
Apple kertoi aiemmin tänä vuonna tulevansa julkaisemaan ensimmäisen yhtiön omaan järjestelmäpiiriin perustuvan Mac-tietokoneen vielä tämän vuoden aikana. Tänään pidetyssä julkaisutilaisuudessa yhtiö julkaisi paitsi uudet Macit, myös niiden järjestelmäpiirin, M1:n.


Apple M1 -järjestelmäpiiri rakentuu yhteensä 16 miljardista transistorista ja se valmistetaan 5 nanometrin prosessilla. Se hyödyntää poikkeuksellista ratkaisua, jossa muistipiirit on istutettu samaan Applen suunnittelemaan paketointiin itse järjestelmäpiirin kanssa. Yhtiö ei tarkentanut, paljonko tai mitä muistia järjestelmäpiirin tukena on, mutta kehuu ratkaisun tarjoavan sekä reilusti muistikaistaa että matalat viiveet. Yhtiö valmistaa järjestelmäpiiristä ilmeisesti kahta eri versiota, joista toisessa on 8 ja toisessa 16 Gt HBM-muistia. Päivitys: Applen Suomen sivuilta löytynyt maininta HBM-muisteista on ilmeisesti virheellinen ja kyseessä on todellisuudessa LPDDR4X-muistit.

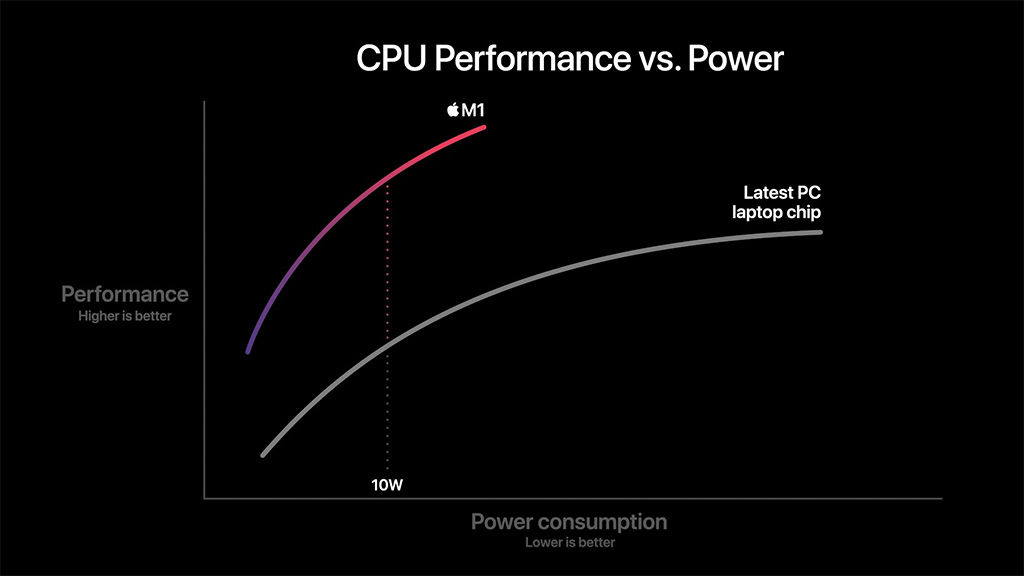
Järjestelmäpiirissä on neljä tehokasta prosessoriydintä erittäin leveällä arkkitehtuurilla ja yhteisellä 12 megatavun L2 -välimuistilla sekä neljä energiatehokasta kapeammalla, mutta edelleen leveällä arkkitehtuurilla ja 4 Mt:n jaetulla L2-välimuistilla. Applen mukaan sen tehoydin on maailman tehokkain prosessoriydin ja M1 tarjoaa parasta prosessorisuorituskykyä per watti. Yhtiön mukaan sen suorituskyky MacBook Airin 10 watin TDP:llä on kaksinkertainen ”viimeisimpään PC-kannettavien siruun” verrattuna.

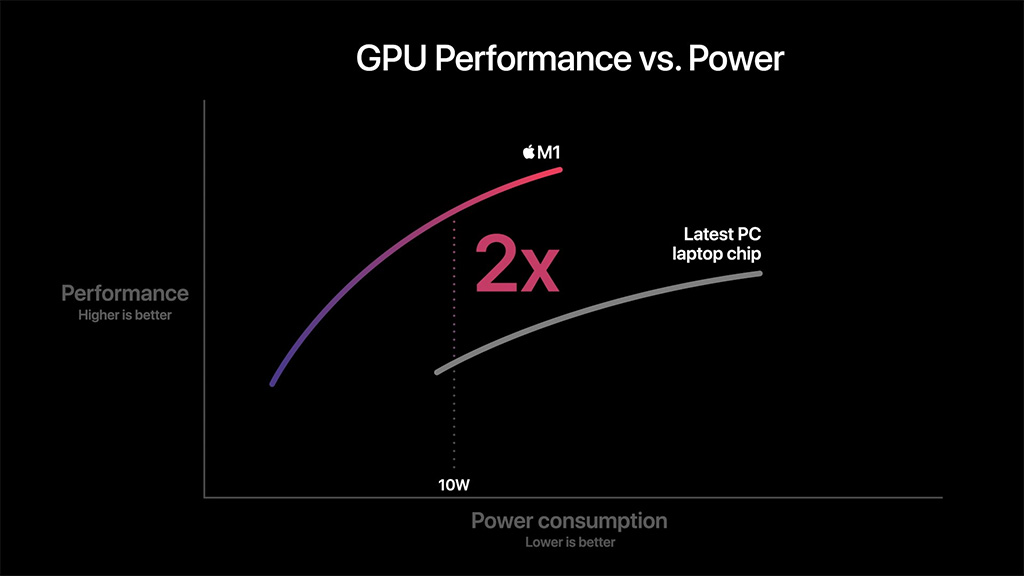
Järjestelmäpiirin grafiikkaohjain on 8-ytiminen ja sisältää 128 suoritusyksikköä. Se kykenee suorittamaan parhaimmillaan 24 576 säiettä samanaikaisesti ja tarjoaa jopa 2,6 TFLOPSin laskentatehon. Applen mukaan kyseessä on maailman nopein integroitu grafiikkaohjain, mikä pitää paikkansa ainakin teoreettisen laskentatehon osalta. Yhtiön omien testien mukaan M1 tarjoaa myös grafiikkasuorituskykyä kaksinkertaisesti ”viimeisimpään PC-kannettavan siruun” verrattuna 10 watin TDP-arvolla.
