
Spectre ja Meltdown ovat olleet viimepäivien kuumin puheenaihe IT-maailmassa. Suurimman osan huomiosta on saanut Intel, vaikka haavoittuvuudet koskevat myös muita valmistajia.
Spectre- ja Meltdown-haavoittuvuuksien paikkaamisen tiedetään vaikuttavan tietokoneiden suorituskykyyn. Se, miten paljon paikat suorituskykyä laskevat, riippuu ennen kaikkea tietokoneella tehtävistä tehtävistä. Suurimman suorituskyvyn laskut tapahtuvatkin lähinnä datakeskuksissa, joissa palvelimiin kohdistuu raskasta I/O-rasitusta.
Intel on julkaissut omat suorituskykytestinsä koskien kotikäyttäjien tietokoneita Windows-alustoilla. Testit on ajettu yhtiön kolmen viimeisen sukupolven prosessoreilla käyttäen erilaisia synteettisiä testejä. 8. sukupolven Coffee Lake -prosessoreilla ja 8. ja 7. sukupolven Kaby Lake -mobiiliprosessoreilla testit on suoritettu Windows 10 -käyttöjärjestelmällä ja 6. sukupolven Skylake-prosessoreilla sekä Windows 10:llä käyttäen SSD-asemaa että Windows 7:llä käyttäen SSD-asemaa ja kiintolevyä. Testit ajettu SYSmark 2014 SE-, PCMark 10- 3DMark Sky Diver- ja WebXPRT 2015 -ohjelmilla.
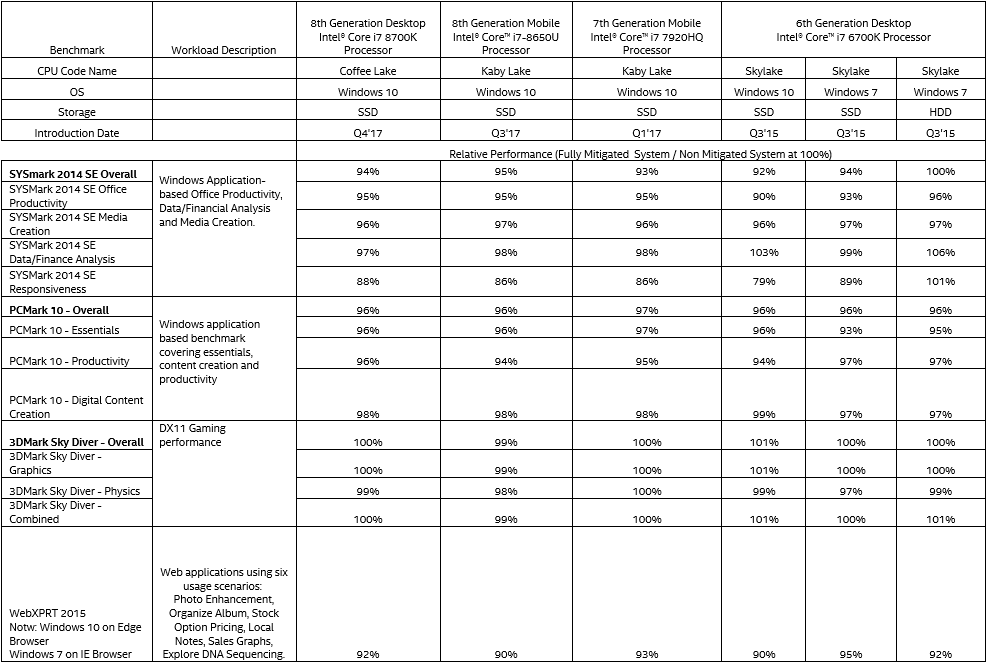
Intelin omien testien mukaan suorituskyky on laskenut lähes jokaisessa testissä, mutta muutama poikkeuskin löytyy. Suorituskyvyn kerrotaan jopa parantuneen kiintolevyllä ja Windows 7:llä varustetulla Skylake-kokoonpanolla SYSMark 2014 SE:n Data/Finance Analysis- ja Responsiveness-testeissä sekä samalla prosessorilla, SSD-asemalla ja Windows 10 -käyttöjärjestemällä SYSMark 2014 SE:n Data/Finance Analysis -testissä, 3DMark Sky Diverin kokonaistuloksessa, grafikka-testissä ja grafiikka- ja fysiikkatestit yhdistävässä Combined-testissä.
