
AMD on esitellyt Rome-koodinimellisiä Zen 2 -arkkitehtuuriin perustuvia palvelinprosessoreita jo aiemmin, mutta nyt yhtiö on myös julkaissut uudet Epyc-prosessorit. Työpöytäpuolen Ryzen-prosessoreiden tapaan myös uudet Epycit sopivat suoraan aiemman sukupolven emolevyihin.
Kuten jo etukäteen tiedettiin, siinä missä ensimmäisen sukupolven Epyc-prosessoreissa oli maksimissaan 32 ydintä, on toisen sukupolven prosessoreissa maksimissaan 64 ydintä. Prosessorit käyttävät pikkupiirehin perustuvaa ns. chiplet-arkkitehtuuria, jossa prosessorialustalle on sijoitettu kahdeksan 7 namometrin prosessilla valmistettua pientä prosessorisirua ja yksi vanhemmalla 14 nanometrin prosessilla valmistettu I/O-siru. Prosessorisirut ovat identtisiä yhtiön 3. sukupolven Ryzen-prosessoreissa käytettävien prosessorisirujen kanssa.
AMD:n omien testien mukaan myös Epyc-puolella on saavutettu keskimäärin noin 15 % ensimmäistä sukupolvea parempi IPC (instructions per clock) yhdellä säikeellä, kun 32 ytimellä ja 64 säikeellä IPC:n kerrotaan kasvaneen peräti 23 %. Vaikka prosessoriydinten maksimimäärä on tuplattu, on muistikanavia edelleen kahdeksan ja ne tukevat Ryzen 3000 -sarjan tavoin DDR4-3200-nopeutta ja maksimissaan 4 teratavua muistia (64 Gt per ydin). PCI Express 4.0 -linjoja on käytettävissä yhteensä 128.
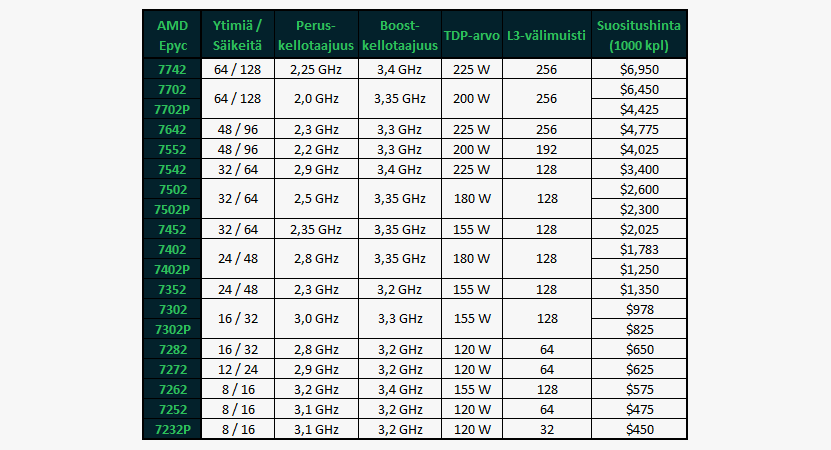
Vaikka uudet Epyc-prosessorit ovat yleisesti taaksepäin yhteensopivia ensimmäisen sukupolven emolevyjen kanssa, löytyy mallistosta kolme prosessoria, joille ei taata täyttä yhteensopivuutta. Epyc 7542, 7642 ja 7742 on varustettu 225 watin TDP-arvoilla, kun ensimmäisen sukupolven emolevyille taataan täysi yhteensopivuus vain 200 watin TDP-arvoon asti. Kokosimme AMD:n uuden malliston alla olevaan taulukkoon. Joissain mallinimissä esiintyvä P-kirjain kertoo prosessorin toimivan vain yhden prosessorikannan järjestelmissä.
AMD kertoi lisäksi päivitystä Zen-arkkitehtuurin lähitulevaisuuteen. Yhtiön mukaan Zen 3 -arkkitehtuurin ja siihen perustuvan Milan-palvelinprosessorin suunnittelutyö on nyt saatu päätökseen. Zen 4 puolestaan on parhaillaan suunnitteluvaiheessa. Vielä aiemmin kesällä Zen 3:n kerrottiin olevan edelleen aikataulussaan, mutta edelleen suunnitteluvaiheessa.