M1:een on integroitu myös 16-ytiminen Neural Engine tekoälytehtäville, kehittynyt ISP-kuvaprosessori, median pakkaus- ja purkuyksiköt sekä Thunderbolt / USB 4 -ohjain. Mukana on luonnollisesti myös Applen Secure Enclave -tietoturvaprosessori sekä tuki PCI Express 4.0 -standardille, mitä hyödynnettäneen ainakin NVMe-tallennustilan kanssa.
Lähde: Apple
Koko L1-luku voi olla peräisin spekulatiiviselta käskyltä joka pitää nukettaa – mitään bränch predictoria ei ole kehitetty tarjoamaan lähellekään sitä osumatarkkuutta jonka järkevän, ei kokonaisen osoiteavaruuden tarjoaminen L1-datalle mahdollistaa. Miksi muistihaun osumatarkkuus pitäisi olla jotain muuta kuin muun koodinsuorituksen?
.
Kun L1-datasta luetaan osittaisilla osoitteilla vain sitä dataa jonka ko-threadi on jo itse sinne hakenut ei kovin kummoista lisäinformaatiota saada sivukanavahyökkäyksillä kaivettua.
Intelin prossuissa oli idiottimaisia ratkaisuja ja suoranaisia bugeja pilvin pimein. L1-datan pitäminen threadikohtaisena ja sen lukeminen osittaisella lineaarisella osoitteella ei ole yhtään sen vaarallisempaa kuin tuon store-forwardinkaan tapauksessa.
Kova olet aina pätemään joo, mutta tosiaan mietihän vielä vaikka kerran paljonko cacheista tarvii dataa lukea ja vertailla suhteessa varsinaiseen luettuun dataan L1-haun yhteydessä jos tagit on täydellä fyysisellä tagilla. Ja jos vielä käytät hetken aikaa niin ehkä keksit keinoja kuinka tuota overheadia voidaan pienentää.
No mitkä olisivat ne ongelmat? Joka cachelinjalla on kuitenkin fyysiset tagit ja ne tarkistetaan dataa siirrettäessä L1:een joten mitään ongelmia pelkän virtualisen tagin käytöstä ei tule. Ja se datan luenta tehdään predictionina eli se ei ole 100% varma tulos luettaessa ja käytettäessä, vain 99.999% tai sinnepäin. Loputkin osoitteesta tarkistetaan mutta sitä ei tarvitse tehdä turhaa energiaa polttaen ennen datan saamista käyttöön.
Nykyprossuissa taitaa olla useamman kellojakson pituinen fetch-stage käskypuskurin ajovaiheessa. Ja rekisterifile – lukukäsky liukuhihnan vaiheessa x ja data tulee x+y kellojaksolle.
Mutta prosessorin voi kyllä backportata vanhemmalle prosessille ilman ongelmia vaikka siinä cachen lisäksi kaikki muukin siirtyy kauemmaksi…… eikö nämä ongelmat kuitenkin liity aika pitkälti toisiinsa?
Niin muistuuko mieleen Heikki jonka suunnittelemissa prosessoreissa lienee hyvin suuria koherenssiongelmia muistinkäsittelyn suhteen
Kyllä, niin VOI. Mutta n. 99% tapauksista se ei ole sitä. Se, että prosentissa tapauksissa ongelmaa ei ole , ei poista ongelmaa niiltä 99%lta.
Nyt menee kyllä taas logiikka han käänteiseksi.
Se, että TAGit täysin turhaan jätettäisiin pois ei mahdollista[/B yhtään mitään.
Se ainoastaan hidastaisi ja monimutkaistaisi L1-hutia aivan turhaan
kaikenosumatarkuuden pitää olla niin hyviä kuin helposti mahdollisia ja kaikkien viiveiden pitää olla niin lyhyitä kuin helposti mahdollisia ilman että muualla joudutaan mistään pahasti tinkimään.
Ei vaan ole mitään järkevää keinoa tehdä haarautumishudista nopeampaa.
Sen sijaan L1D-hudin tarkastaminen on mahdollista hyvin aikaisin jollain L1D-hudin viive on peni, sen tekeminen tuthaan myöhään olisi täysin turhaa sen hidastamista.
Jälleen hieno esimerkki siitä kuinka amatööri on totaalisen pihalla kuin ei tiedä perusasioita.
Käyttöjärjestelmässä jonka designissa on yhtään kiinnotetty huomiota suorituskykyyn(eikä menty mikrokernel-uskonnon perässä), samat säikeet pyörivät sekä käyttäjän prosesseissa että kernelinkoodissa, softa tekee kutsun kernelin rutiiniin ja sama säie vaihtaa kernelin puolelle ja sitten palaa sieltä.
Eli se säie on kernelin puolella voinut juuri käsitellä vaikka mitä sellaista dataa johon käyttäjän prosessilla ei ole lukuoikeuksia. Sitten vaan accessoidaan sallittua osoitetta jolla on sama hash-arvo kuin välimuistissa olevalla kernelin privaattidatalla.
Vähemmän ja vaikeammin hyödynnettäviä kuin sinun kuvittelemissasi ratkaisuissa.
