Intel kertoi hiljattain pääarkkitehti Raja Kodurin johdolla uutta tietoa Xe-arkkitehtuurista ja etenkin Xe-LP-arkkitehtuurista. Nyt yhtiön GPU-pääarkkitehti David Blythe on kertonut Hot Chips 32 -verkkomessuilla tarkemmin eri Xe-arkkitehtuurien yhtäläisyyksistä ja eroista.
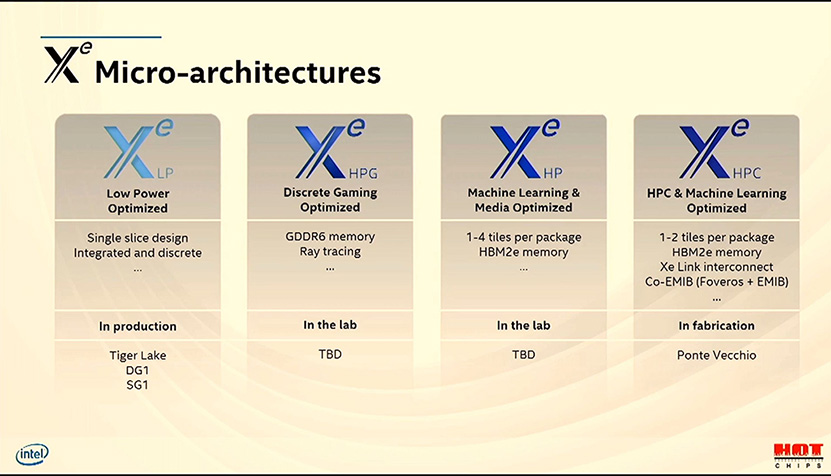
Kuten jo Architecture Day 2020:n uutisoinnissa kerroimme, Xe-arkkitehtuuri jakautuu neljään mikroarkkitehtuuriin. Xe-LP kattaa integroidut ja kaikkein edullisimman luokan näytönohjaimet, pelinäytönohjaimiin suunnattu Xe-HPG kattaa keskiluokan ja high-endin, Xe-HP datakeskukset ja tekoälylaskenna ja lopulta Xe-HPC eksaluokan supertietokoneet. Kaikki neljä jakavat tiettyjä peruselementtejä, mutta niissä on myös merkittäviä eroja.
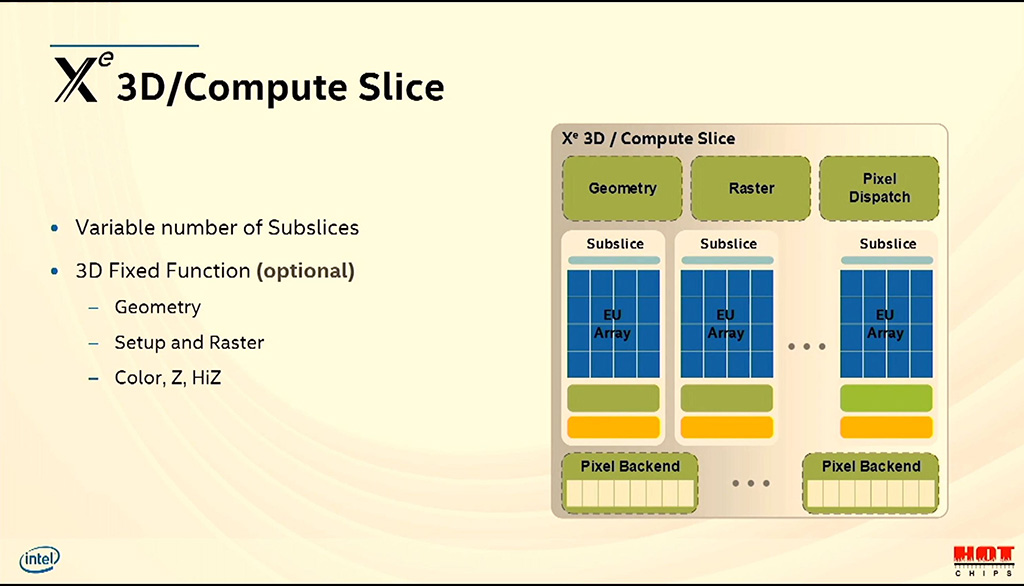

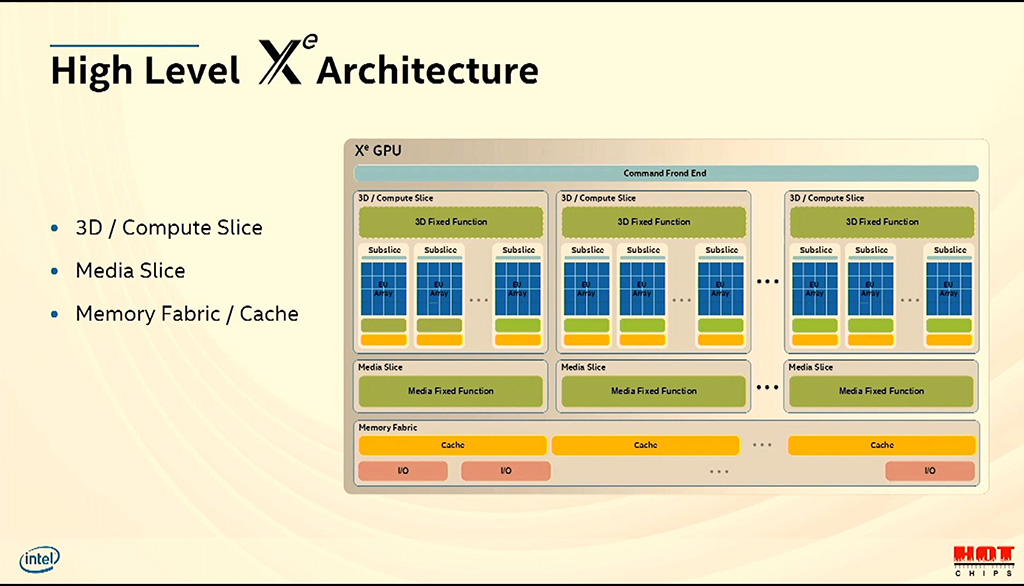