Kukaan ei suunnittelisi tuollaista piiriä, se olisi millä tahansa mittapuulla täysin järjetön ratkaisu vaikka se ehkä teoriassa olisikin mahdollista. Ja edelleen, sillä ei ole merkitystä, koska Romen I/O-siru on täysin eri tavaraa kuin Ryzenin I/O-siru (ja siten X570)
Niitä valmistetaan kylliksi, GF:llä ei ole pulaa 14nm kapasiteetista, 12nm:stä voi ollakin ja se luultavasti selittää miksi X570 ja Romen I/O-piiri on 14nm eikä 12nm, kun volyymit on pienempiä kuin Ryzeneiden niin kannattaa pistää se parempi prosessi eniten myyvälle käyttöön.
Heh, voisi veikata että Intelillä alkaa polttelemaan taas uudet sakot markkina-aseman väärinkäytöstä jos tulee ilmi että myyvät tappiolla. Täysin ylivoimainen verrattuna Intelin vastineisiin, 1P Rome pyyhkii lattiaa Intelin 2P Xeoneilla melkein kaikissa testeissä. Puhumattakaan perf/$. Intelillä ei taida olla kilpailevaa tuotetta tulossa ainakaan vuoteen?
Järjetön? Romen IO-piiri on valtava, AMD:lle tulee iso kasa piiriroskaa jolle jos löydetään jotain järkevää käyttöä on aivan ilmaista.
X570 on järjetön piiri, miksi ei käytetä IO-piiriksi kelpaamattomia Ryzenin jämiä? x570:n volyymi ei voi olla kovin korkea, eikä siitä saadut tulot ole mitenkään rinnastettavissa muihin 14nm piireihin, miksi sitä kuitenkin varta vasten tuotettaisiin vaikka sen voisi saada muiden piirien sivussa – joko 12nm desktop-ryzenin tai 14nm Romen jämistä. Ja jos vielä valittaisiin varta vasten tuotettava piiri niin sitä kuitenkaan ei optimoitaisi mitenkään…..
Aivan järjetön määrä pitkiä väyliä mitkä voi terminoida halutessaan molemmista päistä olisi ainut tapa toteuttaa tuo ideasi. Romen I/O-piiri on valtava mutta se ei ole kyllin valtava ollakseen 4x Ryzenin I/O-die. Lisäksi jokikinen AMD:n dia missä kerrotaan mitään sen asettelusta varmistaa ettei kyse voi olla mistään sen tapaisestakaan. Muistiohjaimet ovat lyhyissä päädyissä, IF-linkit pitkien sivujen päädyissä ja I/O pitkien sivujen keskellä, sitä ei voi jakaa neljään osaan.
Edelleen Romen "jämistä" ei voi saada yhtikäs mitään.
GloFon 12 ja 14nm prosessit ovat sen verran pitkään viilattuja että sieltä tuskin tulee niinkin pienistä siruista mitä Ryzenin I/O-die ja X570 ovat enää paljoa sutta ja sekundaa (ja silloinkin sen piirin pitäisi olla hyvin spesifillä tavalla rikki että se sopisi X570:ksi). 12nm:n kapasiteetti taas voi olla sen verran kortilla ettei se riitä vielä oletettavasti valmistettaviin grafiikkapiireihin, Ryzenin I/O-siruihin, Picasso-APU-piireihin ja vielä päälle X570-piirisarjoillekin.
Asia oli vain spekulaatiota aikaisemmin kun ei tiedetty piirin konfiguraatiota, mutta nythän se tiedetään että IO-piirissä on neljä erillistä NUMA-moodia jotka on linkitetty toisiinsa ja saadaan myös toimimaan itsenäisesti. Väylien määrä ei ole mikään ongelma kun on piipalasta kysymys.