Vaikka Zenillä tehdään store-load-forwarding verraten latauksesta ja tallennuksesta vain alimpia 12 bittiä, sille latauksen osoitteelle kyllä tehdään ihan täydellinen osoitteenmuunnos ja jos yritään ladata laittomasta osoitteesta, lentää HETI page faultti ennenkuin data pääsee milekään seuraavalle käskylle.
Se "vain" 12 bittiä on siellä sitä varten että
1) ei tarvi verrata kaikkia n. 44*48 bittiä
2) se vertailu voidaan alottaa aiemmin kun se voidaan tehdä rinnakkain sen TLB-haun kanssa sen sijaan että se tehtäisiin sen jälkeen.
Mutta hieno esimerkki kehäpäätelmästä, käytät omaa harhakuvitelmaasi perusteluna sen harhakuvitelmasi järkevyydelle että "muualla täytyy olla sama ongelma" vaikkei tosiasiassa ole.
Että ei, Zenin 12-bittisissä STLF-vertailujoissa ei ole mitään merkittävää helposti hyödynnettävää sivukanava tietoturva-aukkoa mutta sinun "ideassasi" on L1D-kakun kokoinen massiivinen ja helposti hyödynnettävä sivukanava-aukko
Minä olen se, joka oikeasti tiedän nämä asiat, sinä ole itse, joka yrität päteä vaikket oikeasti ole yhtään pätevä siihen pätemiseen.
Osaat ulkoa paljon pikkuyksityiskohtia, muttet ymmärrä kokonaiskuvaa ja toimintaperiaatteita siitä, miten asiat oikeasti toimii, ja sitten tuilkitset niiden ulkoa muistamiesi yksityiskohtien merkityksiä aivan väärin.
Mitään muuta keinoa siihen osuman varmistamiseen 100% varmuudella ei ole kuin sen täyden tagin lukeminen. Se, että 99% muistiaccesseista menee oiekaan paikkaan mutta 1% meneekin väärän paikkaan ei paljoa lohduta.
Kaikkien musitiaccessien nyt vaan täytyy mennä oikeisiin osoitteisiin, tälle ei vaan voi mitään. Ja joskus se tarkastus kuitenkin pitää tehdä. Ja sen myöhästämiseen ei vaan ole mitään järkevää syytä, siinä ei säästetä yhtään mitään.
Jos fyysinen muistiavaruus on luokkaa 44 bittiä ja wayn koko on 12 bittiä niin TAGia tarvii lukea 32 bittiä. Tämä nyt vaan täytyy lukea eikä siitä pääse millään yli eikä ympäri. Se on sitä overheadia joka tulee siitä, että ylipäätään käytetään välimuistia.
Selitetty yllä. Access sopivaan toiseen osoitteeseen (jota ei ole L1d-kakussa) sisältää saman hashin kuin eri osoite (jonka data löytyy L1D-kakust).
Tagit tarkastetaan silloin kun tehdään muistihakua, sen takia, että niisä selviää, että onko halutun osoitteen dataa välimuistissa
Väännetään nyt vielä rautalangasta, oletetaan vaikka että hashi muodostetaan käytettämällä siihen vain osoitteen bittejä 31:12, tässä esimerkissä ei ole edes väliä sillä, käytetäänkö fyysisiä vai virtuaalisia osoitteita.
1) Suoritetaan lataus osoitteesta
0x0000 0000 0000 1000 (luku paloiteltu 16-bittisiin osiin luettavuuden parantamiseksi)
Tämän osoitteen sisältämä data ladataan välimuistiin.
Tällöin muodostetaan hash biteistä 00001. Saadaan sille joku arvo, kutsutaan tätä vain nimellä X.
2) Suositetaan lataus osoittesta
0x0000 0001 0000 1000
Tällä osoitteella on tismalleen samat bitit 31:12, eli se saa tismalleen saman hashin (x)
Zenin way prediction mikrotagin perusteella ennustaa osumaa siihen wayhin missä tuo aiemmin ladattu eri osoitteen data on.
Jos välimuistin osumantarkastus tehtäisiin pelkän microtagin perusteella, tämä jälkimmäionen lataus saisi tuon datan , eli lataus lataisi väärän arvon
99.999% on täysin väärää kertaluokkaa oleva heitto. Todellinen on luokkaa 99%.
Ja sen tarkastuksen viivästäminen ei säästäisi käytännössä yhtään mitään. Ihan saman määrä bittejä sieltä TAGeista pitää lukea vaikka sen luvun tekisi myöhemin.
Päin vastoin, se, että aletaan raahaaman niitä liukuhihnalla perässä seuraaville vaiheille ja träckäämään myöhempiä käskyjä joiden arvo riippuu siitä datasta että mitkä kaikki pitäisi perua ja uudelleenkäynnistää. se sitä energiaa haaskaisi ziljoona kertaa enemmmän.
Hienoa korkean tason käsienheiluttelua, kun ei oikeasti ymmärretä niitä yksityiskohtia asioista, mistä pädetään.
Ei mikään voi kestää montaa kellojaksoa ellei siellä ole välissä rekistereitä.
Mihin väliin kuvittelet ne rekisterit näissä tunkevasi?
Sotket nyt keskenään aivan eri tavalla skaalautuvia asioita, sekä sitä, mikä on ongelma ja mikä on muuttuja joka vaikuttaa suorituskykyyn.
Eipä tule mieleen ketään sellaista.
Yksikään suunnittelemani prosessoriydin ei ole edes yrittänyt olla välimuistikoherentti. Koska niissä käyttötarkoituksissamihin ne on suunniteltu se olisi ollut täysin turhaa, ja vaan monimutkaistani designia ja lisäisi virrankulutusta.
