
Intelin 11. sukupolven Core -työpöytäprosessoreiden toimitukset eivät ole ehtineet vielä edes alkaa, mutta huhut ja vuodot seuraavan sukupolven Alder Lake -prosessoreiden ympärillä käyvät jo kuumina. Tällä kertaa vuorossa on VideoCardzin käsiinsä saamia väitettyjä vuotodioja.
VideoCardzin käsiinsä saamassa diassa käydään läpi yleisesti Alder Lake -arkkitehtuurin uudistuksia keskittymättä mihinkään tiettyyn verisoon, kuten S tai P. Dian mukaan arkkitehtuuri tarjoaisi uusien Golden Cove -ydinten myötä parhaimmillaan 20 % parempaa yhden säikeen suorituskykyä, mutta diassa ei mainita onko verrokkina työpöytäpuolen Cypress Covet vai mobiilista tutut, sukupolvea uudemmat Willow Covet. Prosessorit valmistetaan parannetulla 10 nanometrin SuperFin-prosessilla.
Monisäikeisen suorituskyvyn kerrotaan paranevan puolestaan parhaimmillaan jopa kaksinkertaiseksi uusien Gracemont-ydinten ja rautaohjatun skeduloinnin ansiosta. Prosessoreissa on enimmillään kahdeksan Golden Cove- ja kahdeksan Gracemont-ydintä. Koska vain Golden Cove -ytimet tukevat Hyper-threading-SMT-teknologiaa, voi prosessorin yhteensä 16 ydintä suorittaa samanaikaisesti maksimissaan 24 säiettä.
Muita uudistuksia Alder Lakessa on tuki uusimpien sukupolvien väylille, eli tässä tapauksessa PCI Express 4.0- ja 5.0 -standardeille, Thunderbolt 4:lle sekä Wi-Fi 6E:lle. Muistipuolella tuettuina ovat DDR4-, DDR5-, LPDDR4 ja LPDDR5. Näytönohjaimen virkaa toimittaa Xe-LP-arkkitehtuuriin perustuva integroitu grafiikkaohjain. Thunderbolt -tuki on ainakin työpöytäpuolella tuki erilliselle ohjainpiirille ja Wi-Fi-tuki on integroitu 600-sarjan piirisarjaan.
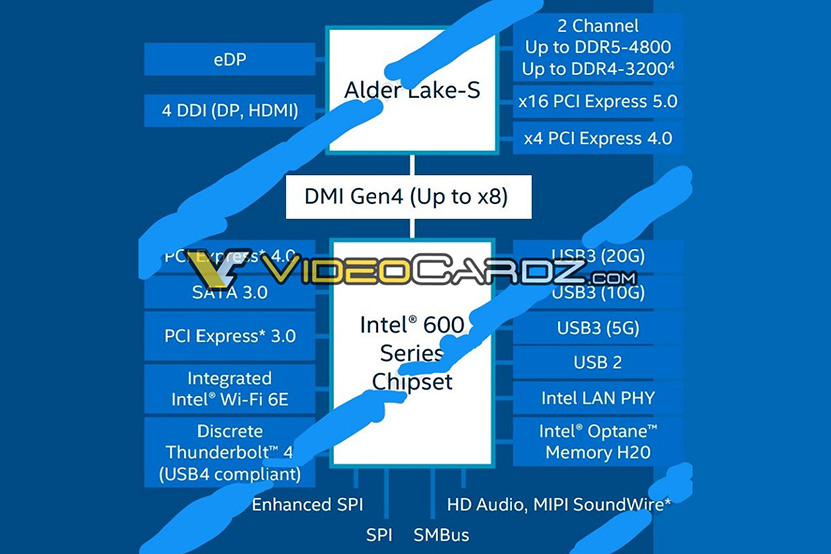
On mahdollista ja jopa todennäköistä, että LPDDR-muistituet on rajoitettu mobiilivariantteihin, sillä toisessa Alder Lake-S -malleja spesifisti käsittelevässä diassa mainitaan prosessorille DDR4-3200- ja DDR5-4800 -tuet. Lisäksi prosessorissa mainitaan olevan 16 PCI Express 5.0 -linjaa, neljä PCI Express 4.0 -linjaa ja kahdeksan DMI Gen4 -linjaa (PCIe 4).