Korkealla tasolla kaikki Xe-arkkitehtuurit jakavat samat elementit: 3D- ja laskentayksiköt (Slice), mediayksiköt ja muistiverkon. Yhteen 3D- ja laskentayksikköön kuuluu valinnaiset ns. fixed function -yksiköt, eli vain tiettyjen tehtävien suorittamiseen optimoidut yksiköt. Näihin lukeutuvat tässä yhteydessä geometriayksikkö, rasterointi, väri- ja z-testaus ja niin edelleen.
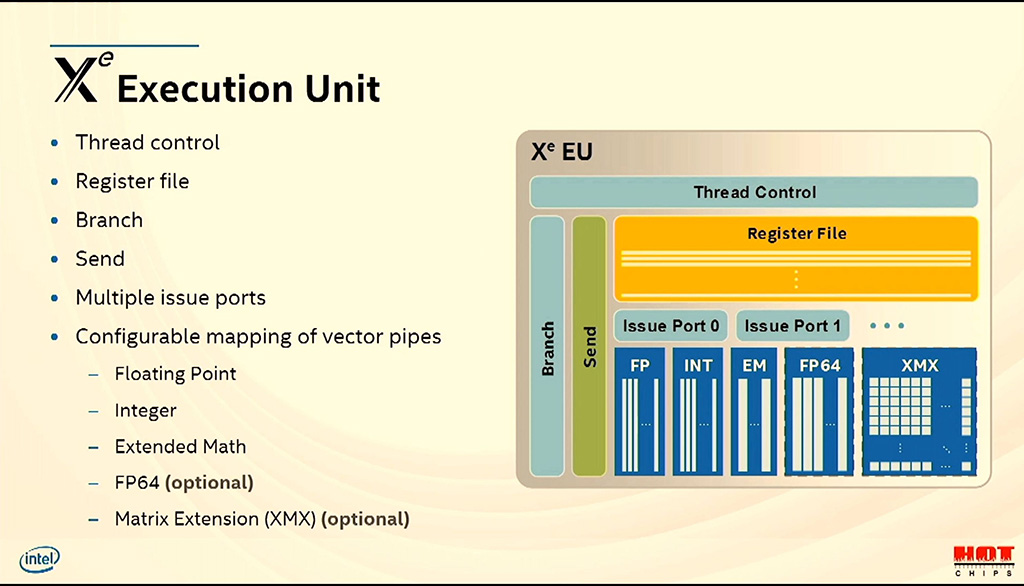
3D- ja laskentayksikkö sisältää vaihtelevan määrän aliyksiköitä (Subslice), jotka rakentuvat 16 Execution Unit -yksiköstä, säikeiden lähetysyksiköstä, välimuisteista ja load- ja store-yksiköistä sekä valinnaisista fixed function -yksiköistä, joihin kuuluvat 3D-sampleri, mediasampleri ja säteenseurannan kiihdytys. EU-yksiköt sisältävät puolestaan säikeiden hallinnan, rekistereitä, haarautumisyksikön ja vaihtelevan määrän erilaisia laskentayksiköitä, joista FP64- ja Matrix Extension -yksiköt ovat valinnaisia.