Ja oikein hienoa yrittää päteä sillä, että kun itseltäsi on aivan alkeetkin hukassa niin sitten olet kerran onnistunut muistamaan jonkun välimuistikoherenttiusprotokollan pikkuyksityiskohdan minua paremmin niin pidät tätä suurena saavutuksena ja minun dissaamiseni aiheisena.
Olettaisin, että M on kirjaimensa mukaisesti Maceille tarkoitettu prosessori. iPadit jatkossakin A-sarjan prossuilla.
Sinänsä keskusteluun syvyyden tasosta propsit
Minun on ainakin vaikea keksiä, että miksi iPad pro:lle tehtäisiin erikseen erillinen prosessori.
A12x/z oli 4x perf-core + 4x efficient core ratkaisu, eli aivan kuten M1. Siinä oli myös sama 128bit-muistiväylä, kasa neural engineä ja mitälie. Nyt M1:seen tuli lähinnä Thunderbolt / USB4-tukea, mutta tuskin se haittaa kun iPad Pro:lle halutaan kuitenkin näyttöulostulot ja vaikka mitä dock-tukeakin taitaa jo olla.
Voi olla, että M1 re-brändätään A14X:seksi, mutta eiköhän se sama ydin tule olemaan.
Ikään kuin google olisi yhtään sen parempi jos puhelimista on kyse. Näiden uusien läppäreiden kohdalla on vielä selvittämättä että millaista diagnostiikkaa käyttäjät pakotetaan jakamaan.
Jos ihan rehellisiä ollaan, ainut tapa saada yksityisyyttä on pysyä poissa internetistä jota ei alunperinkään ole suunniteltu olemaan yksityinen paikka oikeastaan yhtään millekään asialle.")
Kelpo karikatyyrin väkersit. Vastaväitteenä voisikin esittää, että jos kerran kaikki data on jo julkista vapaata riistaa, niin mihin näitä uusia tehokeinoja enää tarvittaisiin? Rahanhaaskausta vain rahanhaaskauksen vuoksi?
Kukaan ei ole väittänyt että ne ovat vapaata riistaa. Pointtini oli että mikäli internetissä ollaan, on melko todennäköistä että pysyminen anonyymisenä on lähes mahdotonta. Olkoot kyseessä Applen, Googlen, Microsoftin, tai kenen tahansa muun vakoilu ja "vakoilu", käytännössä koko internetin käytöstä (mukaan lukien älypuhelimet) tulee miltei mahdotonta.
Jääkööt offtopic osaltani kuitenkin tähän. Voidaan jatkaa ajatusten vaihtoa jossain toisessa ketjussa.
Sun päättelyketjut on hyvin outoja, 5% latauksista jokatapauksessa nuketetaan, jos osoitetarkkuuden tiputtamisella 1/3:aan näiden poistettavien käskyjen määrä lisääntyy 0.01% näistä tulee ongelma? Avaapas vähän päättelyketjuasi.
Osumatarkkuus haetaan sellaiseksi että osoitetarkkuuden laskeminen ko. tagin tarkuuden takia ei vaikuta nopeuteen millään tavalla merkittävästi. Normaalin L1-hudin tapauksessa TLB-muunnos pitää sitten aloittaa ainakin kellojaksoa myöhemmin, mutta sekään ei välttämättä ole hitaampaa koska vähäisempien TLB-munnosten takia energibudjettia ko. hommaan on monikymmenkertaisesti vielä edes huomioimatta että TLB voitaneen samalla muuttaa kääntämään vain yhden osoitteen per kellojakso sen sijaan että se joutuisi kääntämään L1-porttien mukaisen määrän dataa per kellojakso.
Tähänhän perustuu fyysisten tagien käyttö L1-luvussakin, se löytää ne synonyymitkin. AMD on selkeästi dokumentoinut että L1-synonyymit tunnistaa L2 ei L1 joten L1-hakuun ei tule parempaa osumatarkkuutta vaikka osuman fyysiset tagit tarkistettaisiinkin joskus – aivan turhan työn tekeminen prosessorin krittisellä linjalla on aivan älytöntä.
Sulta menee se pointti täysin ohi, L1-cache on 32kilotavua, siihen lähestulkoon täydellisen osumatarkkuuden saaminen ei vaadi 64 bittistä osoiteavaruutta. Jo silloin aikanaan laskeskelin järkevää osoiteavaruutta L1-osoitukseen ja päädyin aavistuksen suurempaan L1-tagin pituuteen kuin AMD käyttää, mutta AMD käyttää yksinkertaista hashia eli tagit bitit xorrataan vastaavan määrän ylempien bittien kanssa jotta aliasoivat osoitteet eivät ole minkään vakiokaavan mukaisia ja käytännössä L1-cachen osoiteavaruus menee suoraan sinne järkevän alueen yläpäähän.
No et ole tosissasi Meillä on siellä datassa se bitti joka kertoo ko. datan lukuoikeuden prosessorin käyttölevelille, se että Intelin prosessori siitä huolimatta lukee tämän datan ei ole tämän tekniikan heikkous. Katsohan nyt peiliin ennenkuin yrität päteä.
Meillä on siellä datassa se bitti joka kertoo ko. datan lukuoikeuden prosessorin käyttölevelille, se että Intelin prosessori siitä huolimatta lukee tämän datan ei ole tämän tekniikan heikkous. Katsohan nyt peiliin ennenkuin yrität päteä.
Vähemmän ja vaikeammin hyödynnettäviä kuin sinun kuvittelemissasi ratkaisuissa. Mutta paljon helpompi huudella sivusta ja haukkua niitä jotka tekee kuin yrittää tehdä itse.
Et taas ole tosissasi. Kaikki mikä voidaan tehdä hitaasti säästää energiaa verrrattuna nopeaan suoritukseen, tämä oli Intelin insinöörien pääpointti Core-prossujen esittlyssä, prosessorissa on keskitytty tekemään kaikki niin hitaasti kuin mahdollista sen vaikuttamatta suorituskykyyn.
