
Apple kertoi aiemmin tänä vuonna tulevansa julkaisemaan ensimmäisen yhtiön omaan järjestelmäpiiriin perustuvan Mac-tietokoneen vielä tämän vuoden aikana. Tänään pidetyssä julkaisutilaisuudessa yhtiö julkaisi paitsi uudet Macit, myös niiden järjestelmäpiirin, M1:n.


Apple M1 -järjestelmäpiiri rakentuu yhteensä 16 miljardista transistorista ja se valmistetaan 5 nanometrin prosessilla. Se hyödyntää poikkeuksellista ratkaisua, jossa muistipiirit on istutettu samaan Applen suunnittelemaan paketointiin itse järjestelmäpiirin kanssa. Yhtiö ei tarkentanut, paljonko tai mitä muistia järjestelmäpiirin tukena on, mutta kehuu ratkaisun tarjoavan sekä reilusti muistikaistaa että matalat viiveet. Yhtiö valmistaa järjestelmäpiiristä ilmeisesti kahta eri versiota, joista toisessa on 8 ja toisessa 16 Gt HBM-muistia. Päivitys: Applen Suomen sivuilta löytynyt maininta HBM-muisteista on ilmeisesti virheellinen ja kyseessä on todellisuudessa LPDDR4X-muistit.

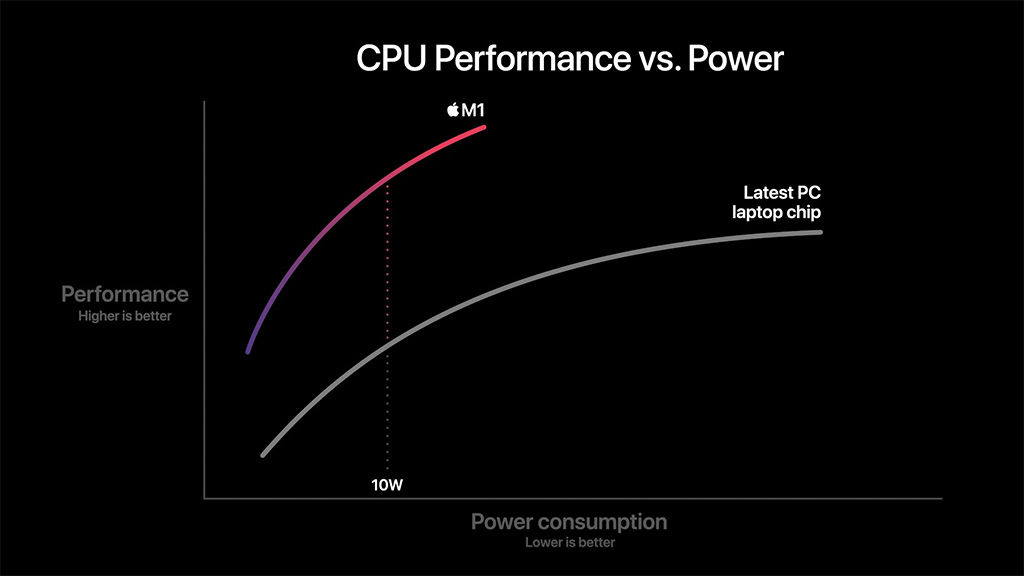
Järjestelmäpiirissä on neljä tehokasta prosessoriydintä erittäin leveällä arkkitehtuurilla ja yhteisellä 12 megatavun L2 -välimuistilla sekä neljä energiatehokasta kapeammalla, mutta edelleen leveällä arkkitehtuurilla ja 4 Mt:n jaetulla L2-välimuistilla. Applen mukaan sen tehoydin on maailman tehokkain prosessoriydin ja M1 tarjoaa parasta prosessorisuorituskykyä per watti. Yhtiön mukaan sen suorituskyky MacBook Airin 10 watin TDP:llä on kaksinkertainen ”viimeisimpään PC-kannettavien siruun” verrattuna.