Tuota desktop-Ryzenin signaalivetokuvaa kun katsoo niin näkee että signaalit lähtee korkeintaan neljännes RomeIO:n alalta, loppuosa lienee virransyöttöä jne jota ei voi jakaa kahdeksi.
Toistaiseksi sinulta ei ole tullut mitään muuta kuin spekulaatiota ja spekulaatiota spekulaatioista. Lähteitä kehiin.
Romessa on yksi NUMA-alue per prosessori käytössä kahdella prosessorilla. Mistäs tämän "neljä erillistä NUMA-moodia" keksit? Romen DDR-muistikanavia ei ole naitettu millään tapaa tiettyihin ytimiin vaan samassa prosessorissa kaikilla on sama viive ja pääsy kaikkiin musitikanaviin.
Tää ei ole kuin spekulaatiota. Jos ei kiinnosta niin ei sitä ole pakko lukea faktana. Faktaa ei ole muuta kuin että Epyc2 saadaan myös toimimaan 4:nä NUMA-moodina kuten Epyc1, saadaan noin 25ns paremmat muistilatenssit ja reilut 10% lisää muistikaistaa tarvittaessa jos useammat NUMA-nodet eivät aiheuta ongelmia.
Sitten kun on desktop-Ryzenin pcb:n reititys niin voidaan kysyä että onko AMD:n insseillä vaikeuksia hahmottaa koko käytettävissä oleva alue vai onko jouduttu käyttämään jo valmiina olevia ratkaisuja 😀
Eli kaikki on täysin sinun omaa spekulointia eikä kukaan muu ole tullut samaan johtopäätökseen? Selvä. :vihellys:
Etkö ole edes lukenut noita revikoita läpi?
AMD EPYC 7002 Series Rome Delivers a Knockout – Page 6 of 10 – ServeTheHome
No aina saa esittää vastaspekulaatiota vaikkapa Desktop-Ryzenin piirikonfiguraatiolle ja PCB-reititykselle. Äkkiä se näyttää Romen IO:n neljännekseltä mutta varmasti sille on joku fiksumpikin selite?
Luitko itse? Toki lukaisin nyt tuon (uudestaan) vain pikaisesti ja vielä humalassa mutta tuossa nimenomaan todetaan että kaikki kuuluu nyt yhteen NUMA-nodeen (myös PCIe-laitteet itseasiassa)
No luepa vielä kerran ja vähän ajatustakin mukaan
Intelin osake ehkä noin prosentin laskussa. AMD:n kurssi pomppasi ihan kivasti torstaina. Itse olin ajatellut ostaa AMD:n osakkeita jos kurssi olisi mennyt alle 27 dollarin. Kaikki näytti hyvältä, mutta sitten tuli tuhon Torstai. Oliko tosta Romen julkistuksesta aiemmin mitään infoa vai tuliko se nyt pyytämättä ja yllättäen?
Tuli tulosjulkistus ja porukka pelästyi kun voitot olivat pienemmät kuin vuosi sitten. Kaikki kyllä odottivat (ehkä Inteliä lukuunottamatta) epyc julkistusta kieli pitkällä.
Näissä tämänkaltaisissa kuvissa olisi kieltämättä kiva sanoa, että mikä on se sinun järkeilysi, että mikä tuossa reitityksessä nyt on niin erikoisen vahvasti väitettäsi tukeva… Minkä pakkauksen olisi voinut levittää enemmän ja minkä piirin alalle? IO piirin varmaan? Mutta mikä siellä nyt on niin erityisen silmäänpistävästi ”tyhmästi” reititettyä?
(Jos 3000-sarjan Ryzenin IO-piiri muistuttaa jossain määrin, mutta ei kuitenkaan ole tarkalleen, neljännestä Romen IO:sta, niin sille olisi kyllä myös ihan muita hyviä syitä. Kuten vaikka se, että tuo piirion osien järjestely on hyvin toimiva sillä piipalalla… Tällöin toki sitä Romen IO-piiriä ei voi jälkikäteen leikellä (kuka edes haluaisi tehdä tuota, ne leikkuuviivat ovat kuitenkin ihan merkittävän kokoisia ja se vasta olisikin kallista piin käyttöä).)