Suurin negatiivinen vaikutus päivityksistä on saatu SYSMark 2014 SE:n Responsiveness-testissä Skylake-prosessorilla Windows 10 -alustalla ja Kaby Lake -mobiiliprosessoreilla. Skylaken tapauksessa suorituskyky oli vaivaiset 79 % alkuperäisestä, kun Kaby Lakejen suorituskyky riitti niin ikään erittäin heikkoon 86 %:iin alkuperäisestä. Myös Coffee Lake -kokoonpanoin ja Windows 7:lla ja SSD-asemalla varustetun Skylake-kokoonpanon tulokset laskivat alle 90 %:iin päivittämättömien verrokkien tuloksista samassa testissä.
Löydät kaikki suorituskykylukemat uutisen kuvasta, jonka voi avata täyteen kokoon klikkaamalla.
Lähde: Intel
No se on ollut paljon yksinkertaisempi kuin mistä nyt yrität vääntää juttua. Täähän ei ole edes mikään monimutkainen asia.
Eli jos sulla on x bittiä osoiteavaruutta niin kaikki muistiosoitteet on mapattava tähän muistiavaruuteen. Jos emme tarkasta kuin 12 alimpaa bittiä meillä on 4 kilotavua muistiavaruutta jolla cache voi operoida, pyöritteli sen miten päin tahansa.
Nyt jos meillä on täysi TLB käytössä pystytään mappaamaan kaikki muistiosoitteet koko muistiavaruudesta tähän cacheen(fully assosiactive, way-set assosiactive jakaa cachen sitten osiin). Jokainen TLB muunnos pitää kuitenkin suorittaa ennen muistiin viittaamista joten L1-tlb haussa voidaan hyvin tinkiä kuinka monta bittiä TLB:stä tarkistetaan, se yhdeksän bittiä oli vain esimerkki, eli jos TLB:stä tarkistetaan yhdeksän vähiten merkitsevää bittiä L1 TLB-haussa se muodostaa yhdessä 12 bittisen offsetin kanssa 21 bittisen alueen prosessin lineaarisessa osoiteavaruudessa. Toki koko tuo osoitteiston käännökset eivät ole yhtä aikaa TLB:n muistissa vaan ainoastaan TLB-entryjen mukainen määrä, eli jos esimerkiksi on se 128 4KB:n sivua TLB:ssä tuo kahden megan alue pitää sisällään 128 erillistä 4KB:n aluetta joiden kohdalla osoitemuunnos löytyy TLB:stä(ja vastaavasti 32 KB:n välimuisti pitää sisällään 64 erillistä 512 bitin aluetta) . Ja toki koko TLB-osuma pitää tarkistaa jossain vaiheessa(ennen storea) mutta tässä esimerkissä meillä on 2megan alue jolla ohjelma voi operoida ilman että TLB-muunnoksessa tulee vääriä muunnoksia noiden 9 virtuaalimuistibitin avulla.
Niin kuka on pihalla. Kaikki ohjelmistotko on erotettu erillisiin muistiavaruuksiin? Tuossahan oli esimerkkikin, webbiselaimen javascript joka pyörittää ulkopuolista koodia isäntäohjelman prosessissa, tälläisissä tapauksissa ulkopuolinen koodi voi täysin vapaasti lukea isäntäohjelman kaiken datan – ja tiedemme myös sen että selaimissa "korjaus" on toistaiseksi ajastimien tarkkuuden lasku tasolle jolla cachelinjojen nopeuden vakoilu on ainakin vaikeaa.
Mites esimerkiksi kaikki kääntäjien läpi ajettava koodi? JIT-kääntäjän pitäisi pyöriä eri muistiavaruudessa kuin ajettava koodi – mahtaakohan hidastaa 😀
Juu ei toimi. Virtuaalimuistin oikeusbitit eivät ole ongelma vaan se että Intelillä data prefetch tuo cachelinjoihin muutoksia myös pieleen spekuloiduissa muistihaussa, meltdown-vuodossa luetaan vain loopissa haluttua osoitetta ja data tulee läpi josta sillä tehty toinen operaatio aiheuttaa cacheen muutoksen jolla voidaan tulkita datan sisältö. Tämä on se ongelma mihin Intelin epätoivoiset mikrokoodipäivitykset yrittävät tuoda korjausta, mutta se vaatii myös ohjelmien uudelleenkäännön yms. skeidaa jotta homma saadan pelaamaan -> ainakin serverimaailmaan tuollaiset prossut on kyllä "rikki".
Spectressä sentään pitää huijata branch-predictor osoittamaan haluttua dataa, vähän sentään vaikeampi hyödyntää kuin suoraan pyytämällä haluamaansa dataa.