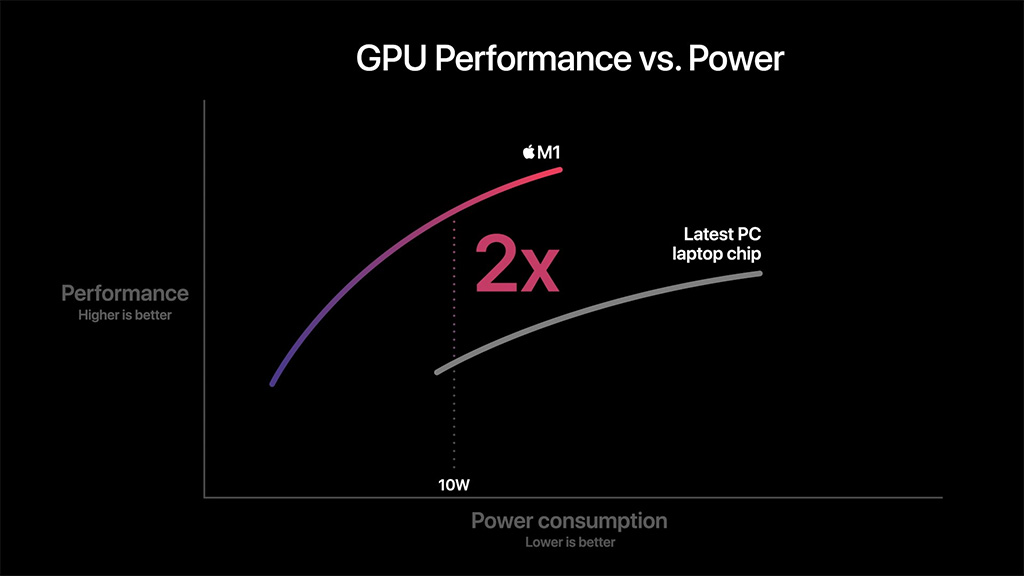
Järjestelmäpiirin grafiikkaohjain on 8-ytiminen ja sisältää 128 suoritusyksikköä. Se kykenee suorittamaan parhaimmillaan 24 576 säiettä samanaikaisesti ja tarjoaa jopa 2,6 TFLOPSin laskentatehon. Applen mukaan kyseessä on maailman nopein integroitu grafiikkaohjain, mikä pitää paikkansa ainakin teoreettisen laskentatehon osalta. Yhtiön omien testien mukaan M1 tarjoaa myös grafiikkasuorituskykyä kaksinkertaisesti ”viimeisimpään PC-kannettavan siruun” verrattuna 10 watin TDP-arvolla.
M1:een on integroitu myös 16-ytiminen Neural Engine tekoälytehtäville, kehittynyt ISP-kuvaprosessori, median pakkaus- ja purkuyksiköt sekä Thunderbolt / USB 4 -ohjain. Mukana on luonnollisesti myös Applen Secure Enclave -tietoturvaprosessori sekä tuki PCI Express 4.0 -standardille, mitä hyödynnettäneen ainakin NVMe-tallennustilan kanssa.
Lähde: Apple
Applen sivuilla ainakin mainittu useaan otteeseen HBM.
Siinä kannattaa muistaa sellainen asia, että kun päättää verrata omenoita appelsiineihin ja vesimeloneihin niin saa juurikin sellaista mehua kuin omenista tulee. Sitten kun pitäisikin siiderin sijaan tehdä kiljua niin ei se nyt vain olekkaan enää niin mukavaa jos on vain omenoita ja kaverilla appelsiineja ja vesimeloneita. On näitä nähty ennenkin, että itse valitaan vertailukohdat ja sopivati poimitaan testit ja kaskummaa lopputulos sattumalta sopii itselle. Vaan sitten kun aletaankin katsomaa todellisuutta ja oikean elämän testejä niin ei olekkaan enää yhtään niin kivaa.
Ainakaan täältä en löytänyt kuin maininnan "high‑bandwidth, low‑latency memory" joka nyt voi tarkoittaa mitä vaan?
Jännä, suomenkielisillä Apple-sivuilla puhutaan suoraan HBM-muistista.
Apple on ARM-prossuineen pärjännyt mobiilipuolella varsin erinomaisesti oikean elämän testeissä, joten aika kova luotto että pärjää myös tämän uuden M1:n kanssa. Ja kyllä eilisen esityksen perusteella tulee pärjäämäänkin. Mutta se nähdään ensi viikolla, kun ensimmäiset koneet saapuvat kuluttajille.
Joo, näköjään.
Englanninkielisellä sivulla lukee. "The do‑it‑all notebook gets do‑the‑unbelievable memory. The M1 chip brings up to 16GB of superfast unified memory. This single pool of high‑bandwidth, low‑latency memory allows apps to share data between the CPU, GPU, and Neural Engine efficiently — so everything you do is fast and fluid."