Olen selittänyt tätä enennin, overheadi on PALJON suurempi. Jos L1-TLB on 8-way ensin luetaan ja vertaillaan niitä 8:aa lineaarisen osoitteen dataa, sen jälkeen luetaan se 32 bittinen fyysinen data ja vertaillaan sitä L1-cachen tagiin. Ja tasan tiedetään että L1-cachen accessiin ei tarvita fyysistä käännöstä, se voidaan hoitaa virtuaalisellakin osoitteella mutta fyysiset tagit tarvitaan joka linjaan koherenssiprotokollalle, ja samalla fyysisillä tageilla hoituu synonyymi ja homonyymiongelmat. Linjan tuplataggausta ei haluta käyttää kun se lisää kriittisen polun overheadia cachessa, mutta erikoistapaus jossa L1 on subset L2:sta ongelma hoituu aivan itsestään, jokainen cachelinjat on tagattu L2:ssa joka hoitaa koherenssit ja synonyymit eikä homonyymejä voi syntyä.
Selitetty yllä. Access sopivaan toiseen osoitteeseen (jota ei ole L1d-kakussa) sisältää saman hashin kuin eri osoite (jonka data löytyy L1D-kakusta). Alempana vielä esimerkki
Tämä on aivan oikein, ladataan jo cachessa oleva data sen sijaan että haettaisiin oikea data muistista. Virhe huomataan jossain vaiheessa myöhemmin aivan kuten väärin menneen haarautumisennustuksen kanssakin ja korjataan, ei mitään ongelmaa kunhan ko. tapauksia ei tule niin paljon että se alkaisi hidastaa suorituskykyä.
Koko sivukanavahyökkäysten aalto tulee siitä että tarkastuksia ei tehdä ajoissa vaan viivestetysti. Kaikki mikä voidaan kannattaa tehdä hitaasti eikä nopeasti, tämä on ihan perusasioita piirin optimoinnissa ja on mm. Intelin esitelmässä kun he julkaisivat core-arkkitehtuurin.
Jankaat vain jankaamisen ilosta jonkun aivan turhan pointin perässä. Esimerkissä oli kyse että kun tehdään haku rekisterifileen tulos tulee myöhemmin eli esimerkiksi haku rekisterifileestä voi olla jaettu useampaan vaiheeseen, siellä on kuitenkin ~400 osoitetta valittavana. Datan tulo rekisterifileestä voi tulla suoraan tai sitten siinä tosiaan voi olla välirekisteri datan siirtoon jos siirrettävä matka on niin pitkä että se ei ehdi tai energiatehokkuuden takia sitä ei haluta siirtää yhdessä kellojaksossa.
Datakoherenssi on aika yksinkertainen asia, datasta ei ole kuin yksi versio missään. Mesi-protokolla on erittäin yksinkertainen ja esittää kuinka ko. saadaan toteutettua useampien cachejen kanssa. Näistä perusasioista voi sitten johtaa muuta perusasiaa kuten sen että saman datan käsittely useammassa eri prosessoriytimissä yhtäaikaa on helvetin hidasta. Ja tämähän ei ole kuin raudan näkökulma, saman datan käsittely yhtä aikaa useammalla eri ytimellä on ohjelmoinnin kannalta katastrofi jonka takia samaa dataa ei käsitellä yhtäaikaa vaan yhteinen data lukitaan tavalla tai toisella sitä käyttävälle ytimelle. Näistäkin sun on pitänyt vääntää ja vaikka ja mitä vastaan vaikka perusasia on hukassa.
[quote
Ja ne lähteet niihin väittämiisi Applen liukuhihnanpituuksiin/haarautumishutiviiveisiin uupuu yhä.
[/QUOTE]
Applen vanhemmat prosessorit on julkisesti dokumentoitu, googlaa. Niissä liukuhihnan pituus on aivan sama kuin Intelin/AMD:n prossuissa ja L1-latenssi sama 3, uusimpien prossuversioiden tiedot on vain spekulaatioita mutta ainakaan minun silmiin ei ole näkynyt kenenkään spekuloivan liukuhihnan lyhennyksistä prosessorin monimutkaisuuden lisääntyessä valtavasti, näitä päinvastaisia on jokunen näkynyt. Mutta siis liukuhihna Applen prosessoreisssa ei ole dokumentoidusti ollut millään merkittävällä tavalla lyhyempi kuin Intelin/AMD:n tuotoksissa kuten väitit aikaisemmin, mikä lienee ollut vain omaa vailla pohjaa olevaa spekulaatiotasi.
Backporttausesta siis. Sinä väität sinisin silmin että siinä ei ole mitään ongelmaa – minä väitän että on. Se prosessorille hirveällä vaivalla ja laskentakapasiteetillä laskettu layoutti menee aivan vituiksi jos sitä yritetään kasvattaa reilusti aiottua suuremmaksi. Ei vaan siis voi onnistua. Nythän vastaväitteenä tulee tietenkin että Intel teki kuitenkin, no siltä se ehkä yksinkertaisesta näkökulmasta näyttää mutta olen melko varma että siellä on täysin uusiksi laskettu ytimen layoutti, eli Intel on suunnitellut 14nm:lle uuden prosessoriytimen. Tähänhän vähän viittaisi nimikin eli eri ytimelle annetaan eri nimi.
Mistä päästään asiaan Skylake. Taisit vaihteeksi hakata sitä päätäsi seinään kun kerroin että Skylake ja Skylake-x omaavat saman coren, tietohan oli peräisin suoraan Intelin esitelmästä. Sinulta se meni yli hilseen. Skylake-extended omaa peruscoressa joitain pieniä muutoksia ja tilaa vaativat palikat on vain liitetty kylkeen – tämä osoittaa kuinka helvetin vaikea ja kallis se prosessoriytimen layoutti oikein on, ei sitä huvin vuoksi suunnitella moneen kertaan.