No väärällä mutta onhan tuossa kirjoituksessakin lähtötiedot väärin, 64 tavun cachelinjat on tietysti 9 bitin osoituksella eikä 8:n.
:facepalm:
Missään ei ole välimuisteja, jotka olisivat yksinkertaisempia kuin read-only-suorasijoittava välimuisti, jonka toiminnan selitin edellisessä viestissäni.
:facepalm:
Et siis ilmeisesti edelleenkään ymmärrä ihan perusteita siitä, mitä koko virtuaalimuistisivun käsite tarkoittaa, eli siis mikä on koko sivutukseen perustuvan virtuaalimuistin toimintaperiaate
Yritän nyt vielä vääntää senkin rautalangasta. (lisäselvennys vielä notaatiostani: 0x luvun alussa tarkoittaa tässä heksalukua, yleisimpien ohjelmointikielten notaatio, ohjelmointia kokemattomalle voi olla uusi juttu)
Sivuttavan virtuaalimuistin mappayksessa virtuaalisen ja fyysisen muistin välillä mäppäys tehdään sivu kerrallaan. Virtuaalisen musitin sivuja mäpätään osoittamaan vapaasti mihin tahansa fyyisen musitin sivuihin. Eli homma toimii siis täysin sivun koon granulariteetilla.
Muistiosoite koostuu kahdesta osasta: Sivun osoite (ylimnmät bitit) ja offset sivun sisällä (alimmat biit).
Jos muistiosoite on vaikka 0x00000034, sen sivun osoite on 0x00000000(josta voidaan impliittisesti jättää alimmat bitti pois, koska ne on aina nollia, eli 0x00000 ja offset sivun sisällä 0x34.
Jos muistiosoite on vaikka 0x00001034, sen sivun osoite on 0x000001000 (josta voidaan implisiittisesti jättää alimmat bitit pois, eli 0x00001, ja offset sivun sisällä 0x34.
jos muistiosoite on vaikka 0x12345678, sen sivun osoite on 0x12345000 (josta voidaan implisiittisesti jättää alimmat biti pois, eli 0x12345), ja offset sivun sisällä 0x678.
Virtuaalimuistia ei voida olla mäpätty osoittamaan siten että se alkaa jostain fyysisen muistisivun puolivälistä ja jatkuu seuraavan fyysisen muistisivun puoliväliin. Vaan se on mäpätty koko siihen sivuun.
Tämä tarkoittaa sitä, että se virtuaaliosoitteen muunnos fyysiseksi osoitteeksi ei koska niihin offsetteihin. Se, että joku osoite on sivun 576. osoite en aina sivun 576. osoite, riippumatta siihen, mistä sivusta on kyse.
Tämän takia mitään osoitteenmuynnosta ei tarvi tehdä niille alimmille 12 bitille. Ne on AINA VALMIIKSI OIKEAT KOSKA NE ON AINA SAMAT SEKÄ FYYSISELLE ETTÄ VIRTUAALISELLE OSOITTEELLE
Ensinnäkin,se, millainen assosiatiivisuus itse välimuistilla on ja millainen assosiatiivisuus TLBllä on on täysin erillisiä asioita.
Toisekseen, lähdet siitä virheellisestä lähtöoletuksesta, että täysin assosiatiivinen välimuosti olisi jotenkin normaalitilanne, josta "lähdetään liikkelle ja johon muita verrataan".
Tämä on väärä lähtöoletus, ja ne on hyvin harvinaisia, koska niiden osuman tarkastaminen yhtään suuremmasta välimuistista on äärimmäisen kallis operaatio(koska pitää verrata tagibittejä välimuistin joka ikisestä linjasta). Suorasijoittava on se yksinketainen perustapaus, ja muut on sitä että siitä lähdetään parantamaan.
Mitähän nyt oikein tarkoit sanalla "viitata" tässä….
… ei voida, koska pitää tarkistaa, että siinä välimuistissa sen indeksin kohdalla on juuri sen osoitteen data, jota halutan hakea. Eikä jonkun uun sellaisen osoitteen data, jonka alimmat biti sanoo että se menee siihen samaan paikkan välimusitissa, jos se on välimusitissa.
Haukut Inteliä siitä että intel ei ole suojannut prosessoreita hyvin hankalilta sivukanavhyökkäyksiltä ja itse olet valmis tekemään L1-datakakun, joka suostuu antamaan aivan väärän osoitteen dataa etkä näe tässä mitään ongelmaa
:facepalm:
:facepalm:
Tämä alkaa mennä jo kategoriaan "not-even-wrong".