Ja suomenkielisellä: "Kaiken tekevä kannettava saa kaverikseen ihmeitä tekevän muistin. M1-siru mahdollistaa jopa 16 Gt:n supernopean yhteismuistin. Vähäisen viiveen HBM-muisti on integroitu yhteen komponenttiin, minkä ansiosta apit voivat jakaa dataa tehokkaasti prosessorin, näytönohjaimen ja Neural Enginen kesken, joten kaikki tekemäsi asiat hoituvat nopeasti ja sulavasti."
Vaikuttaa vähän käännösvirheeltä kyllä.
Niin mobiilipuolella. Vaan kun nyt puhutaan PC-puolesta. Silti väitteet on sitä luokkaa, että sieltä vain tullaan ja ollaan nopein, paras ja kaunein PC ikinä. Energiatehokkaita ne on, koska ne on mobiilipiirejä, mutta vähän rajaa toivoisi fanipoikailulle ja Anandtechin väitteille, että x86 aika mennyt jo jada jada.
Onhan se aika eri juttu vaihtaa koko linjasto ARM:eihin kuin se että Microsoft teki pienen kokeilun että ottaisko tuulta alleen. Tuskin MS:llä edes oli tarkoitus saada x86 -> ARM vaihdosta sen kummemmin tapahtumaan, kunhan huvikseen tekivät. Apple sen sijaan tulee nimenomaan pakottamaan nämä sisään.
Ja sinäänsä kyllä hyvä, että Applen kaltaisia pelureita on markkinoilla. Tietokoneissa vähän turhankin paljon mietitään legacy-tukea ja jonkun pitää olla se rohkea, joka pudottaa ne legacyt pois että päästään eteenpäin. Vaikka se lyhyellä tähtäimellä osaa käyttäjistä haittaakin.
Sitä en tiedä onko käännösvirhe vai ei, mutta kaikki merkit viittaavat kuitenkin HBM-muistiin myös tuossa englanninkielisessä tekstissä.
Luvut viestissäni eivät ole tarkkoja, mutta suuruusluokka on oikein. Qualcomm kertoi joskus Anandtechille, että kannettaviin tarkoitettuja siruja menee luokkaa tuhat kappaletta päivässä. Tämä tarkoittaa, että ARM-arkkitehtuuria käyttävien Windows-tietokoneiden markkinaosuus on jotakuinkin prosentin kymmenys.
Applella lienee suunnilleen kymmenen prosentin markkinaosuus tietokoneista. Tämä tarkoittaa, että ARM:ää käyttävien tietokoneiden myynnit tulevat seuraavan kahden vuoden aikana satakertaistumaan pelkästään Applen ansiosta. Selvästikin on oikein sanoa, että Apple on ensimmäinen jolla muskelit siirtymiseen riittivät.
Veikkaan että englanninkielisessä versiossa on alun perin lukenut HBM, mutta se on avattu, kun HBM ei ole terminä kovin monelle tuttu.
Sen verran korjaan, että ei tuo kyllä Microsoftilta ollut pieni yksittäinen kokeilu. Tarkoitusperiä voi tietty miettiä, mutta niissä voi olla kaikennäköistä toimittajien välisestä kilpailutuksesta ja ulkoisten riippuvuuksien vähentämisestä lähtien. Jos vaikka vilkaiset esim. tätä uutta: Microsoft Surface X Pro -tablet, musta, Win 10 1 791,90 niin voi vilaista cpu/gpu puolen nimiä ja miettiä")
Mutta joo, Applella on omassa ekosysteemissä täysi valta pakottaa ja käyttää mitä haluavat. Teoriassa MSFT voisi tietty poistaa Windowsista esim. x86 tuen, mutta hyöty olisi hyvinkin kyseenalainen, koska eivät toimita ekosysteemin kaikkia laitteita.
Applella on kyllä tuossa ihan muut intressit edellä, tietty teknologian on pakko olla kilpailukykyistä, koska muuten tuotteiden myynti tulee heikkenemään. Sen verran on kokemusta noista piirivalmistajien kanssakin toimimisesta, että pääasiallinen syy Applella on päästä eroon ulkopuolisista toimittajista, mitä on tehnyt myös mobiilipuolella. Esim. Nokia teki tuossa aikanaan yhden isoista virheistään, kun ulkoisti erään tärkeimmistä kilpailukyvyn antajistaan, kun taas Apple hankki piiriosaamista firmaansa, minkä tuloksia tässä sitten on nähty vuosien saatossa.
Mitkä merkit?
Joku oli tästä suomenkielisestä sivusta maininnut Anandtechin puolella ja siellä ainakin vastasivat:
"Just to be clear, that product page is wrong.
The M1 is running on 128-bit LPDDR4X."