600-sarjan piirisarjoissa kerrotaan puolestaan olevan sekä PCIe 3.0- että 4.0 -linjoja, SATA 3.0 -väyliä ja jo edellä mainittu intgroitu Wi-Fi 6E -ohjain. Thunderbolt 4 -tuki toteutetaan erillisellä piirisarjaan yhdistetyllä ohjainpiirillä. USB-puolella on tuettuna tuntematon määrä USB3-väyliä 5, 10 ja 20 Gbps:n nopeudella. Piirisarja tukee myös Optane Memory H20 -välimuisteja ja siitä löytyy Intelin integroitu verkko-ohjain.
Lähde: VideoCardz
”Monisäikeisen suorituskyvyn kerrotaan paranevan puolestaan parhaimmillaan jopa kaksinkertaiseksi uusien Gracemont-ydinten ja rautaohjatun skeduloinnin ansiosta.”
Kiinnostaisi kyllä tietää, että miten Intel on saanut noista Gracemont-ytimistä puristettua kaksinkertaisen suorituskykyedun irti? Ja mikäli vuoto vain pitää paikkaansa, joudutaan varmaan odottelemaan 13 sukupolven Core-suorittimia että saadaan i9-prosessoriin 10 ydintä tai enemmän.
Helposti kun koko arkkitehtuuri pistetty uusiksi ja siinä on otettu huomioon menneiden arkkitehtuurien heikkoudet, joissa AMD vie Inteliä aika pitkälti kuin pässiä narussa, kuten juuri multi-threadingissa. Voisi siis olettaa että intelin alder lakeissa on keskinmäärin enemmän ytimiä vrt. esim. tähän viimeisimpään intelin 8-ytimiseen lippulaiva -suorittimeen ja tehonkulutuskin varmaan pienenee merkittävästi.
Ei ole siis sinänsä iso saavutus jos monisäikeistyvyydessä päästään vihdoinkin oletetulle tasolle, kun muistiohjainkin uudistuu DDR5:sta tukevaksi.
Jos vaikka verrataan 4 ytimiseen tigerlakeen, niin 8+8 ytimisellä alderlakella saa varmaan ihan aidosti sen 100% nopeamman monisäikeisen suorituskyvyn, ehkä jopa samalla sähkönkulutuksella. Vertailukohtaa ei ole mainittu, niin ei ton perusteella voi sanoa oikein mitään.
.. ja vain workloadeilla, joissa AVX-512sta ei käytetä mihinkään merkittävissä määrin.
Intel ajaa tässä vähän kaksilla rattailla, kun samalla mainostaa myös suuria yhden säikeen suorituskykyparannuksia tehoytimille, mutta tilassa jossa nämä tämä "kaksinkertainen" monen säikeen suorituskyky on mahdollista suorittaa, AVX-512 onkin kytkettynä pois päältä, suorituskyky joillain uusilla hyvin optimoiduilla softilla jopa huonompi.
Ei ketään varmaan ’tutisuta’. Realismi on kaunis asia ja hkultalan kommentti tiivistää asian.
Ei tutisuta yhtään, intelillä vaan on tapana perseillä vertailujensa kanssa niin paljon kun vaan ikinä pystyy ja olisi outoa jos muuttaisivat yllättäen tapansa. Tuon takia näitä lukuja on hauska miettiä, etenkin kun vuodosta puuttuu vertailukohdat. Se on varmaa että ei noi luvut ole ainakaan parhaaseen mahdolliseen intelin verrokkiin nähden missään noista prosentteina ilmoitetuista parannuksista.
Riippuu mille kellotaajuuksille saavat nämä viritettyä, mobiili tiger-laket menevät jo sen 5 GHz ja tässä pitäisi olla vielä olla yhden pykälän hiotumpi valmistusprosessi niihin verrattuna mikä lupaa ihan hyvää.
Kyllä se _joissain softissa_ voi toteutua, mutta tosiaan joissain mennään myös takapakkia.
Jos esim. turbokello nousee 5.3 => 5.5 GHz niin siitä tulee joku 3.5% lisää suorituskykyä. Tällöin tämän lisäksi tarvitaan vielä n. 16% parempi IPC että saavcutetaan tuo 20%
Tästä 16%sta joku n. 4% voi olla ytimen yleisistä pikkuparannuksia, ja 12% kasvaneista välimuisteista.