Houston we have a problem. Tai sit mulla on väärät kuvat.
katso liitettä 260780
No nyt luin (edelleen toki humalassa) ja en vieläkään näe samaa kuin sinä. Minä näen että siellä mainitaan että tuon voi halutessaan konfiguroida myös kahteen tai neljään NUMA-nodeen, mutta oletuksena on vain yksi NUMA-node.
Servethehome.comin Rome-testissä sanottiin, että Intel antaa noista listahinnoistaan hulluja alennusprosentteja, joten hintavertailu ei ole ihan suoraviivaista.
Onko tuo IO nyt niin iso loppupeleissä :think: Toki se siltä voi vaikuttaa, kun vieressä on "puolet" pienemmällä prosessilla tehtyjä lastuja
Tuplat Zeppelinistä jonka täysin toimivien piirien saannot on ollut jotain 80%. Yli puolet Intelin XCC-piiristä jonka saannot on jotain alle 20% aivan huippuun viilatulla prosessilla. Suurinpiirtein samaa kokoluokkaa suurimman 14nm Vegan kanssa joissa painopiste on luokkaa 50/50 täysin toimivien ja osittain toimivien välillä.
Tuo x570 on vain outolintu. 12nm ja 14nm versiot samasta piiristä eivät kuitenkaan ilmesty tyhjästä, kumpaankin versioon on täytynyt panostaa suuri summa rahaa ennenkuin ovat sarjatuotantokelpoisia. Omaan mieleen ei tule kuin kaksi vaihtoehtoa, 1. käytetään Romen palasta 2. AMD suunnitteli ensin tekevänsä myös Ryzenin IO-dien 14nm prosessilla, kaikki oli jo valmiina ja tuotannossa kun päätettiinkin että upgreidataan ko. piiri vielä 12nm:ään 10% parempien muistikellojen toivossa. Tämä jälkimmäinen vaihtoehto vain on typerä, olisivat suoraan voineet tehdä 12nm versionkin ja säästää kulut ja ajan yhden piirin valmistuksesta.
GloFon 12nm on täysin yhteensopiva 14nm:lle suunniteltujen piirien kanssa kunhan käytetään samoja 9T-kirjastoja eikä uuden prosessin mahdollistamia pienempiä 7.5T-kirjastoja. Näin AMD on toteuttanut muutkin 14>12m shrinkkinsä verrattain "ilmaiseksi".
12nm-prosessi mahdollistaa myös 50 mV pienemmän jännitteen samoilla kelloilla, mikä luultavasti nähtiin tarpeelliseksi tdp:n kannalta
![[IMG]](https://images.anandtech.com/doci/13123/2nd%20Gen%20AMD%20Ryzen%20Desktop%20Processor-page-017_575px.jpg)
No ilmainen on suhteellinen käsite, ne ovat kuitenkin kaksi eri prosessia, ja sarjavalmistukseen kun viilataan piiriä niin ei se hetkessä toteudu, mm. maskisettiin vaikka pääosin samat toimivat pitää tehdä tuon 12nm muutokset ja saada paketti toimimaan sarjatuotannossa, kuukausien ylösajo. Pelkästään x570:ntä varten ei varmaan ole alettu valmistamaan kahta eri piiriä kun olisi aivan hyvin voitu käyttää jo olemassa olevaa 12nm versiotakin ja saada myös muut edut yhden piirin valmistamisesta kahden sijaan.
:facepalm:
Ei todellakaan voida.
Ne "huhut" on vaan sitä, että joku täyisin yhtäähn mistään yhtään mitään tietämätön tyyppi saa täysin toimimattoman "idean" ja postaa sen jonnekin. Ja sitten muut yhtä pihalla olevat tyypit postaa sitä eteenpäin.
Eiköhän tämä vaihtoehto ole jo suljettu pois.