Heillä kuitenkin on tästä ihan kunnolla tietotaitoa ja varmaan sisäpiirin tietoakin jonkun verran, niin taipuisin uskomaan tuota.
Voi toki näinkin olla, mutta hyvin tuo "This single pool of high‑bandwidth, low‑latency memory allows apps to share data between the CPU, GPU, and Neural Engine efficiently — so everything you do is fast and fluid" voisi viitata HBM-muistiinkin. Asiaan varmaan saadaan vahvistus lähipäivinä.
Katsotaan sitten kahden vuoden päästä, nythän ei voi vielä oikein sanoa imperfektissä, että riittivät") Mutta pakollahan tuo tietysti johonkin asti menee, jos ei nyt ole tuotteet niin kuraa (tuskin), että kukaan ei osta. Sitten voidaan seuraavaksi pohtia, mikä on sen siirtymisen mittari. Applen ekosysteemi siirtynee joltain osin, jos tuotteet eivät ole fiasko, mutta koko tietokonemarkkinan osalta jää kysymysmerkiksi. Esim. tuo 16GB muistiraja verottaa ostajia ammattipuolella, jos ei tuonne ole tulossa jotain lisää.
Mutta pakollahan tuo tietysti johonkin asti menee, jos ei nyt ole tuotteet niin kuraa (tuskin), että kukaan ei osta. Sitten voidaan seuraavaksi pohtia, mikä on sen siirtymisen mittari. Applen ekosysteemi siirtynee joltain osin, jos tuotteet eivät ole fiasko, mutta koko tietokonemarkkinan osalta jää kysymysmerkiksi. Esim. tuo 16GB muistiraja verottaa ostajia ammattipuolella, jos ei tuonne ole tulossa jotain lisää.
Niin, Snapdragon pultattu sinne omalla brändäyksellä?
List of Qualcomm Snapdragon processors – Wikipedia
en.wikipedia.org
"Technically, it’s a Snapdragon 8cx SoC with faster Adreno 685 GPU"
Toki tuossa voi olla muitakin tarkoitusperiä. Mutta sivuvaikutuksena ja/tai esteenä on tuo legacy-tuen putoaminen pois.
Eiköhän Applellakin olla tajuttu ettei pelkkä yksi piiri riitä kaikkeen. Noihin tehokkaamman pään vehkeisiin tulee sitten useampi M1:n tai sitten muuten vaan erilainen versio. Oikeastaan vähän yllättikin että nyt tuli kaikkii sama, olis voinut luulla että MBP:hen olis tullut vaikka kaksi M1:stä.
No se ei ole kauhean suuri salaisuus, etteikö Mikkisofta haluaisi Win32 (ja DOS) rippeistä eroon, mutta maailma pyörii legacy-softalla ja -raudalla. Windowshan on vielä modernia kamaa enterprise-puolella
Aiemmin on liikkunut huhuja 12-ytimisestä (8+4) Macbookista, eli se lienee varmaan sitten seuraava malli.
Jep, eli joku QC:n kanssa kustomoitu versio. Seuraava askel tuosta voisi olla sitten oma ARM pohjainen ratkaisu ja QC tippuu pois. Tosin en ole seurannut onko MSFT kuinka vahvistanut tuota omaa piiriosaamistaan eli onko siihen kuinka kapaa.
No siis kyllähän sinne emolle voi osaa komponenteista vaihtaa juottamalla (osa on saatavilla julkisesti, osa pitää poistetuista emoista juottaa irti) eikä turvapiiri käsittääkseni estä ihan kaikkea vielä kuitenkaan. Kieltämättä suurempaa osaa jatkuvasti kyllä ja jos esim. akut ja näyttöpaneelitkin ovat mahdottomia vaihdettavia jatkossa niin kyllähän se SER:iä aika pitkälle sitten on. Odotan mielenkiinnolla eteneekö tuo right-to-repair liike riittävästi jenkeissä ja EU:ssa että korjaamisen salliminen taataan jollain tasolla (toki Apple potkii vastaan hamaan ikuisuuteen asti varmasti ja vähintään haluaa pitää korjaamisen itsellään tähtitieteelliseen hintaan). Jenkeissähän jossakin osavaltiossa juuri puututtiin autojen kohdalla tuohon että auton valmistaja ei voi pitää autoon kertynyttä dataa itsellään (ja kryptaten haluaamansa osat) ja täten estää kolmansilta osapuolilta auton korjaamisen (joku oikeustapaus).