Läheskään kaikki softat ei varman hyödy 12% niistä kasvaneista välimuisteista, eikä keskimääärinen parannus ehkä ole ihan niin paljoa, mutta löytynee merkittävä määrä, joka hyötyy. Erityisesti olettaisien pelien hyötyvän tästä eniten.
Mutta AVX-512sta tukevat tosiaan ottaa sitten takapakkia jos pikkuytimet pidetään enabloituna.
—————-
Mitä muutoin tulee suorituskykyyn, niin valmistajien hehkutuksille ei kannata antaa juuri mitään arvoa. Noiden suorituskyvyn tietää vasta sitten, kun useampi iso, kolmas osapuoli on ajanut noilla kattavia testejä.
Jokos nuo on ylihuomenna lähi K-kaupassa muropakettien vieressä myynnissä vai miksi noista nyt ollaan niin innoissaan?
Itse odottelen prossua, johon olisi integroitu HBM: tyyppistä ratkaisua joku 16 Gigaa.. Kumman hitaasti edistyy. Lisämuistille voisi sitten olla vaikka pari DDR5 kanavaa.. Tai edes 8 gigaa, se kuitenkin riittää yleensä läppärissä miltei kaikkeen, mitä teen.
Myös jotkut puhtaasti muistikaistarajotteiset softat voi olla tuon 20% nopeampia, koska samalla siirrytään DDR5 muisteihin.
Käsittääkseni rocket laken kakkuja leikattiin aika tavalla, jotta se saatiin 14nm prosesille siedettävän kokoisena. Joten en yhtään ihmettelisi, että jostain löytyisi softa joka pyörii sen up-to 20% paremmin, mitä 11000 sarjalla, kun data mahtuukin kokonaan välimuistiin.
Ihan samalla tavalla 11000 sarja saavuttaa sen 19% paremman ipc:n, mutta vain tietyissä skenaarioissa. Alustavien arvostelujen valossa käytännön tehoero ei ole niin iso.
Imho. Markkinointislidet kannattaa aina nauttia hyvin suolattuna, jos vertailukohtaa ei ole määritelty tai on tuo klassinen up-to maininta. Markkinointi – selkosuomella se on aina ollut parhaan mahdollisen skenaarion lopputulos. Ladakin kulkee up-to 250km/h tarpeeksi jyrkässä alamäessä.
Tosin muistikaista tulee äärimmäisen harvoin vastaan yhdellä säikeellä. Useammin yhden säikeen suorituskyky vaan kärsii kavaneista viiveistä.
Aivan, monisäikeisten softien kanssa tilanne on sit parempi.
Joku tarkoitushakuinen avx-512 testi voisi tuohon ehkä kyetä, pitäisi tarkemmin lukea vähän datasheettiä.
Valtaosa perus läppärin käyttäjistä ei tuosta AVX-512:sta hyödy oikeen yhtikäsmitään. Eiköhän tuo ole Intelillä mietitty sen suhteen, että ne jotka sitten oikeasti AVX-512:sta kaipaa ostaa laitteen erilaisella prossulla. Perusläppäriin hyvällä akkukestolla nuo liene on ihan ok kiviä.
En sano pahalla, mutta mulla on jotenkin sellainen kutina, että käytät / tarvitset AVX-512:sta kovasti ja on nyt sellainen kokemusharha/filterbubble sen "välttämättömyydestä" kun tuot sitä kovin usein esille. Eikä siinä se on ihan normaalia jos esim työkseen pulaa ongelmien kanssa jotka kannatta implementoida AVX-512:sta.
Tulee mieleen kun oli jossain CPU ketjussa liittyen 360hz näyttöihin ja kuinka yleistä se on.. Yhtenä "väittelijänä" oli joku kilpapelaaja jonka kaverit on kilpapelaajia niin se näyttää yleisemmältä tarpeelta kun on.")
Itsellä taas on toki toiseen suuntaan oleva kokemusharha kun täällä kirjoitellaan geneerista weppi tunkkia ja mitä liene datan muunnosajoja melko geneerisesti.. jos käytetyt kirjastot / vm:t / x SSE/AVX/himmeliä tukee niin kiva, mutta ei näitä käsin aleta optimoimaan tietyille käskylaajennokksille ollenkaan. Eria asia sitten kannattaisiko, mutta siihen ei aikaa/rahaa anneta niin se sitten siitä.")