Nykyaikaisissa prosessoreissa on 48-bittiset virtuaalisoitteet(*). Koska tahansa voi tulla osoituksia mihin tahansa näistä virtuaaliosoitteista. Ja mikä tahansa niistä virtuaaliosoitteista voi osoittaa mihin tahansa fyysesssä musitissa (paitsi että alimmat 12 bittiä on aina fyysisessä ja virtuaalisooitteessa samat). Kaikessa kirjanpidossa ja osoitteistuksessa pitää koko ajan ottaa tämä huomioon.
Ja sillä, mitkä entryt sieltä L1-DTLBstä löytyy, ja mitkä se joutuu hakemaan kauempaa, ei ole mitään tekemistä sen kanssa, mitä kirjanpitoa L1D-välimuisti tarvii. VIPT-välimuisti aloittaa accessinsa täysin TLBstä riippumatta(koska tarvii siihen accessiin aloittamiseen vain nitä alimpia 12 bitiä). Ja osuman tarkistamiseen tarvii sen koko fyysisen osoitteen, koska sen pitää pystyä erottamaan mikä tahansa fyysinen osoite toisistaan.
Se, että voidaan tehdä jonnekin 21 bitin alueelle muistisoituksia ilman että sen sisällä sekoaa mitään ei lohduta yhtään mitään, koska aina voi tulla accesseja sen 21 bitin alueen ulkopuolelle. Jos yritetään lukea osoitteesta 0x12345678 mutta saadaankin osoiteen 0x22345678 niin sitten prosessori toimii väärin.
Niinkuin oikeasti. Opettele ohjelmoimaan. Ensin jollain korkean tason kielellä, sen jälkeen assemblyllä. Sen jälkeen voisit ehkä alkaa joskus ymmärtääkin jotain.
(*) 64-bittisen pointterin ylimmät 16 bittiä on käyttämättä, voidaan myöhemmin ottaa käyttöön muuttamatta userspace-softia, vaatien muutosta vain kerneliin.
:facepalm:
Miten saat 64 tavun välimuistilinjoista 9 osoitebittiä?
Ei sen vapavalintaisen tavun osoiittamiseen sieltä tarvita kuin 6 bittiä.
Vai olet vuosia vängännyt vaikka mistä tietämättä edes niin yksinkertaista perusasiaa, että muistiositteet osoittaa tavuihin eikä bitteihin?
Ai näin korkealle tasolle pitää nousta? 2^9=512 bittia = 64tavua.
Puhuin siis TLB-optimoinnista, L1-cachen kanssa joko dekoodataan joka muistiviittauksessa koko virtuaalimuistiosuus TLB:stä tai luotetaan siihen että koodin tällähetkellä pyörivä osa mahtuu pienempäänkin muistijälkeen. Tästä oli polemiikkiä aikanaan software vs hardware TLB toteutuksissa kun tosiaan TLB:n osittainen dekoodaus avaa mahdollisuuksia side-channel vakoilulle mutta ongelma ei ole kovin suuri, hallittavissa ohjelmiston ja käyttöjärjestelmän suunnittelulla. Intelillä kuitenkin taisi mennä aika kauan vakuuttaa serverpuoli ratkaisun turvallisuudesta, ja sitten se kusee näin.
Käyttöoikeuden tarkastus olisi yksi bitti – tämänkin Intel on optimoinut pois, kertoneeko jotain siitä kuinka kriittinen TLB:n optimointi on.
Ja siis tämä on vain TLB:n nopeusoptimointi, kun on dekoodattu x määrä bittejä että TLB:n osumaprosentti on käyttötarkoitukseen riittävä voidaan mahdollisesti löydettyä osoitetta lähteä etsimään cachesta. TLB:n dekoodaus jatketaan loppuun sitten yhdessä cachen haun kanssa ja jos muistiviittaus tuli aluksi dekoodatun alueen ulkopuolelta tuli TLB miss ja perutaan tehdyt haut.
Jotenkin tämä keskustelu muistuttaa minua jostain aikaisemmasta väännöstä tämän aiheen ympärillä… siis, että keskustelussa on kaksi osapuolta, joista vain toinen tietää oikeasti mistä puhuu. Hieman rasittavaa edes sivusilmällä seurata tällaista…
Esimerkissäsi on tietoalkion koko. Jos on 2 kpl tuon kokoista(tai minkä kokoista tahansa) tietoalkiota, niihin viittaamisiin riittää yksi bitti. Se kuinka moneen alkioon pitää viitata määrittää indeksointiin tarvittavien bittien lukumäärän.
Edittiä eli korjausta.
:facepalm:
Niin, ja n. missään viimeisen n. 50 vuoden aikana valmistetussa tietokoneissa muistia ei osoiteta bitti kerrallaan vain tavu kerrallaan.