Ei ole. Ja luotto siihen maagiseen Rosetta 2:eenkin on sitä luokkaa, että Cinebenchistä puskettiin ulos uusi versio natiivituella.
Perusasiat väärin jälleen kerran aivan totaalisen pielessä, asioissa joissa amatööri yrittää jälleen päteä ja neuvoa ammattilaista.
Samasta datasta voi aivan hyvin olla erilaisia kopioita eri paikoissa, kunhan ne täyttävät muistin konsistenssiusehdot. (jotka on sitten käskykanta-arkkitehtuurikohtaisia).
Datan eikä edes välimuistin invalidointisignaalin ei tarvitse ehtiä salamannopeasti joka paikkaan.
Se, että datasta voisi koskaan olla vain yksi versio missään tarkoittaisi sitä, että kaikkialta pitäisi olla kytkennät kaikkialle yhden kellojaksoin sisällä, että tätä ei voi tapahtua, ja oltaisiin jossain 100 MHz kelotaajuusloukassa jollain monen piilastun EPYCillä.
Esim. kahden eri ytimen store-puskurissa voi aivan hyvin olla kirjoitus samaan osoitteeseen.
Samoin ytimillä 1 ja 2 voi olla välimuistissaan sama data siten että ydin 1 kirjoittaa sinne uuden arvon kellojaksolla N ja ydin 2 lukee vanhan arvonsa kellojaksolla N+1, tai N + 10.
Tämä on täysin sallittua, kunhan näiden muistioperaatioidien välissä ei ole tapahtunut muita muistioperaatiota siten että muistin konsistenttiussäännöt rikkoontuvat.
Mistä ihmeen 64 bitin osoiteavaruudesta nyt oikein höpiset?
Ei siellä ole mitään 64-bittistä osoiteavaruutta. Fyysiset osoitteet on nykyisillä x86-64-mikroarkkitehtuureilla n. luokkaa 44 bittiä ja osumatarkkuus nyt pitää tehdä täydellä bittileveydellä kaikista mahdollisista osotteista, mitä sinne ävlimnusitiin pitää säilöävälimuistiin voidaan säilöä.
Todella typerää on todellisuduessaa se, että kuvittelet että välimuistin TAG-tarkastuksesta voitaisiin jotenkin "säästää bittejä", etkä näe tässä mitään ognelmaa, vaikka kuinka yrittää asiaa vääntää rautalangasta.
Mutta joo, ei tunnu menemään kaaliin. Kun on lusikalla annettu, ei voi kauhalla vaatia.
Mitkään Applen omasuunnittelemat CPU-ytimet ei ole "julkisesti dokumentoitu", Apple ei ole koskaan julkaissut mitään tarkkoja speksejä itsesuunnittelemistaan prossuista.
Sen sijaan esim. anandtech on tehtyt testejä niiden haarautumisennustushudeista , ne löytyy googlella ja niistä käy ilmi että haarautumisenennustusvivie on A6lla 12 kellojaksoa joka on n puolet siitä mitä väitit.
The iPhone 5 Review
http://www.anandtech.com
[/quote]
Ei löydy kuin nuo Geekbench testit
Mac Benchmarks – Geekbench Browser
OpenCL testissä Apple M1 saanut 19579
Macmini9,1 – Geekbench Browser
browser.geekbench.com
Metal testissä Apple M1 saanut 22123
Mac mini (Late 2020) – Geekbench Browser
browser.geekbench.com
Eli jaksat vääntää MESI-protokollaa edelleenkin joksikin muuksi kuin mitä se on. Se pitää vain cachet synkroonissa, eikä siinä tarvitse minkään tapahtua yhden kellojakson viiveillä tai ylipäätään millään määritetyillä viiveillä. Ongelma on ratkaistu niin että ennenkuin prosessori voi kirjoittaa cacheen tämä cache pala on eksklusiivisessä statessa ts. kaikki muut datan kopiot muissa cacheissa on invalidoitu ENNEN tätä kirjoitusta, jonka jälkeen MESI-protokolla voi myöntää cachelinjalle eksklusiivisen staten. Store puskurissa voi olla mitä vain, se odottaa siellä kunnes cachen state on eksklusiivinen ja se voidaan kirjoittaa cacheen. MESI-protokolla ei mitenkään yritä ratkaista monisäikeisen ohjelmoinnin ongelmia johon tarvitaan lukitussäännöt datalle, sen ainoa tehtävä on pitää cachen sisältö joka kellojaksolla yhtenäisenä.
Osoiteavaruuden määrä ei ole nyt tästä pointti, älä aina yritä vängätä huomiota pois oleellisista asioista.
Se L1-data pitää saada sieltä cachesta mahdollisimman nopeasti ja energiatehokkaasti ulos. Ei siinä kannata tarkistaa koko osoiteavaruutta mahdollisimman nopeasti polttaen vähintään turhaan energiaa, pahimmassa tapauksessa rajoittaen myös mahdollista maksimikellotaajuutta. Esim AMD:n dokumentoiduissa toiminnassa data voidaan hyvin lukea L1:stä mikrotagin perusteella ja täysi tagi voidaan liukuhihnoittaa vaikka L2:n puolelta käskyn retire-puolelle – prossun kriittiseltä nopeutta rajoittavalta polulta on näin saatu pois suurinpiirtein puolet cacheluvun datasta.
A6 on 32-bittinen arkkitehtuuri. A7 on ensimmäinen 64-bittinen ja TÄYSIN eri arkkitehtuuri. Tuosta Cyclonesta on tietoja, mm ROB 192, integer-pipeline 16 ja FP 19 kellojaksoa. Löytynee vaikka wikichipistä ja monesta muusta paikasta.