Ei täsäs ole kyse mistään "kokemusharhasta" vaan siitä että mietin asioita pitkällä tähtäimellä ja MAHDOLLISEN/POTENTIAALISEN suorituskyvyn näkuökulmasta, enkä siitä näkökulmasta miten JUURI TÄLLÄ HETKELLÄ eniten käytössä olevat softat pyörii.
Eli, itse en käytä AVX-512aa ollenkaan, mutta suunnittelen työkseni erikoistuneita prosessoreita signaalinkäsittelyjuttuihin, ja niissä (järeä) SIMD on aivan elinehto järkevään suorituskykyyn ja hyvään energiatehokkuuteen.
Olen suunnitellut prosessoreita joissa on vielä AVX-512aakin leveämpi SIMD-datapolku. (toki kellot paljon pienempiä ja rinnakkaisten laskentayksiköiden määrät paljon pienempiä, kun kuitenkin kyse hyvin pienistä vähävirtaisista ytimistä)
Kun halutaan oikeasti sitä suorituskyvyn kannata parasta mahdollista lopputulosta numeronmurskaukseen, ja ollaan valmiita näkemään se vaiva sen käyttämisestä, järeä SIMD on aivan ehdoton.
PC-puolella vaan ongelma on se, että softa laahaa vuosia jäljessä, peleihin alkaa vasta nyt tulla optimointeja edes AVXlle, ja yhteensopivuussyyt estää kätevästi ottamasta uusia käskykantoja käyttöön.
Paljon suorituskykyä tarvitsevia workloadeja joissa AVX-512lla ei tee mitään on esim joku selaimen javascript-tulkki tai kääntäjä, jolla käännetään koodia, tai joku palvelinsofta joka palvelee todella suurta määrää käyttäjiä.
Muuten suuri osa paljon suorituskykyä tarvitsevasta koodista on sellaista että kyllä sieltä löytyisi leveälle ja ominaisuusrikkaalle SIMD-käskykannalle paikoitellen käyttöä.
Eli ongelma on se, että kun mahdollinen tuleivaisuuden kapasiteetti ja hyöty tämän hetken softilla on ihan eri tasolla, niin tavallinen pulliainen joka ei ymmärrä asioita syvällisesti tuijottaa vaan niitä tämän hetken benchmarkkeja.
AVX-512 rikkaampien ominaisuuksiensa (mm. scatter) takia nimeomaan mahdollistaa sen, että kääntäjän on teoriassa helpompi automaattisesti (jos sille vaan annetaan lupa) vektoroida se koodi, että koodarin ei tarvitse tehdä mitään että ne SIMD-käskyt tulee joissain tilanteissa käyttöön
Tässä tulee kuitenkin ongelmaksi yhteensopivuus; Normaalit softankehitysmekanismit eivät tue sitä, että kääntäjä voisi helposti ja automaattisesti tehdä koodista monta eri versiota eri käskykantalaajennoksille ja ajonaikaisesti valita oikein, vaan koodaaja joutuu näkemään ylimääräistä vaivaa jos haluaa koodista monta eri polkua eri käskykantalaajennoksille. Tämän takia kääntäjälle tyypillisesti vaan sanotaan että "targetoi geneeristä x86-64sta" (eli SIMDn osalta joku SSE2) tai sitten "saat käyttää AVXää", mutta käytännössä mitään binäärimuodossa toimitettavaa softaa yhteensopivuussyistä voida kääntää vain AVX512-tuki päällä, koska se binääri ei toimisi suurimmalla osalla käyttäjistä.
Ja Intelin sähläys sen suhteen ettei ole tuonut AVX-512sta työpöytämalleihinsa eikä edes AVXää pikkuytimiinsä on vaan pahentanut tilannetta.
Miten haluat kommentoida väitettä, että avx 512 on hyödytön, koska sen pystyy ajamaan näytönohjaimella nopeammin/helpommin. Taisi olla @pomk joka tätä ajtusta on pitänyt esillä. Tämä vain sivusta seeuraavan näkökulmasta.
Taitaa iso osa niistä laskuista olla sellaisia, että siirtoviiveet kumoaisivat näytönohjaimella ajon mahdolliset hyödyt
Tuo ei pidä yleisesti paikkaansa, vaan sitä silloisessa keskustelussa esillä pidettyä ian cutlessin 3dpm testisoftaa ei kannata käyttää esimerkkinä tuosta syystä johtuen. Se olisi kokonaisuudessaan mahdollista toteuttaa ihan typerän paljon nopeampana GPU softana.