Tämä jos mikä on ihan tietotekniikan alkeisasiaa.
(muutamassa hyvin harvinaisessa signaaliprosessorissa muistia osoitetaan esim. 16-bittinen sana kerrallaan, mutta tällaisetkin arkkitehtuurit ovat erittäin harvinaisia)
:facepalm:
Perun sanani suosituksistani alkaa opettelemaan ohjelmointia.
On ehkä maailman kannalta parempi, että missään ei tulla koskaan ajamaan sinun kirjoittamaasi ohjelmakoodia.
Sinun mielestäsi prosessorin pitäisi vain luottaa siihen, että koodi nyt sattuu kerralla käyttämään vain n. miljardisosaansa koko muistiavaruudestaan.
:facepalm:
Kerrotko mielipiteesi siihen, mihin 48-bittisiä virtuaaliosoitteita mielestäsi tarvitaan, jos ohjelmat mielestäsi käyttävät vain n. 21 bittiä muistia kerrallaan?, eikä prosessorin tarvitse toimia oikein, jos ohjelma käyttää yli 21-bitin verran muistia?
Ei, kyse oli aivan eri asiasta. Sinä et vaan ymmärtänyt, mistä niissä puhuttiin.
Suurin asia, mikä tässä kusee on sinun ymmärryksesi ihan yksinkertaisista asioista liittyen ihan perusasioihin muistiin liittyen.
x86-64-tilassa tai PAE-päällä käyttöoikeuksille on kolme bittiä, vanhassa 386-moodissa 2 bittiä.
Siellä on erikseen lukuoikeus-bitti, kirjoitusoikeus-bitti ja execute-oikeus-bitti (joka puuttuu 386-tilasta, siinä se on yhdistetty lukuoikeusbittiin).
Väärin. Se bitti luetaan sieltä ja käskyyn merkataan pystyyn flagi, että tämä luku on osoitteeseen, josta ei saa lukea. Se käsitellään kerralla siinä vaiheessa kun sen siitä lentävän poikkeuksen saa heittää aiheuttamatta väärään aikaan lentävää poikkeusta.
AMD joutuu käsittelemään tämän kahdessa osassa, ensin vain keskeyttää sen loadin ja myöhemmin heittää poikkeuksen.
Ei sieltä TLBstä tarvita yhtään bittiä että se cacheaccess voidaan aloittaa, koska siihen accessin aloittamiseen tarvitaan vain niitä muistiosoitteen alimpia 12 bittiä, joita ei TLBstä tarvitse katsoa, koska ne eivät muutu osoitteenmuunnoksessa virtuaaliosoitteesta fyysiseksi.
Ja siinä vaiheessa kun tarkastetaan, tuliko osuma, ei voida luottaa yhtään mitään siihen mille alueelle accessi osuu, vaan pitää tarkastaa osoiteteen kaikki bitit, koska se voi tulla mihin tahansa osoitteeseen koko fyysisen muistin alueella.
Sekoitat nyt TLBn ja datakakun toimintaa todella pahasti keskenään.
TLBn nopeusoptimoinneilla ei ole mitään tekemistä sen kanssa, miten L1D-välimuisti toimii.
Olet lukenut joskus jostain jonka olet ymmärtänyt väärin. Höpinästäsi ei kuitenkaan saa selvää, mitä olet oikeasti joskus jostain lukenut.
Oliskohan oma topikki paikallaan tälle vääntämiselle? Jos tosiaan haluatte jatkaa vielä..
Äläs nyt. Tämä on jo erään toisen foorumin ajoilta hyvin tuttua vänkäämistä näille kahdelle käyttäjälle. Napataan me muut popcornit esiin, otetaan hyvä asento ja luetaan mielenkiintoista teknistä väittelyä – vaikka itse olen jutuista pihalla kuin lumiukko. 🙂
Jos se koostuu monesta erillisestä prosessista, niin kyllä, tämä on juuri prosessin määritelmä.
Se, mikä on säikeen ja prosessin ero.
Saman prosessin eri säikeet näkee saman muistin, eri prosessit näkee eri muistin.
Eri prosessitkin kuitenkin pystyvät mappaamaan joitain yksittäisiä muistialueita niille yhteiseen jaettuun muistiin/allokoimaan muistia, joka on yhteistä toisen prosessin kanssa. Tämän kautta ei kuitenkaan näe toisen prosessin muuta muistia.