Olin odottanut tälläistä AMD:ltä parin vuoden sisällä. Jännä juttu, vaikuttaa että Apple on ihan oikeasti alkamassa prosessorivalmistajaksi ja heti tuo käyttöön aivan uuden tavan tehdä asioita.
Ilmeisesti tämä Applen Suomen sivuilta löytynyt tieto oli virheellinen ja kyse onkin LPDDR4X-muisteista.
Anandin testi on A14:sesta jossa on lpddr4x:ää 128bit väylän perässä.
AMD:llä taitaa olla melko vastaava ratkaisu GDDR6:llä toteutettuna uusissa konsoleissa.
Ei ne samassa paketoinnissa ole, samalla emolevyllä vain niin kuin ennenkin.
Interposerin tai jonkin vastaavan teknologian, Intel kiersi esimerkiksi EMIBillä interposerin tarpeen. 16 Gt HBM:ää ei kyllä prossun kanssa 10 wattiin mahdu, Vega Frontier Editionin 2x8Gt stackit vei yhteensä noin 20W
Niin on, mutta puhuivat nimenomaan tuosta M1 kun sanoivat että käyttää lpddr4x. Lisäksi voi katsoa esim. noita applen M1 kuvia joissa on normaalin näköisiä dram piirejä eikä HBM stäckkejä.
Näissä uusissa ei ihan kauheasti enää ole osia edes vaihdettavaksi. Vähän virransyötön komponentteja ja levylle juotettu massamuisti (jota tuskin saa ilman applen apua vaihdettua). Toisaalta en ihmettelisi jos apple siirtäisi enemmän rojua sen turvapiirinsä taakse ihan vaan kettuillakseen nyrkkipajakorjausfirmoille. Maltan tuskin odottaa Apple virransyöttöä ™.
Ai, no tämä selittääkin asian. Ensimmäinen oma prosessori ikinä ja siihen vielä HBM-muistit kylkeen oliskin ollu aikamoinen saavutus. Aiemmin en oikein tiennyt mitä ajatella Applen omista prosessoreista, mutta olisihan tuollainen kombo voinut olla jytky.
Nähtäväksi jää paljonko tälläinen CPU+RAM samassa paketissa toimii.
En nyt näe olisiko se mitenkään merkittävästi sen hankalampaa ollut, TSMC:llä on varsin kattava valikoima paketointiteknologioita interposereineen asiakkaiden käyttöön
For Next-Gen Mobiles – LPDDR4X | Samsung Semiconductor
http://www.samsung.com
No ei ihan ole ensimmäinen, onko tää nyt 10. versio Applen prosessorista. M1 on käytännössä A14x, joka taas on suhteellisen pieni päivitys A12x:stä, eli ei tämän piirin kohdalla mitään kovin suurta muutosta varsinasesti tule.
Ja moneltahan on mennyt ohi, ja ollut suorastaan denial moodi päällä sen suhteen kuinka hyviä prosessoreja Applella on ollut jo monta sukupolvea. Nyt kun uusin versio padin prossusta pistettiin halpamäkkeihin niin voidaan jo ylpeillä tehoikkaimmilla prosessorilla – varsinaiset nopeammat mäkkiprossut ovat vasta tulossa.
Skalaariprosessori pystyy ajamaan yhtä käskyä/iteraatiota yhtäaikaa. Superskalaariprosessori useampaa iteraatiota samaan aikaan ja tuo superskalaarisuuden määrä on yleensä nimetty prosessorissa leveydeksi. Eri osat prosessorissa ovat eri levyisiä, mutta tärkeimmistä käskyjen dekoodaus on Applen uusimmissa prosessoreissa 8kpl per kellojakso(Intel-AMD 4-5) ja yhtäaikaisia kokonaislukupuolen laskutoimituksia voidaan suorittaa 6kpl kellojakso(Intel AMD 4)
Arkkitehtuurista voidaan myös puhua toisessa suunnassa eli syvyydestä, eli kuinka suuri prosessorin käskyjen uudeellenjärjestelyn ikkuna on. Tässä Zen3 256, Intel Covet 352 ja Applen uusimmat ~630. Eli Applen prossu on liki tuplasti leveämpi ja syvempi arkkitehtuuriltaan kuin nykyiset x86-toteutukset – ja toteutus on myös tehokas eli käskyjä pystytään suorittamaan myös liki kaksi kertaa enemmän per kellojakso(IPC)
Transistorimäärä on todella huono mittayksikkö mihinkään, kun keskimääräinen logiikkatransistori vie n. 4 kertaa enemmän tilaa kuin keskimääräinen SRAM-(välimuisti)transtori ja monien nykypiirien pinta-alasta n. puolet (eli siis transistoreista n. 80%) on välimuistia.