Kaotika jo vastasikin, kun rinnakkaisesti laskettavat asiat on pieniä ja niitä on paljon, siirtoviiveet ja ajuriviiveet näyttikselle dominoisivat ja pilaisivat suorituskyvyn, ja jos laskentaa tehdään vähän/siirretty arvo, laskenta on nopeampaa CPUlla kuin sen siirtäminen näyttikselle ja takaisin.
Geneeristen rinnakkaisten asioiden laskeminen näyttiksellä toimii hyvin kun kaikki seuraavista ehdoista toteutuu
1) Jokaista siirrettyä arvoa kohden tehdäään tarpeeksi paljon laskentaa, että siirron kaista ei ole niin paha pullonkaula, että CPU laskisi sen nopeammin. Tässä puhutaan nykyään suuruusluokkaa ~100 laskuoperaatiosta/siirretty lukuarvo.
2) Jokainen rinnakkaisesti suoritettava koodialue on laskennan määrältään tarpeeksi pitkä että ajurioverhead ja tiedonsiirron latenssi ei tule pullonkaulaksi.
3) Koodari jaksaa nähdä vaivan siitä, että nysvää sen datan sinne näytikselle laskettavaksi, eli kirjoittaa koodinsa esim. OpenCL:llä. Tässä on tyypillisesti selvästi enemmän nysväämistä ja vaivaa kuin SIMDille optimoinnissa, tosin tähän on tulossa uusia helpompia rajapintoja.
Kiitos selvennyksestä.
Pahoittelut, että muistin/ymmärsin väärin.
Tuo toki mutta jossain on se järjellinen raja kuinka leveitä laskureita kannattaa vääntää geneerisen CPU:n jokaisen coren sisään. Se missä se raja sitten menee en osaa sanoa, mutta ilmeisesti low power corejen kohdalla sinne ei haluta 512b.
Ihan sillä pohdin, kun SIMD yksiköitä halutaan jatkuvasti leventää (ja ihan syystä).. missä tulee se raja, että ne pitää heivata sieltä coresta ulos, mutta johonkin lähemmäksi kuin ulkoisen väylän toisessa päässä kuten dGPU. 4, 64, 128kbit?
Tuli vaan mieleen tuo coren ulkopuoelle sijoittaminen, kun nyt AMD:llä on hinku FPGA vireveiltä paketoida CPU:n lähelle. Toisaalta aikoinaan se FPU oli ulkoisena resurssina. Ei toki ihan triviaalia, kun sitten corella ei enää ole kontrollia siihen resurssiin samalla tapaa + kaikki cache coherencyt ja viiveet yms.
Toki olisi kivan helppoa jos aina voisi legacyt vaan heivata olan yli.. kokemusta on sentäs softapuolelta, tänään sai ihmetellä jotain viime vuosituhannen koodihirviöitä joista toki ei ole mitään dokumentaatiota missään..
Intelhän on tarjoillut jo vuodesta 2018 Xeoneita joissa on FPGA integroitu samaan paketointiin. Toki suoraan itse sirulle integroitu on vielä ison askeleen pidemmällä, mutta veikkaan että nuo tulee todellisuudessa löytymään semi-custom prossuista, ellei AMD aio sitten eriyttää palvelin- ja kuluttajaytimiä toisistaan. Kuluttajamalleissa PEU-yksiköille on vaikeampi löytää kylliksi käyttöä oikeuttamaan niiden viemää tilaa
Itse yksiköiden ei ole pakko olla täyslevyisiä, jos tyydytään hitaampaan suorituskykyyn, leveät SIMD-käskyt voi pilkkoa pieneen palaan ja suorittaa osissa, kunhan vaan rekisterifileeessä riittää kapasiteetti kaikille arkkitehtuurisille rekistereille. Esim. juuri noissa pikkuytimssä vajaalevyinen toteutus olisi hyvin järkevä, kun se haluttaiisin sinne vain yhteensopivuussyistä, että sen voi kytkeä päälle isoilla ytimillä.
Veikkaan, että Adlder Lakessa 256-bittiset AVX-käskyt suoritetaan pikkuytimillä tällä tavalla pilkkomalla ne kahteen 128-bittiseen osaan, mutta en ole varma. AVX-512 siten vaatisi neljään osaan pilkkomista 128-bittisellä datapolulla.