Tuossa ihan AMDn oman slide tuosta NUMAsta zen1 vs zen2.
https://images.anandtech.com/doci/14694/EPYC2NUMAadvantages.png
Ei ole IMO. eikös nuo Ryzen 2200G:t nimenomaan tehdä, tai oli tehty kunnes tuli 3000 sarjalaiset siten, että leikataan Summit ridge halki saaden kaksi täyttä CCX:ää kahdelle 2200G:lle ja täydestä vega-piiristä 8 ydintä(täysi piiri sisältää 64, 64-8=vega 56, sattumaako?) ja liimataan yhteen CCX:n kanssa? Siksi näissä oli liimaa intelin tyyliin, nämä uudethan juotetaan.
Onko jotain lähdettä näille yield-luvuille vai veteletkö hatusta?
Suosittelen sinua myös käyttämään 4-sylinterisessä autossasi moottoria, joka on vain puolikas 8-sylinterstä moottoria, joka on halkaistu kahtia sen valmistuksen jälkeen ja jaettu kahteen eri autoon.
Tämä ehdotuksesi/spekulaatiosi on yhtä järkevällä tasolla.
Ei, vaan se on nimenomaan se järkevä vaihtoehto. Ei siitä "12nm" prosessin vaihtamisesta tule merkittäviä lisäkuluja kun piiri ei tarvi uutta tapeoutia kun kyse on ihan saman prosessin hiukan eri variaatiosta.
Nyt siis väite oli että X570 on kirjaimellisesti sahattu irti tuotantolinjalta tulleesta Romen IO-piiristä.
Ei.
Vaan raven ridge on ihan eri piiri.
Kuten se on jo meneen kertaan sanottu niin se Rome todellakin voidaan conffata käyttämään 4 numa nodea josta on tietyissä kuormissa hyötyä.
AMD EPYC 7002 Series Rome Delivers a Knockout – Page 6 of 10 – ServeTheHome
Defaulttina ajetaan NPS=1 asetuksella eli ei ole numa nodeja käytössä kuten postaamassasi diassa.
"näyttää".
Selitys lienee se, että kaikki piilastut näyttävät samalta: Mustilta suorakaiteilta.
Joka on eri asia kuin se, että se on neljä erillistä osaa linkitettynä toisiinsa.
Huoh…
Mikä näyttää numalta, mikä haisee numalta, mikä toimii kuin numa on numa.
Mitä et nyt ymmärrä? Defaulttina yksi numa, voidaan konffata neljäksi. Tarkoittaako se, että piiri voidaan sahata neljään osaan niin että kaikki toimivat yksittäin? Ei.
En ole piirin sahailemiseen ottanut mitään kantaa, ainoastaan virheelliseen väittämään että Romessa ei olisi numa nodeja.
Tuosta Romen NUMAsta:
Romen IO-piiriin tulee suuren kaistanleveyden kytkentöjä käytännössä:
* 8 linkkiä CPU-chipleteille
* 8 linkkiä muistiohjaimille
* IO-puoli (tälle ei välttämättä riitä yksi portti, koska PCIE-linjoja on sen verran paljon)
* Linkit toiselle soketille (4kpl?)
Samaan crossbariin ei käytännössä järkevästi voida laittaa >20 porttia, joten tuollaisella kytkentämäärällä on pakko käyttää jotain mutta kytkentätopologiaa. Intel käyttää sekä meshiä että rengasväylää prosessorimallista riippuen, AMD tykkää käyttää hierarkisia crossbareja.
Kaikissa crossbaria monimutkaisemmissa kytkentätopologioissa liikenne on erinopeuksista riippuen siitä, mistä ja mihin mennään.
Eli ilmeisesti tuo yksi IO-piiri todellakin koostuu neljästä "clusterista" joka koostuu kahdesta muistiohjaimesta ja kytkennöistä kahdelle CPU-chipletille; Jokaisessa clusterissa on sisällä yksi crossbar, joka kytkee ne pari muistiohjainta niihin CCXlle meneviin linkkeihin, muualle piirille meneviin linkkeihin sekä ilmeisesti myös yhteen toiselle soketille menevään linkkiin(tämä kytkentä ei välttämättä lähde täältä).