Silloin, kun ne pyörii samassa prosessissa, niitä ei suojata millään virtuaalimuistin lukuoikeusbiteillä, vaan sillä että sen tulkaten suoritettavan javascriptin tai javasciriptistä jitatun koodin muistiaccessit tarkastetaan ihan softalla, jokaisen taulukkoaccessin (jonka indeksejä ei pystytä kännösaikana tarkistamaan) eteen siihen JITattuun koodiin lisätään haarautuminen joka varmistaa että se ei accessoi muistia jota sen ei pitäisi accessoida.. (paitsi spekulatiivisesti 😉
Tässä on kyse spectrestä, ei meltdownista, ja kaikki spekulatiivista suoritusta tekevät prosessorit ovat tälle aivan yhtä haavoittuvaisia.
Yleisesti ottaen: Muistinsuojauksessa ei suurimmasssa osassa tapauksista ole kyse siitä, että muistisivulle olisi laitettu lukukieltonitti päälle, vaan siitä, niitä sivuja, joita softan ei pidä pystyä lukemaan ei ole edes koskaan mäpätty sen muistiin.
Ihan turhaa tuhlata muistiakin sivutauluihin, joiden kautta ei koskaan voida accessoida mitään.
Vain siinä tilanteessa, että jotain dataa pitää jakaa joidenkin välillä, nuo kieltobitit nousee yleisessä tilanteessa merkitykselliseen asemaan.
Suorituskykysyistä (jotta kernel-kutsut olisivat nopeampia) tätä periaatetta oli kuitenkin aiemmin rikottu siinä, että kernelin oma data on userspace-ohjelmille näkyvissä (mutta laitettu käyttökieltoiseksi kaikilla kolmella tavalla).
Nyt tämä osoittautui vaaralliseksi optimoinniksi intelin prosessoreilla. (meltdown).
Kerrankos sitä pyörittelee lähtöarvot pieleen, sen takia on hyvä että tekijät on selvillä niin muut huomaa helposti missä meni mehtään.
Saatat olla täysin oikeassa. Pitäis panostaa itse asiaan ja jättää ylimääräiset höpinät pois.
Eli cachen toiminnastahan olet täysin oikeassa, itsellä oli vain vähän ongelmia sisäistää kun ei peruslaskuista lähtien onnistunut.
Mutta yritetään siis uudestaan kun lähtöarvot on saanut päähän oikein.
Eli 8 way set cachessa tarvitsee vertailla 8 kpl 12 bitin offsettiä yhdessä TLB:n dekoodauksen kanssa -> TLB:stä taas tarvitsee verrata 4kpl 36:ta sivunumerobittiä(jos siis 4-way TLB). Käsittääkseni kaikki nämä eri vertailut voi laittaa yhtäaikaa liikkeelle. 36 bitin comparaattori on vain huomattavasti hitaampi kuin 12 bitin -> meillä on mahdollisesti kellotaajuutta rajoittava hidas polku.
-> jos dekoodaamme tässä vaiheessa vain samat 12 bittiä sivunumerobiteistä saamme varmaankin tulokset valmiiksi likipitäen samassa ajassa – ja meillä on 24bittiä(16MB jos nyt laskut menee oikein) lineaarista muistiavaruutta dekoodattuna. Eli siis ajettavan koodinpätkän osat jos ovat tuolla alueella löydetyt TLB-hitit ovat oikeita. Ja kun otetaan huomioon että TLB range sivuista laskettuna on 128*4KiB=512KiB(1/32 osa alueesta) ja itse cachea on 32KiB noita väärin tulkittuja osittain dekoodattuja TLB-tuloksia on hyvin pieni prosentti verrattuna normaaleihin TLB-misseihin. Ja tässä siis kyse L1 DTLB:stä, hudin vaikutus ei ole suuren suuri kun L2 TLB:kin löytyy. Mun muistikuvat asiasta on kuitenkin ajalta jolloin missään prosessorissa ei ollut useampitasoista TLB:tä.
Ja nykyprosessorilla kyse ei optimoinneissa taida enää olla niinkään nopeudesta kuin tehonkulutuksen optimoinnista, eihän esimerkiksi se pois tässä vaiheessa jätetty yhden bitin käyttöoikeustarkistus voi nopeutta rajoittaa mutta tehonkulutukseen voi olla pieni vaikutus.
Nykyäänhän on käytössä Kernel-mode JIT kääntäjiäkin, sellaisen läpi ajettuna Spectrekin pääsee käsiksi kernelimuistiin.
Mutta kaikki prosessorit eivät ole yhtä haavoittuvaisia, Spectre pääsee lukemaan kernelimuistia Intelin prosessoreilla myös userspacessa ajetusta ohjelmasta, ei muilla.