No niin on Applen A7 Cyclonen fp-liukuhihnakin. Taitaa sekä integer että fp-liukuhihnat olla tasaman samanpituiset. Sama suunnittelijikan ollut mukana kummankin tekemisessä.
Mihin oikein vastailet, lopeta se pääs hakkaaminen seinään ettei viimeinenkin järki katoa. Puhe oli tietenkin Apple A7 ja eteenpäin joiden liukuhihnojen pituus tiedetään ja L1-latenssi on 3 ja koko on 128 kilotavua. Sinähän väitit jotenkin että tuo L1 cachen koko ja latenssi osoittaa että liukuhihnan pituus ei ole yhtäpitkä kuin Intelillä/AMD:llä, kuitenkin löytyy prosessori joka osoittaa väitteesi aukottomasti vääräksi.
No kuten jo aikaisemmin kerroit, älä siirrä omaamiasi yksinkertaisia asioita monimutkaisempiin. Tottakai Skylake on suunniteltu heti alusta pitäen yhtenäisenä niin että siitä voidaan valmistaa kahta versiota. Peruslayoutti on työpöytäversiossa ja Extended servereissä, extended versio on selkestä hiukan outo design jossa ylimääräinen AVX512-unitti ja L2-cache on peruslayoutin neliön ulkopuolella. Intel on itse asian kertonut ihan avoimesti ja asia on varmistettu dieshoteilla mutta sinä tiedät kuitenkin asian paremmin, anteeksi vain jos en pidä sinua tässä asiassa luotettavimpana lähteenö.
Jep varmaan ollut juuri tuo syy, että halutaan tuoda natiivi sovellus tarjolle.
Mitä väliä Rosetta 2:n suorituskyvyllä edes on kun kaikesta tulee hyvin nopeasti natiiviversiot?
Eikö näillä nyt ole kuitenkin tarkoitus ajella pääsääntöisesti pelkkiä natiivisoftia hyvinkin pian?
Alkaakohan nyt inteliäkin arm kiinnostamaan ja onko tuossa mahdollisuus, että x86 arkkitehtuuri alkaa hiipua pois?
Tietysti tuodaan natiiviversio, koska kaikesta muustakin tulee natiiviversio.
Ei kai M1:n todellista suorituskykyä kannata muulla kuin natiivibenchmarkeilla arvioidakaan. Toki hauska nähdä lukemat myös Rosettan läpi eri benchmarkeissa, vaikka sillä ei kauaa väliä olekaan.
(vai oliko kommenttisi sarkasmia") )
)
Apple Silicon M1 Emulating x86 is Still Faster Than Every Other Mac in Single Core Benchmark
http://www.macrumors.com
Suorituskyvyn pudotus näyttää olevan yhden ytimen osalta (-23%) samalla tasolla kuin A12Z pohjaisen Developer Transition Kitin kanssa. Useamman ytimen testissä suorituskyky putoaa kuitenkin vain 21%, kun Developer Kitillä pudotus oli 39%. Ero johtuu ilmeisesti siitä, että M1 tunnistuu 8-ytimiseksi, kun A12Z vain 4-ytimiseksi. Molemmat on todellisuudessa 4+4 big.LITTLE prossuja. Lisäksi Rosetta2:n kautta ajettaessa kellotaajuus on Geekbenchin mukaan aina 2,4Ghz. Liekkö tuolla sitten jotain vaikutusta?
Todennäköisesti prosessorin kellotaajuus ei ole rajoittunut 2.4GHz:taan rosettan kanssa, vaan ainoastaan x86-emuloinnin läpi se geekbenchin executable ei näe oikein niitä fyysisiä kellotaajuuksia.
Ei löydy
apple/ax/a7 – WikiChip
en.wikichip.org
Ax – Apple – WikiChip
en.wikichip.org
Tuolla ei puhuta mitään liukuhinnan pituudesta.
Mutta LLVMn lähdekoodeista vihdoin löytyi, haarautumisennustushuti Cyclonessa on sen mukaan lyhimmillään 14 kellojaksoa.
Tosin samassa koodissa sanotaan Cyclonen L1-viiveeksi 4 kellojaksoa, ei kolme, mikä tiedetään Applen nyky-ytimien L1-viiveeksi, ja samoin monen muunkin käskyjen viiveiden tiedetään lyhentyneen, esim, fadd on lyhentynyt 4->3 kellojaksoon ja kokonaislukujen kertolasku on lyhentynyt 4 -> 3 kellojaksoon. Tämä taas vihjaisi siihen, että liukuhihnaa on Cyclonen jälkeen lyhennetty.
Suurimmassa osassa prosessoreita skalaaripuoli on lyhempi kuin liukuhihnapuoli, koska skaalaripuolella ei usein ole mitään muuta enempää kuin kolmea kellojaksoa kestäviä liukuhihnoitettuja käskyjä kuin lataukset (jakolasku ei usein ole liukuhihnoitettu), ja suurin osa kokonaislukupuolen käskyistä suoritetaan yhdessä kellojaksossa.
Liukuluvuilla taas FMA kestää tyypillisesti 4-5 kellojaksoa, mutta on täysin liukuhihnoitettu.
Pelkkä uteliaisuus ei nyt riitä kun faktat on ihan muuta:
Ensinnäkin, Applen nykyprosessoreissa ei taida olla mitään 256-bittisiä muistioperaatiota. Siellä on tietääkseni vain 128-bittinen SIMD-datapolku.
Toisekseen, Zen3 ei tietääkseni pysty tekemään kolmea 128-bittistä lukua eikä kahta 128-bittistä talletusta vaan vain 3 64-bittistä lukua ja 2 64-bittistä talletusta.