Samoin esim Zen1ssä oli vain 128-bittinen SIMD-datapolku, mutta silti tuki 256-bittisille AVX-operaatioille.
Ei niitä voi heittää "ytimeltä ulos" jos ne suorittaa samaa käskystreamia.
Mutta se, mitä voidaan tehdä on, että tuodaan jotain erillisiä rinnakkaisen laskennan kiihdytinytimiä (jotka siis suorittavat eri käskystreamia, joudutaan edelleen kärsimään ajuriviivettä tai vähintään synkronointiviivettä), mutta kaistaa on tarpeeksi koska väylä on nopea) CPUn kanssa samalle piilastulle, nopean sisäisen väylän päähän.
APUthan oikeastaan ovat tällaisia.
Ydin ja piiri oli eri asioita. FPU oli erillisellä fyysisellä piirillä mutta loogisesti se oli osa ydintä.
Kyllähän uusimmat näytönohjaimet tukevat PCIe 4.0:aa, ja näytönohjaimia vartenhan tuo väylä on. Eri asia tietysti on, että milloin tulevat ensimmäiset näytönohjaimet PCIe 5.0 -tuen kera ja mitä käytännön hyötyä siitä seuraa.
Massamuistit hyötyy noista enemmän kuin näyttikset. Harva uusikaan näyttis tukehtuu PCIe3 väylän takia.
Tieteellisessä laskennassa ehkä joo, mutta ei kuluttajakäytössä. Sata ssd:kin riittää todella pitkälle ja kingston a2000 riittä noupeuden osalta 99 % ja cs3030 riittääkin sitten 99,99 %.
Massamuisteilla vaan saadaan selkeitä eroja testiohjelmissa. Jos uusi levy on 40% nopeampi kuin vanha, niin vanha on hidas. Tämä siitä huolimatta että se vanha olisi ollut jo 10x nopeampi kuin mitä käyttäjä oikeasti tarvitsee. Itsellä edelleen pelkkiä sata levyjä pöytäkoneessa.
Tietokoneita ei yleensä ostella testiohjelmien ajamista varten, vaan sitä varten että sillä ajetaan joko hyötyohjelmia tai käytetään viihdekäytössä eli pelataan tms.
Ja näiden nopeudelle sillä levyn raa’alla siirtonopeudella ei ole käytännössä MITÄÄN väliä.
Sen sijaan levyn HAKUAJALLA eli viiveellä on näille paljon väliä. Käytetyn PCI-väylän versiolla ei kutienkaan ole käytännössä mitään vaikutusta tähän viiveeseen.
Jos ostetaan kaupunkiliikenteesen autoa ja valitaan kahden välillä, toinen kulkee 200 km/h ja toinen 280km/h, onko se 200km/h kulkeva hidas?
Sen sijaan jos toista pitää lämmittää minuutin ennen kuin moottori suostuu käynnistymään ja toinen käynnistyy heti sekunnissa, se sekunnissa käynnistyvä on kaikessa hyötykäytössä nopeampi.
Kyllä sen näytönohjaimen testiohjelmakin saadaan hyötymään tuosta pci-e 4.0 standardista. Mutta missään muualla tuosta ei ole hyötyä. Sama juttu ssd levyn kanssa. Toki jos harrastat kopiointia levyltä toiselle, niin sitten …
Itse siis samaa mieltä. Juuri mitään todellista hyötyä ei perus käyttäjä huomaa. Edes tehokäyttäjälle ero ei ole kovin suuri (itsellä 2x sata raid0 tuomassa kaistaa).
Mutta, se joka katsoo vain levyjen testituloksia pikaisesti uutta konetta kasatessa tulkitsee helposti niin ettei vanhalla tee mitään. Maksiminopeudet esitelty samaan tapaan kuvaajana kuin näyttisten pelinopeudet. Eihän sitä nyt voi huippukoneeseen mitään vanhaa roskaa laittaa! (/sarkasmi)
Jeh tuo pilkkominen olikin sinänsä tuttu. Oikeastaan ihan sillä kyselinkin näkemyksiäsi kun noista tiedät. Joskus oli hilkulla olisiko lähtenyt softalle vai piirisuunnittelu puolelle opiskelemaan, mutta softalle tuli mentyä. Perusteet nyt ymmärtää frontin, coren ja backendin toiminnasta, mutta siihen se sitten jää.