Mediayksikköihin kuuluu puolestaan kolmen tyyppisiä fixed function -yksiköitä: MFX, SFC ja VQE. MFX-yksiköt hoitavat pakkaus-, purku- ja transkoodaustyöt, SFC skaalauksen ja eri formaattien muunnoksen ja VQE videon laatuun vaikuttavia toimintoja. Mediayksiköitä voi olla rinnakkain useampia ja ne voivat jakaa myös saman mediavirran useamman yksikön kesken.
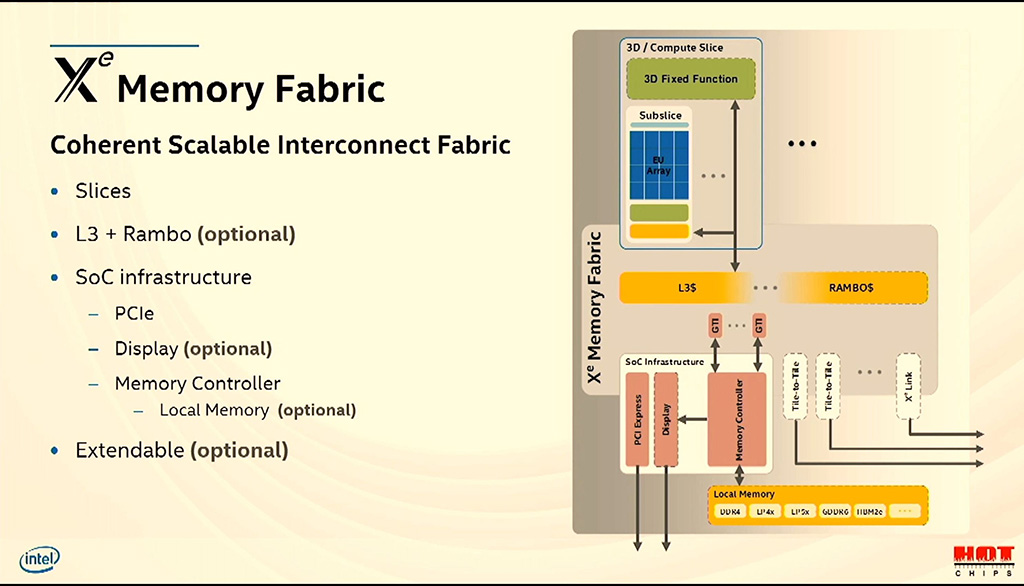
Muistiverkko eli Memory Fabric yhdistää eri yksiköt toisiinsa ja saman sirun muihin toimintoihin. Siihen kuuluvat muun muassa L3-välimuisti sekä valinnainen, Xe-HPC:sta löytyvä Rambo-välimuisti, järjestelmäpiirin muut väylät kuten PCIe-tuki, muistiohjaimet valinnaisella paikallisen muistin tuella sekä valinnaiset näyttöohjaimet. Muistiverkko on myös laajennettavissa tarvittaessa. Sen avulla arkkitehtuuria voidaan skaalata tuhansiin EU-yksiköihin ja useampiin siruihin.
Xe-arkkitehtuuri tukee myös useamman sirun yhdistämistä samaan paketointiin ja tätä hyödynnetään ainakin 1 – 4 sirua tai Intelin sanastolla Tileä hyödyntävässä Xe-HP:ssa. Eri sirut on yhdistetty toisiinsa EMIB-silloilla ja sen kerrotaan mahdollistavan eri sirujen ajamisen joko yhtenä isompana GPU:na tai neljänä erillisenä GPU:na. Xe Link -ominaisuus mahdollistaa puolestaan mahdollistaa eri sirujen yhdistämisen myös eri paketointien välillä, mitä hyödynnetään Xe-HPC-arkkitehtuurissa.
Esityksessä käytiin läpi uudelleen myös Xe-LP, johon voit tutustua aiemmassa uutisessamme.
Lähde: AnandTech
Mihis perustat mutusi?
Luuletko, että Intelillä ei olisi ollut suunnitteilla eirilaisia palikoita yhdistäviä ratkaisuja, vaikka kuinka paljon?
SItähän mä kysyin onko noita toteutuksia vertailtu. En tiedä onko tää eka lappu missä on mainittu koko asiasta vai vanhaa tietoa.