Transistorimäärä lähinnä kertoo sen, paljonko on piirin (väli)muistien sekä rekisterifileiden kokonaiskapasiteetti muttei paljoa siitä, paljonko siellä on oikeasti logiikkaa.
Mutta onhan tässä kyse selvästi järeämmästä piiristä kuin Renoirissa.
riippuu vähän mitä PC termillä kukin haluaa ymmärtää mutta kannalla varustetuissa alustaratkaisuissa vaatisi oman kantansa ja AMD on karsinut kovalla kädellä niitä. Joku juotettava BGA ratkaisu olisi mahdollinen ainakin kannettavissa ja sulautetuissa laitteissa. Perinteisessä PC markkinassa nämä eivät ole ainakaan historiassa olleet menestyksekkäitä.
Kyllä siellä liukuhihnalla voi olla monta käskyä eri vaiheissa liukuhihnaa menossa. aloittamaan tai lopettamaan (vain) yhden käskyn suorituksen yhtä aikaa on se oikea määritelmä.
"Iteraatio" on myös aika outo sana tässä.
… tosin Zen3 pystyy lataamaan mikro-op-välimuistista kahdeksan mikro-operaatiota kellojaksossa ja renameamaan kuuden operaation rekisterit kellojaksossa.
Eli etupään leveysero on yleensä (vain) 1.33-kertainen zen3een nähden. Neljään pudotaan zen3lla vasta kun tulee huti mikrokoodivälimuistista.
Ja tilanteet joissa löytyy suorittettavaksi yli neljä kokonaislukulaskutoimitusta yhtä aikaa on harvinaisia.
Ja Zen3n kokonaissuoritusleveys on kuitenkin 14 käskyä kellojaksossa, Applella taas kokonaisleveys on 16 tai 17 käskyä kellojaksossa.
Jos jätetään liukuluku-/SIMD-puoli huomiotta, Zen3n kokonaisleveys on 8 käskyä kellojaksossa (4 kokonaislukulaskua, 3 muistioperaatiota, haarautuminen), Applella 12-13.
Ja liukuluku-/SIMD-puoli Zen3ssa onkin sitten järeämpi kuin A14ssa, varsinaisia laskentayksiköitä on yhtä monta, ja FMA-operaatiota voidaan laskea yhtä paljon/kellojakso, mutta Applella SIMDin leveys on puolet. AMDllä jää vähintään yksi SIMD_puolen liukuhihna vielä vapaaksi muille operaatiolle (esim. yhteenlaskuille tai jollekin SIMD-kokonaislukuoperaatioille) jos porskutetaan FMAta täydellä teholla, mutta lisäksi AMDllä on tämän lisäksi pari yksikköä joilla voi tehdä tallennuksia tai muunnoksia. Ja kaistaa on myös AMDllä SIMD-operaatioilla 1.5x enemmän, kun yksi lataus tai tallennus siirtää tuplamäärän dataa.
Zen3een verrattuna todellinen leveys on siis n. 1.33-1.5-kertainen, ei "liki tuplasti leveämpi". "liki tuplasti leveämpi" pätee lähinnä verrattuna Zen1een ja Skylake-johdannaisiin.
Ja toisaalta syvyttä voisi mitata myös liukuhihnan pituudella, joka Zen-johdannaisissa ja Intelin Core-sarjan prossuissa on Applen ytimiä pidempi, ja AMDn ja Intelin prossut tämän takia kykenevät suurempiin kellotaajuuksiin. Applen ytimet kellottuu maksimissaan 3 GHz:aan, AMD on lähellä viittä ja Intel yli viidessä. Vaikka Applella on käytössään näistä kehittynein valmistustekniikkaa.
Applen maksimikello on 3GHz iphonen sisällä n. 3W TDP:llä.
Kukaan ei vielä tiedä, että kuinka ylös tuo kellottuu kun TDP-raja nostetaan 30W:hen ja päälle lyödään jäähdytin. (Toki siltikään ei varmasti nousta 5GHz tasolle).
Mistäs näin päättelet? Liukuhihnan eksaktia pituutta Apple ei ole kertonut, mutta käskyjen mispredict-penaltyn perusteeella Applen prossuissa on vähintään yhtä pitkä liukuhihnoitus kuin Intelin ja AMD:n prosessoreissa.