Sitten piirissä on korkean tason crossbar joka kytkee yhteen nuo 4 clusteria ja IO-puolen.
Voi olla, että myös IO-puoli on hajautettu noille neljälle clusterille.
Eli siinä mielessä tuossa tosiaankin olisi hyvin lievä "NUMA" tuon yhden soketin sisällä, mutta kaistanleveys ja viive näiden clusterien välillä on kuitenkin niin hyvä että sen merkitys jää käytännössä hyvin pieneksi, ja ylivoimaisesti suurimmassa osassa tilanteita piiri kannattaa konfiguroida siten että muistiosoitteet interleavataan kanaville sellaisella granulariteetilla että tätä soketin sisäistä NUMAa ei käyttis voi tukea(NPS=1)
Mikään piiri mitä ei ole suunniteltu toimimaan useampana osana ei voida hajottaa toimiviksi osikis. Kyse on siitä että jos halutaan niin suunnittelussa voidaan ottaa huomioon piirin toimiminen itsenäisinä osina aivan hyvin.
Ei noissa mitoissa mitään estettä ole, yhden piirin leikkaaminen neljäksi olisi tietysti optimaalista mutta viallisen piirin leikkaaminen kahdeksi pienemmäksi toimivaksi piiriksikin antaisi mahdollisuuden käyttää turhia piirejä johonkin. IO-linjat desktop-Ryzenin IO-diestä näyttäisi lähtevän leveyden puolesta noin puolikkaan Romen IO-dien alueelta.
Aivan täysin järjetön idea. Ja kyllä noille Romen I/O-siruille tulee käyttöä vaikka olisi osittain rikkikin, sieltä tulee uudet Threadripperit mihin niitä lykätään.
Kautta aikain on monisylinterisistä hajonneista moottoreista sahailtu käyttöön vähempisylinterisiä 😀 V8:sta saa kätevästi nelosen, ja nelosesta kaks pyttysen. Toki moottorit on usein tehty niin että sahaamalla niistä ei kahta täysin toimivaa konetta saa aikaiseksi mutta periaate on ihan sama kuin piirien valmistuksessakin, tehdään romusta vielä jotain käyttökelpoista vaikka ihan alkuperäisen veroista tuotetta ei saadakaan aikaiseks.
Kaikki piille valmistettavat piirit leikataan, ei se teknisesti mitenkään kummallista ole. Tuskin AMD on mitään legoja kuitenkaan lähtenyt suunnittelemaan. Ei se nyt kuitenkaan mahdoton ajatus ole etteikö Romen IO ohjaimet, jotka eivät toimi täysin, olisi suunniteltu siten, että siitä saadaan jollakin reunaehdolla uusiokäytettäviä osia. Kyseessä on kuitenkin niin valtavan kokoinen piipala että kuulostaa oudolta ettei jotain varasuunnitelmaa osittain toimiville piireille ole.
Ja osaa näistä softista ei mielellään ajeta VMWare tjsp virtuaalikoneessa, vaan suoraan host OS:ssä, jolloin se corejen vähentäminen ei onnistu triviaalisti sieltä virtuaalikoneen konffista.
Toisaalta esim VMWaren lisenssi taas menee per socket. Tuplasti tehoa per socket = puolet halvempi lisenssi.
Ainoa mihin intelillä on vielä saumaa on ne per core lisenssit ja harvinaiset avx512 softat.
Intelillä on myös etuna ylivoimaisesti parempi saatavuus ja monipuolisempi oem-tuki (enemmän erilaisia ja eri kokoisia serverimalleja eri käyttötarkoituksiin) ja softatuki.
Monet enterprise-softat on softavendorien toimesta testattu ja tuettu vain muutamilla tietyillä rautakokoonpainoilla (tietty serverimalli, tietty raid-ohjain, tietyt verkkokortit ja tietty kernel-versio jne.). Kestää aikaa, ennenkuin softavalmistajat ehtivät varmistaa softiensa toiminnan ja benchmarkata sen, että mitä uuden ryzen tapauksessa voi luvata.