Pelkästään se, että erilliset piirit yhdistetään EMIB-ratkaisulla kertoo, että Intelin systeemi on reilusti nopeampi. EMIB mahdollistaa moninkertaisesti nopeamman ja energiatehokkaamman tiedonsiirtokanavan, kuin AMD:n paketointimenetelmät.
Onko sinulla jotain perusteita tän taakse? Noiden nopeuksista tuntuu olevan vaikea löytää mitään tarkkoja lukuja, mutta EMIB ei ollut edes intelin mielestä nopeampi kuin "tavalliset interposerit" ainakaan pari vuotta sitten, "suurin piirtein yhtä nopea" ja seuraavan kommentin huomioiden todennäköisesti hieman hitaampi (mutta sitten on muita etuja)
Bridges Vs. Interposers
semiengineering.com
AMD ei ole myöskään rajoittunut mihinkään "omiin paketointimenetelmiin" vaan on käyttänyt esimerkiksi Vega 20:ssa TSMC:n CoWoSia, minkä tuoreimmalle versiolle huudellaan 2,7 Tt/s nopeuksia
Emib on suorituskyvyltään nähdäkseni hyvin samanlainen kuin täysi silicon interposer, mutta sen pitäisi olla paljon halvempi, koska valtavan piipalan (CoWoS interposer voi olla 1000mm²) sijaan tarvitaan vain pieni yhdistävä silta (kymmeniä neliömillejä per yhdistettävä piiripari). Se myös skaalaa vaikka kuinka isoihin implementaatiohin siinä missä maksimi reticle size käsittääkseni rajoittaa interposerin kokoa.
AMD:n infinity fabric toimii tavallisilla johdinvedoilla paketoinnissa tai jopa socketien välillä ja on dekadia hitaampi väylä kuin mihin interposerilla toteutetut väylät pystyvät.
Infinity Fabric (IF) – AMD – WikiChip
en.wikichip.org
Samalla paketillakin sähkö kuluu 2pJ/B nopeutta on luokkaa 50GB/s.
EMIB:llä on mahdollista toteuttaa esim. HBM2 stäckin kommunikaatio ja sähköä kuluu tämän mukaan 0.3 pJ/B.
Intel's New Omni-Directional Interconnect Combines EMIB, Foveros – ExtremeTech
http://www.extremetech.com
IF ei ole mihinkään tiettyyn fyysiseen toteutukseen sidottu linkki, miten ihmeessä sitä voi EMIBiin verrata? Eikö kyse ollutkaan paketointiteknologioista?
EMIBin suorituskyky oli "samankaltainen" kuin interposerit pari vuotta sitten, nykyinen CoWoS kykenee jo 2,7 Tt/s:n vauhteihin ja maksimikoko on 1700mm^2, ei 1000mm^2, reticle-rajat on jo kierretty.
EMIB skaalaa siinä mielessä, että niitä voi olla monta, mutta sen koko ei vissiin hirvittävästi skaalaudu? Ja nopeuteenhan vaikuttaa luonnollisesti myös koko (montako pinniä saat mahtumaan määrää paljonko dataa voi liikkua, siksi CoWoSinkin maksiminopeudet ovat niin korkeita kun ovat, kun tilaa on)
Sekä Nvidia, että amd ovat tutkineet multi chip gpu mahdollisuuksia jo vuosia. Ja luultavasti Intelkin on ihan omin päinkin asiaa selvitellyt. Se, että onko Koduri Intelillä asiaan vaikuttanut… Epäilen, jollei tietoa ole vuotanut jo ennen Koduri Intelille siirtymistä. Sen verta kauna näihin suunnitteluhan kuitenkin menee aikaa. Intelillä lienee eniten rahaa kokeilla, josko tämä futaa, joten propsit siitä!
Ovat selvästi harkinneet ja lähteneet koittamaan tätä sirujen sitomista toisiinsa. Tämä on ainakin väliaikaisesti (joitakin vuosia) tie suurempaan tehokkuuteen, mutta tämänkin suhteen tulee raja vielä joskus vastaan. Näin pelimiehenä PC-pelaamisen saralla kiinnostaa kuinka tehokkaan näytönohjaimen he tuolla tavalla saavat aikaan, jos päättävät yhdistelyä hyödyntää kotikonetuotteissaan. Fiksu lähestymistapa tällä viisiin, vaikka joutuuhan noita siruja kanssa sitten tuottamaan roppakaupalla kun katetaan eri markkinoita. Sirujen muokattavauus eri käyttötarkoituksiin myös fiksua.