Kolmannekseen, Zen3 ei pysty tekemään enempää kuin kolme muistioperaatiota kellojaksossa. Jos tehdään 3 latausta, ei tehdä yhtään tallennusta, ja jos tehdään kaksi tallennusta, tehdään vain yksi lataus. Applen uudet prossut tekee kaksi latausta + yksi tallennus + yksi JOMPI KUMPI, yhteensä 4 / kellojakso.
Applen CPU:t -keskustelu (M1…)
bbs.io-tech.fi
L1-viive Applella on 4 kellojaksoa monimutkaisille osoitteille ja 3 yksinkertaisille. Sama yhden kellojakson ero useimmilla x86-prosessoreillakin.
Tarkoitin siis että sekä Zenissä että Applen A7:ssa kokonaiskuhihna 16 pitkä ja liukuluku 19. Ainakin ovat hyvin lähellä samoja mittoja.
AMD:n omassa diassa oli mainittu poikkeukseksi vain 256-bittiset operaatiot, jossain tosin huomasin jonkun väittävän että koskee vain kokonaislukupuolta. Taivun AMD:n oman dian kannalle tässä vaiheessa.
Juu Applen prossu taitaakin pystyä jo neljään operaatioon,
Juu lukitus on hankalaa. Eli jotta vältyttäisiin bugiselta koodilta pitää toimia vähän vaikeasti, eli esimerkiksi lukea lukituskoodi, todeta se vapaaksi, kirjoittaa sitten oman threadin lukituskoodi lukkoon ja sen jälkeen tarkistaa että siellä on nimenomaan oman threadin lukituskoodi eikä jonkun muun. Ja jos siis suoraan vain lukee ko. lukituksen koko suoritus pysyy prosessorin sisällä eikä cache-koherenssius auta asiaa. Eli prosessorin sisäiset puskurit pitää ensin flushata jne. No onneksi noita lukitusschemejä on ihan riittämiin valmiina että ei niitä itse juuri kenenkään tarvitse itse hallinnoida ja debugata.
Ja jos kaksi kirjoitusta samaan osoitteeseen koskee jotain muuta kuin lukitusta niin voisi melkein sanoa että ongelma ei ole raudassa….. kilpailuasetelma, bugi jossa ko. osoitteen lopullinen arvo on tuurista kiinni.
Tässä tapauksessa muisti ei ole yhtenäistä, eli on tilanne että muistissa on samasta datasta kaksi eri versiota. Nyt jos meillä on esimerkiksi lukitus jossa vain luetaan lukon arvo ja sen näyttäessä vapaata kirjoitetaan sinne lukitus ja hypätään operoimaan jaettuun dataan toinen threadi voi lukea lukituksen vanhan arvon omasta välimuististaan ja hypätä myös kirjoittamaan samaan data-alueeseen eli lukitus ei toimi ja data korruptoituu. MESI-hoitaa kyseisen ongelman sillä että kirjoitus onnistuu vain eksklusiiviseen cachelinjaan – protokolla invalidoi ko. linjan muista cacheista ennenkuin ytimelle annetaan oikeus kirjoittaa ko. linjaan.
Prosessorin muistikonsistenttiussäännöthän taas eivät suoraan ole sidoksissa välimuistikoherenttiuteen, eli vaikka välimuisti olisi koherenttia jos prosessori voi kirjoittaa välimuistilinjoille vapaassa ( eli ei ohjelman käskyjärjestyksessä) järjestyksessä se saattaa kirjoittaa lukituskoodin cachelinjalle joka on välimuistissa enenkuin data jota ko. lukitus on suojannut on poistunut store-bufferista välimuistiin – ja joku toinen threadi voi todeta lukon olevan vapaa ja lukea lukituista datoista vanhoja versioita – ja data korruptoituu muistin epäkoherenssiuteen vaikka itse välimuistit ovat 100% synkronoitu.
Itehän olen sen verran ehkä naiivi että en näe total store-orderille mitään tarvetta, jos lukituksen muut osat saa kuntoon niin kyllä siihen pitäisi saadan synkronointikäskytkin sovitettua mukaan ihan ogelmitta. Mutta ainakin osa tyypeistä jotka näitä työkseen tekee näkee tuon TSO:n vähentävän bugeja, ja kait muutakin kuin että buginen koodi toimii sattumalta.
Ja MESIä kai käyttää vämuistikoherenssiprotokollana nykyään kaikki kun se on siihen hommaan sangen hyvä, ainoa puute on hidas kirjoitus jaettuun dataan. Voisihan sitä leikitellä ajatuksella että prosessorin annetaan kirjoittaa jaettuun dataan suoraan ja suorittaa invalidointi vasta sen jälkeen, mutta mitä käy jos kaksi prosessoria toimii näin yhtäaikaa? Mesihän on siitä harvinainen tapaus että se vaikuttaa olevan täydellinen, alkuperäiseen oon nähnyt lähinnä Intelin F(orward)-lisäyksen eli jaettuun dataan annetaan vain yhdelle oikeus jakaa sitä eteenpäin, vähentää koherenssiliikennettä.
Ja @Sami Riitaoja käytä foorumin lainaus-toimintoa sen sijaan että kirjoitat useamman peräkkäisen viestin ketjuun, kiitos
Apple's M1 Chip Cinebench Results: Lots of Room for Improvement | Tom's Hardware
http://www.tomshardware.com
Tuo tuloshan lienee Applen kehityspöntön A12Z-prosessorin tulos, esimerkiksi M1:n ST kellotaajuus on 3,2GHz eikä 2.5. Jokatapauksessa tulos on epäilyttävän alhainen.
Näyttäisi tosiaan täsmäävän tuon dev kitin tuloksiin mitä tuohon oli kaivettu.
On aiheesta jo siellä keskusteluaihe, mutta väki kommentoi edelleen tänne. Ehkä tämä ketju kannattaisi lukita.
Applen CPU:t -keskustelu (M1…)
bbs.io-tech.fi