunhan ehtivät julkistaa.
Eipä taida tabletista olla siihen vähäänkään ohjelmointiin mille on tarvetta?
Olettaisin Applen oman piirin rajaavan vapauksia enemmän ios hengessä. Ei varmaan Safari pakotuksia vielä kuitenkaan. Bootcamp lähtee ja jatkossa varmaan hackintoshitkin kun käyttis pyörii vain tietyllä alustalla.
Chromebookit ovat taas Google-sidonnaisia ja se taas jakaa mielipiteitä. Uskalttaisin väittää että MacBookeissa on yleisesti parempi rauta mitä tulee esim. näyttöjen paneelien laatuun, isoihin resoluutioihin, touchpadin toimintaan ja tuntumaan yms asioihin. Siinä olisi Googlella hyvät saumat tarjota "parempaa" vaihtoehtoa, panostamalla tuotevalikoimiin ja mm. premium-luokan mallistoon.
Toisaalta taas jos kaikki toimii, mikäpäs siinä. Selainpohjaisissa sovelluksissa on sekin etu että niiden tietoturva on mitä todennäköisemmin paremmalla tasolla, kuin paikallisten sovellusten, joita yleensä ajetaan "Yes, yes…"-periaatteella. Eiväthän nekään tietty ole 100% tietoturvallisia, mutta niissä on kuitenkin huomattavasti vähemmän tartuntapintaa kuin admin-tasoisella tunnuksella ajettu sovellustiedostolla.
Mitä rajoituksiin tulee, toivottavasti eivät lähde liikaa rajoittamaan esim. selainten engineiden osalta. iOS:n puolella olivat jopa löystäneet sääntöjä sallimalla vaihtamaan oletusselaimen ja mm. sähköposticlientin. Tämä on toki hieman eri asia mutta "toivoa on".")
Miksi se oma piiri rajaisi yhtään mitään?
Edelleen suuri osa ohjelmistosta muuttuu seuraavalla tavalla Arm:lle:
Editoit yhtä riviä konffifilestä ja käännät uudelleen. Ulos tuleva softa on arm-versio x86-version sijaan.
Chromebookit on aivan eri hintaluokassa. Selainpohjaiset sovellukset ja tietoturva taas eivät sovi samaan lauseeseen.
mikä ympäristö näin hyvin toimii?
macOS 11.0 Big Sur compatibility on Apple Silicon · Issue #7857 · Homebrew/brew
github.com
Esim. Tuolla on listaa asioista jotka toimivat jo nyt natiivina. Aika moni asia toimii, vaikka dev-kittejä on OS-devaajilla varmasti todella vähän.
Se tarkoittaa, että moni projekti on kääntynyt käytännössä ilman isompia ongelmia, muuten paljon harvempi juttu toimisi.
Hintaerosta huolimatta mainitsemani erot ja edut ovat silti olemassa.
Vai niin.")
Bootcamp toki lähtee (ei tolle taida microsoftilla olla binääriäkään mitä asentaa), mutta muista nykyisestä poikkeavista rajoituksista ei ole mitään havaintoja. Ihmettelisin jos haistattaisivat paskat alustalla oleville kehittäjille.
jos on laittaa muutama sata euroa päätelaitteeseen niin se ei lämmitä että sillä tuhannella eurolla jota ei ole saisi parempaa rautaa.
Edelleenkin oletat että TLB-lookup tehdään yhdessä muistihaun kanssa – ei varmana tehdä, data voidaan lukea sieltä cachesta paljon vähäisemmän informaation perusteella ja tarkistaa osuman oikeellisuus vaikka käskyn retire-vaiheessa. TLB-käännökset ja täyden osoiteavaruuden käyttäminen olisi puhdasta typeryyttä.
AMD on dokumentoinut uTaginsa vielä hyvin, ei siinä pitäisi olla epäselvää. Ja load-store forward on dokumentoitu myös, forwardoinnissa käytetään vain alinta 12 osoitebittiä, loput tarkastetaan myöhemmässä vaiheessa.
Vanhemmat Applen ytimet on dokumentoitu, eli ensimmäiset 64-bittiset versiot oli 16-19 pituisilla liukuhinoilla. Tuolloin tosin ydin oli paljon pienempi, eli liukuhihnoitusta on melkoisen varmasti jouduttu lisäämään jotta esimerkiksi käskyjen fetchaus 4-kertaiseksi kasvaneesta puskurista tai rekisterien luku/kirjoitus 4-kertaa suurempaan ja tuplasti moniporttisempaan rekisterifileen kasvaisi muuten joko liian hitaaksi tai liian energiatehottomaksi – näillä data-arraylla on huomattavasti enemmän ongelmia skaalautua suuremmiksi kuin cacheilla jotka voidaan raudalla helposti pilkkoa pienempiin osiin. Muistelen nähneeni joku vuosi sitten silloisesta Applen ytimestä(12?) analyysin jossa saatiin liukuhinan pituudeksi määriteltyä 25-30.
Näinpä. Ihan kiinnostavaa nähdä millä aikataululla kehitystyökalut saapuvat ARM-käännettyinä – itselleni riittäisi kun olisi Docker, relevantit Java openjdk-versiot sekä Intellij IDEA.
Vaihtui kyllä juuri työläppäri muutama viikko sitten uuteen, että joutaahan tässä taas 3 vuotta odottelemaan.
Tervetuloa, uudet sivukanavahyökkäykset, ja tervetuloa, hyvin paljon virtaa tuhlaava ja suorituskykyä hukkaava replay-mekanismi kaikille L1-misseille. Jooei.