@hkultala & @Sami Riitaoja
Voitaisiinko pojat sopia, että tätä vääntämistä jatketaan vaikka YV:n puolella. Menee nyt vähän turhan pitkäksi vääntämiseksi täällä.
Mitä helvettiä? Ymmärrän juuri ja juuri eri ketjun, mutta muuten kyllä en vähääkään.
Tod näk tässä on oppinut enemmän cpu:n toiminnasta kuin missään aiemmin.
Tämä on mennyt kahden henkilön vääntämiseksi, eikä ainakaan minusta palvele tämän otsikon alla. YV, uusi ketju, mikä se ratkaisu sitten onkaan.
No hoida sitten hommasi ja siirrä keskustelu sopivaan ketjuun.
Keskustelu on sillä tasolla että ihmisiä ei ole kovin montaa, jotka tunee cput noin hyvin. Mutta ei se voi olla syy rajoittaa keskustelua.
Eikä se myöskään tarkoita sitä että muita ei kiinnostaisi ja keskustelu pitäisi käydä yv:llä.
Mielenkiinnolla olen seurannut myös tätä keskustelua ja mielellään näkisin sen jatkuvan.
N-way set cachet on multa aina mennyt ohi älyn kun asiaa on kuvattu n-määrällä laatikoita joissa cachelinjat. Kultala selitti hyvin että homma lähtee direct-mapped cachesta jonka avulla löysin yhden fiksun sivun joka kuvas asian juuri noin, n tuossa määrittää montako cachelinjaa aina muodostaa setin ja setti on sisäisesti fully assosiactive. Nyt em. asiakin mahtui älyyn, toivottavasti on vielä oikeinkin.
Eikai sitä kukaan viitsi YV:nä vääntää mitään 😉
@Ville Suvanto henkilöiden keskustelu on ollut ihan asiallista ja asiassa pysyvää, joskin ei otsikon. Tuollaisen nillittämisen sijaan olisit voinut tehdä sen ketjun uudella otsikolla ja siirtää henkilöiden viestit siihen.
Intel on saanut Spctreen ja Meltdowniin liittyen (tähän mennessä) 32 (edit.) joukkokannetta.
Intel faces 32 lawsuits over Spectre and Meltdown
Joukkokanteitahan nuo 32 juuri ovat.
jep. korjasin jo
Sovitaanko että molemmat osapuolet ovat nyt esittäneet argumenttinsa ja yleisö saa äänestää voittajasta? 😀
Älkää nyt turhaan lähtekö rajoittamaan keskustelua. Niin kauan kun keskustelu sisältää enimmäkseen oleellista tietoa ja keskustelu/väittely ei ole mennyt pelkäksi henkilökohtaisuuksiin menemiseksi, niin tälläiset keskustelut minusta kuuluu olla ihan julkisesti esillä. Joko siirtää omaan ketjuunsa, tai antaa jatkua tässä. Kumminkaan tälle ketjulle ei varsinaisesti muutakaan hyötykäyttöä ole, kun itse alkuperäinen uutinen on jo käsitelty.
Ei pidä paikkansa. Tähän ketjuun on liitetty monia asiaan liittyviä iotechin uutisia (ja toivottavasti jatkojututkin yhdistetään tähän) ja itse ainakin seuraan tätä ketjua siitä syystä, että saan lisää tietoa Meltdown+Spectre ongelman etenemisestä. CPU-arkkitehtuurista sivukaupalla käytävä "facepalm"-riitely ei mielestäni ole ihan tänne kuuluvaa.. toiseen topikkiin?
Näistä jatkotutkimuksista ja merkittävistä löydöksistä olisi melkein parempi tehdä suosiolla uusia uutisia, jos ovat niin merkittäviä.
No niistähän on tehty ja tehdään, ne uutisten kommenttiosiot vain yhdistetään tähän ketjuun.
Ei niitä ehkä enää kannata tänne linkkailla. Tämä ketju toimi ihan hyvin kun tapaus oli tuore, niin saman asian keräykseen. Nyt tilanne on alkanut rauhoittumaan ja jos tulee niitä korjauksia kannattaa ne erottaa omaksi uutiseksi keskusteluineen.