Eihän sillä suoraan olekaan. Transistoriketjujen pituus määrää maksimikellotaajuuden ja yhdessä liukuhihnan vaiheessa syntyvä ketjun pituus riippuu myös prosessorin liukuhihnoituksesta – eli liukuhihnan vaiheessa tehtävä asia jos jaetaan kahdelle liukuhihnan vaiheelle saadaan ko. ketjua hyvin todennäköisesti lyhennettyä.
Mutta siis pointtisi on oikea, ei se liukuhihnan pituus korreloi millään tavalla maksimikellotaajuuteen erilaisilla prosessoreilla kuten aikaisemmin päätellään.
L1-kakun viive, 3 kellojaksoa, on julkista tietoa. Ja tuolla kakulla on enemmän merkitystä IPChen kuin sillä onko jotain kokonaislukuyksiköitä 4 vai 6 kpl. Tuo 3 kellojakson viive tuolle 128 kiB kakulle ei olisi (millään nykyisillä valmistustekniikoilla) mahdollinen saman luokan liukuhinapituudella kuin Zen3 ja SKylake (se koko liukuhihna on kyllä balanssissa että ei siellä muualla turhaan vaiheita splitattu liian pieniksi kun kakku kuitenkin rajoittaa kelloja).
Myös joissain muissa käskyissä Applella on selvästi pienempiä viiveitä kuin AMDllä ja Intelillä.
Missä perustat väitteesi shaarautumishudin pituudesta?
Apple on tosiaan jyrännyt mobiilipuolella jo vuosia, joten siinä mielessä yhtiön lupaukset M1:n suorituskyvystä eivät ole yllättäviä. Kannattaa kuitenkin huomioida, että suorituskyky saattaa heikentyä aikalailla, jos ei päästä ajamaan natiivia ARM-softaa.
Windowsin puolella Qualcommin järjestelmäpiireihin perustuvat ratkaisut laittavat hyvin kampoihin Intel-laitteille omassa tuotesegmentissään mutta x86-softaa ajettaessa suorituskyky matelee. Esimerkiksi SQ1 asettuu Geekbench 4 -testissä i5-6300U:n ja i5-7200U:n välimaastoon yhden ytimen osalta, kun käytössä on testin ARM-versio. x86-versiolla suorituskyky on Pentium Gold 4425Y:n tasolla. Nähtäväksi jää, miten kehittäjät kääntävät sovellukset ARM:lle ja kuinka hyvin Rosetta2 hoitaa homman macOS:lla.
GeekBench 4 on Windows
Alla vielä vertailuksi Android- ja iOS-laitteilla ajettuja tuloksia. OnePlus 5 puhelimessa on sama prosessori kuin HP Envyssä. Näyttäisi, että Androidilla ajettu tulos vastaa Windowsilla ARM-sovelluksen tulosta.
GeekBench 4 on Android
GeekBench 4 on iOS
Miten liukuhihnan pituus rajoittaa L1-cachen viivettä? Ja sama 8-way L1 cache Applellakin kuin AMD:llä ja Intelillä Skylakessa, cachen tarkistuksessa samat 8 osoitetta tarkistettavana.
Ei ole tullut hetkeen räpättyä assemblyn ja manuaalisen liukuhihnaoptimoinnin kanssa, mutta jos vanhasta muistista yrittää, joku muu voi korjata") Pidempi/syvempi liukuhihna antaa enemmän aikaa käskyn suorittamiseen eli koska korkeammilla kelloilla yksittäisen kellojakson pituus on lyhyempi, niin tekemällä pidemmän liukuhihnan annetaan enemmän aikaa käskyn suorittamiselle. Yksittäisen käskyn suorittaminen siis voi kestää matalammalla ja korkeammalla kellotaajudella saman ajan, jos liukuhihnan pituudet ovat samassa suhteessa. Toisaalta kokonaisuutena korkeampi kellotaajuus ja pidempi liukuhihna mahdollistaa suorittamaan enemmän käskyjä loppuun samassa ajassa.
Pidempi/syvempi liukuhihna antaa enemmän aikaa käskyn suorittamiseen eli koska korkeammilla kelloilla yksittäisen kellojakson pituus on lyhyempi, niin tekemällä pidemmän liukuhihnan annetaan enemmän aikaa käskyn suorittamiselle. Yksittäisen käskyn suorittaminen siis voi kestää matalammalla ja korkeammalla kellotaajudella saman ajan, jos liukuhihnan pituudet ovat samassa suhteessa. Toisaalta kokonaisuutena korkeampi kellotaajuus ja pidempi liukuhihna mahdollistaa suorittamaan enemmän käskyjä loppuun samassa ajassa.