Ja joo, siellä Zenissä kyllä on se replay-mekanismi store->load-forwardeille, mutta hyöty siitä store-load-forwardingista on oikeasti suuri, ja sen false positive-hudit (jotka johtaa sen replayn aktivoitumiseen) on oikeasti hyvin harvinaisia, ja sen toteutus ilman sitä olisi oikeasti selvästi hankalampaa, kun siellä pitää vertailla joka kellojakso vertailla parin latauksen osoitteita kaikkiin store-puskurissa oleviin storehin(zen1:llä 44 kpl))
Se, että joku on teoriassa mahdollista ei tee siitä järkevää, kun suorituskyky- turvallisuus- ja virrankulutushaitat olisi moninkertaiset hyötyihin nähden.
L1-osuman tarkastaminen vasta retiressä olisi TODELLA HIDASTA, kun se retire voi tapahtua kymmeniä kellojaksoja myöhemmin ja sen latauksen jällkeen voi olla spekulatiivisesti suoritettu kymmeniä muita ladatusta datasta riippuvaisia käskyjä. KAIKKI NÄMÄ pitäisi heittää mäkeen ja replyttää nekin.
Käskyjen uudelleenjärjestyksen oleellinen hyöty tulee siitä, että kun tulee välimusitihuti, sitten skeduloidana suoritukseen niitä käskyjä jotka ei ole riippuvaisia siitä datasta, jonka lataus kestää.
Se, että sitä hutia ei huomattaisi ja käskyskedulerille olisi aivan samanarvoisia käskyt joiden inputit on roskaa aivan toisesta osoitteesta (eikä ehkä edes roskaa vaan ehkä jopa sivukanavahyökkääjän tarkoituksella valmistelemaa hyökkäyspayloadia) ja jotka pitää heittää mäkeen, ja käskyt, joiden inputit on oikeasti sitä dataa mitä sen kuuluukin olla pilaisi aika paljon koko siitä pointista miksikäskyjen uudelleenjärjestely on niin kova juttu.
Ja joo, P4ssa oli replay L1D-misseille. Siinä se oli sen takia, että sen käskyskeduleri oli liukuhihnoitettu ja sitä tietoa siitä datan tuottavan loadin välimuistin osumasta tai hudista ei vaan ollut millään saatavilla siinä vaiheessa kun käskyskeduleri sitä tarvitsi. Siinä se tieto tuli (vain) yhden kellojakson myöhässä mutta silti ne replayt mitä se aiheutti sekä huomattavaa virrankulutuksen lisääntymistä että suorituskyvyn hidastumista, ja on juuri niitä olelellisia syitä miksi P4 oli niin huono kuin se oli.
Yksi P4n oleellisista opeista oli: L1D-hutiin ei haluta replaytä. Ja P4ssa siihen replayhin oli parempi syy (se liukuhihnoitettu käskyskeduleri) kuin millään uudellö prossulla olisi.
Puhdasta typeryyttä on amatöörinä haukkua typeriksi ammattilaisten ratkaisuja, jotka on ainoita järkeviä ratkaisuita, kun amatöörin oma ymmärrys perustuu ei riitä tilalle tarjoamiensa vaihtoehtoisten "ratkaisujen" ongelmien ymmärtämiseen.
Ei ole edes kahta vuotta siitä kuin kutsuit intelin insinöörejä käytännössä idiooteiksi kun niiden prossuilla onnistuu meltdown-sivukanavahyökkäys mutta nyt ehdotat itse ratkaisua joka aiheuttaa vaan vielä pahempia sivukanava-aukkoja ja samalla kutsut typeräksi toimivaa ja nopeampaa (ja oikeasti joka paikassa käytössä olevaa) ratkaisua jossa näitä sivukanava-aukkoja ei ole.
Kumpikos meistä suunnitteleekaan työkseen prosessoriytimiä, ja kumpi meistä ei ole opetellut prosessoriarkkitehtuureista edes alkeita missään yliopistossa tms. mutta yrittää sen sijaan päteä lukemalla hyvin spesifistä nippelitietoa jonka ymmärtää hyvin usein väärin?
Joo, siitä on dokumentoitu hyvin, että sitä käytetään way predictioniin. Tässä ei ole mitään epäselvää.
Sen sijaan olet ihan omasta päästäsi kuvitellut että se korvaisi koko tagin, mitä se ei tee.
Ja pidät sitä vielä "aivan varmana" tajuamatta yhtään mitä kaikkia ongelmia se aiheuttaisi.
Lähteitä näihin dokumentteihin?
Miten kuvittelet sen rekisterifileen tai käskypuskurin lukemisen liukuhihnoittavasi?
Ja väitän tietäväni aika paljon sinua paremmin, miten rekisterifileen koko ja porttimääärä vaikuttaa sen kokoon ja nopeuteen – olen oikeasti työkseni optimoinut näitä asioita.
Ja joo, välimuistin voi pilkkoa pienempiin osiin, mutta se ei tuo sitä kaukana olevaa dataa yhtään lähemmäksi, ja tarvitaan silti muxit väliin valitsemaan, mistä palasta sitä dataa haetaan.
Mutta rekisterifileestäkin voi tehdä monipankkisen, tosin sitten pitää olla keino hanskata pankkikonfliktit, ja tämäkin menee helposti hyvin monimutkaiseksi.
Jospa nyt vaan laittaisit sitä linkkiä niihin lähteisiin tämän mutun sijaan.
Minäkin muistan joskus jostain lukeneeni, että muistiosoitteet osoittaa yksittäisiin bitteihin eikä tavuihin, taisin kuulla sen joltain internetin luotettavimmalta lähteeltä jonka nimikirjaimet oli "SR".