Esim. kun meille tilataan uusi klusteri yhden tietyn softan käyttöön, niin yleensä business-puolen spekseistä arkkitehti laskee, että tarvitaan yhteensä 300Gbps verkkoliikennettä ulospäin ja http-requestehin vastausaika ei saa nousta kovimman suunnitellun loadin aikana yli 200ms lukemaan ja mitälienee. Softavendor osaa kertoa, että blueprint-hardiksella (xeon gold 61xx + 512GB muistia + nuo levyohjaimet ja mellanoxit) saa varmasti 36Gbps per pannu ja tuo 200ms täyttyy sillä kuormalla. Jos päädymme ostamaan mitään muuta, niin he eivät takaa mitään, koska eivät ole testanneet ja varmistaneet.
Silloin vaihtoehdoksi jää ostaa joku hatusta revitty määrä epyc-pannuja ja toivoa, että se ne mellanoxin ajurit toimivat hyvin ja juuri sen softan db-scheema sattuu toimimaan tarpeeksi nopeasti huonosti databaseja pyörittävällä epycillä, tai tietää ennalta tasan tarkkaan, että 12x noita pannuja ja sillä saletti. Tai käyttää viikkoja tai kuukausia benchmarkkaamiseen, jotta tietää mitä niistä tuntemattomista laitteista saa ulos.
Mitä pidempään odotellaan, niin sitä useampi softa on testattu valmistajan toimesta myös epycillä ja tilanne paranee.
No Epyc siirtyi nyt PCI-e 4.0 aikaan joten siihen varmaan kannattaa tuota tukevaa mellanoxia tunkea kiinni ja 4.0 ei hirveästi ole liikkeellä, joten on hyvin suuri todennäköisyys että ne 4.0 tukevat mellanoksit on testattu toimiviksi Epycin kanssa.
Joo, mutta softaa ei ole testattu sillä mellanoxin kortilla, vaan vain parilla mallilla.
AMD:n kannalta oleellista on kuitenkin olla hyvä yleisimmissä asioissa ja siihen uusi epyc on hyvä. (Paitsi tietokannat näyttävät olevan paskaa).
Juu kaikkinensa eri softien lisenssointi härvelit on ihan älytön suo, joista fiksujen päätösten tekeminen vaatii saatanallista perehtymistä asioihin (mitä omallakin työpaikalla kaivattaisiin).
Lähinnä siis alunperin halusin tuoda esille että kyllä 8C serveri CPU:lle on kysyntää laajalti jo ihan lisenssoinnin vuoksi. Toiseensuuntaan (eli enempi coreja per lastu) kysyntä liene on aika itsestään selvää jopa ilman tuot vmware lisenssointi kuviota.
—
Mitä tuohon hyptettyyn AVX-512 tukeen tai sen puutteeseen tulee, niin se on aika marginaalia ns peruspalveluissa. Meillä on 1000+ serveriä eikä yhtäkään palvelua joka hyödyntäsi sitä, tai vanhempaa AVX tai edes SSEx. Parissa palvelussa on ny kepoista AI sotkua, joka noista liene hyötyisi ainakin koulutusvaiheessa. Tosin jos lähdetään sen kannalta devaamaan niin ensin pitäisi tehdä pilotti GPU vs Inteli AVX-512, päättää ja sitten implementoida.
On suorastaan erikoista että esim ESX:llä on ihan samoja rajoitteita. Tuote on kuitenkin ollut markkinoilla jo vaikka kuinka pitkään. On tämäkin tietysti tapa tehdä vendor lock. ICC on kans persiö integroida kun vaatii erillisen lisenssipalvelimen CI ympäristöön. Olen myös sitä mieltä että on terveellistä että nyt on alusta johon voi kasata avointa ohjelmistopinoa ilman että joutuu antamaan suorituskyvyssä kohtuuttomasti tasoitusta. Olisi hienoa nähdä oikeita lukuja siitä miten TCO oikeasti toteutuu eri alustoilla.