Luulin, että olet joskus suorittanut TTYn/TTKKn"tietokonetekniikka"-kurssin. Siellä kyllä on asia selitetty.
Käskyn suorittamiseen pitää tehdä monta asiaa, yksinkertaisimmillaan esim.
1) hakea käsky (käskyväli)muistista (aikaa kuluu esim. 0.35 ns)
2) dekoodata, että mistä käskystä on kyse, mitä sen pitäisi tehdä, muodostaa tämän perusteella prosessorin sisäiset kontrollisignallit (aikaa kuluu esim. 0.2 ns)
3) lukea käskyn tarvitsema data rekstsereistä (aikaa kuluu esim. 0.2 ns)
4) suorittaa varsinainen laskuoperaatio (aikaa kuluu esim. 0.3ns)
5) kirjoittaa tulos kohderekisteriin (aikaa kuluu esim. 0.15ns)
Mikäli mitään liukuhihnaa ei ole, ja käsky suoritetaan kellojaksossa, sen suorittamiseen menee aikaa kaikkein näiden summa eli tässä esimerkissä 1.2ns. Saavutetaan maksimissaan 833 MHz kellotaajuus.
Jos meillä onkin vaikka 2-vaiheinen liukuhinna, ekassa vaiheessa (ekalla kallojaksolla) haetaan käsky sekä dekoodataan se, toisessa vaiheessa (seuravalla kellojaksolla) luetaan data rekistereistä, suoritetaan laskuoperaatio ja kirjoitetaan tulos, nyt kellojaksossa pitää tehdä vain sen verran, mihin pidempi näistä vie aikaa, eli max(0.35 + 0.2 , 0.2 + 0.3 + 0.15) = max(0.55, 0.65) = 0.65ns, eli kellojakso saa kestää maksimissaan 0.65ns. Eli saavutetaankin 1/0.65 = 1.54 GHz kellotaajuus.
Jos meillä on vaikka 3-vaiheinen liukuhihna, ekassa vaiheessa haku, toisessa dekoodaus ja rekisterinluku, ja kolmannessa suoritus ja tuloksentallennus, pisin vaihe on 0.45ns eli saavutetaan 1/0.45ns = 2.2 GHz kellotaajuus.
Neljällä vaiheella yhdistämällä dekoodaus ja rekisterin luku pisin vaihe on dekoodaus+rekisterinluku eli 0.4 ns, eli saavutetaan 2.5 GHz kellotaajuus.
Viidellä vaiheella pisin vaihe on käskynhaku eli 0.35ns, eli saavutetaan 2.86 GHz kellotaajuus.
Splittaamalla käskyhaku kahteen osaan, kuusivaiheisella liukuhihnalla pisin vaihe olisi suoritus eli 0.3ns, saavutettaisiin 3.33 GHz kellotaajuus.
Käytännössä tosin liukuhinavaiheiden väliin tulee aina liukuhihnarekisteri (viive joitain kymmeniä pikosekunteja) joten kellotaajuus ei todellisuudessa skaaladu ihan näin hyvin, ja lisäksi joitain asioita ei vaan pysty splittaamaan useaan liukuhihnavaiheeseen järkevästi johtuen siitä, mitä se tekee.
Toki sitten prosessorin rakenteen monimutkaistuessa väliin tulee sellaisia liukuhihnavaiheita jotka tekevät asioita, joita yksinkertaisen prosessorin ei tarvitse ollenkaan tehdä. Esim. perinteisillä 1980-luvun RISC-prossuilla on tuossa laskuoperaatio(EXEC)- ja tuloksentallennusvaiheen(WB) välissä muistiaccess-vaihe (MEM) (ja niissä myös dekoodaus ja rekisterinluku oli yhdistetty samaksi vaiheeksi).
Rekistereitä uudelleennimeävät ja käskyjä uudelleenjärjestelevät prosessorit taas tarvitsevat vaiheet sille rekisterien uudelleenimeämiselle, käskyjen laittamiselle puskuriin odottamaan suoritusta sekä niiden skeudulointiin suoritukseen, sekä vielä tuloksen eläköitymiseen (retire) jolloin käsky virallisesti julistetaan suoritetuksi ja käskyvuo tuodaan takaisin alkuperäiseen järjestykseen. Eli käytännössä monimutkainen ja kehittynyt ydin tarvitsee muutaman vaiheen enemmän päästäkseen samaan kellotaajuuteen.