Ei yhdistetä enää, meni jotain rikki ja rupesi näkymään tuplana viestejä etusivulla niin jatkossa uutiset tulee omiin ketjuihinsa tästäkin aiheesta. Löytyvät etusivulta toki tutuilla samoilla tahdilla ja koitetaan muistaa pistää tänne aina linkki kun tulee uutta
Hyvä threadi. Riitaoja ei ymmärrä peruskäsitteitä ohjelmoinnista tai edes millä granulateerilla prosessorit toimivat (bitti/tavu), ja siitä huolimatta on saanut pumpattua hkultalalta mielenkiintoista tietoa viihdyttävässä muodossa. 🙂
Eikös tämä asia tullut jo käsiteltyä? Ja lisäksi ei ole oikein hyvä tapa pistää nimimerkkiä ja "ei ymmärrä" kommenttia peräkkäin. Se tietäväisempi vänkääjä tähän myös syyllistyi.
Itse aiheeseen, niin sehän on vielä kesken, kun ei tiedetä miten nuo Intelin tulevat mikrokoodipäivitykset toimivat. Kauan kestää kuitenkin korjaus vaikka kesästä 2017 asti ollut tiedossa.
Mieti nyt vähän miten esimerkiksi cache toimii. Eli voimme lukea osan datasta nopeammin kuin koko muistista vaikka kuitenkin tarvitsemme sen koko muistin. Osoiteavaruuden voi optimoida aivan samalla tavalla, ei meidän tarvitse mapata koko osoiteavaruutta että saamme sataprosenttisen varmuuden missille ja 99.9+% todennäköisyyden osumalle.
Löysin tälläisen paperin jossa asiaa on yhdistetty itse datacachen tutkailuun:
https://pdfs.semanticscholar.org/20f5/3808fcf89391c0172674d97d9163c7a140ed.pdf
Tuosta nyt selvisi että idea/tutkimus on Lishing Liun vuodelta -94.
Ja jos cache on fyysisesti mapattu tarvitaan aina TLB-muunnos cachen tagin vertailuun, ja TLB:hen tuon käyttäminen soveltuu paljon paremmin kuin virtuaalimuistiin, TLB:n osoiteavaruus on aina ohjelmakoodin osalta lineaarinen, fyysinen muisti voi olla mapattu miten vain. Aikanaan tuota sovelluttu mahdollisesti Alpha EV45:ssa tms. TLB:ssä josta joku tekninen juttu jossain lehdessä josta asia jäänyt päähän. Ja tää oli vain teoriaa, monia muitakin vaihtoehtoja tietty on.
Ja ohjelmointi ei ole mun homma, eikä sen puoleen piirisuunnittelukaan, kai sitä saa silti jostain yrittää keskustella ilman että kaikki mitä itse ei ihan hiffaa tuomitaan vääräksi.
Joo ja pahoittelen että mun kirjallinen ulosanti on aika perseestä, mutta eipä tuo oma tyylisikään kaikkein vähiten provokatiivistä ole.
Ensinnäkin, tuo "99.9+%" lukusi on ihan hatusta vedetty eikä vastaa todellista.
Toisekseen, mikään "99.9% varmuus" ei ole riittävä, ei riitä että 999 muististalukua luetaan oikein jos se tuhannes luetaan väärin.
Tarvitaan 100% varmuus ennen kuin voidaan julistaa välimuistiosuma.
(tai sitten jos se 100% varma osumatieto tulee jotenkin myöhässä, vaaditaan siitä myöhäisestä missistä selviämiseen helposti jotain todella monimutkaista ja hidasta replay-härväystä tai liukuhihnan flushausta jonka haitat on ziljoona kertaa suurempia kuin se hyöty, mikä voidaan jossain kriittisessä polussa saada joidenkin bittien vertailemisesta jotenkin myöhemmin)
Tuossa otettiin HUTEJA pois aikaisin vertaamalla vain alimpia bittejä. Tuossa tehtiin edelleen ihan täysi vertailu ennen kuin voitiin julistaa OSUMA.
Oleellinen pointti tuossa on virransäästö, että kun ekassa vaiheessa luetaan vain ne 2 alinta bittiä, sillä saadaan melkein neljäsosa välimuistin "teistä" pelattua pois ennen täysilevää tag-accessia. Jos välimuistissa on 8 tietä, joissa yhdessä on se data, muissa 7ssä kussakin on 25% todennäköisyydellä samat alimmat tag-bitit, eli tarvii tehdä täysi luku vain keskimäärin 2.75 tielle. Ja jos 8-teisessä välimuistissa sitä dataa ei ole, tarvii tehdä täysi luku vain keskimäärin 2 tielle.
Järkevä keskustelu on sitä, että tiedostetaan se, mitä tiedetään ja ymmärretään, ja mitä ei tiedetä tai ymmärretä, eikä aleta väittää varmaksi omaa tulkintaa asioista, joita ei ymmärrä.
Jaahas herrat ovat lähellä asian ydintä.
Luulen että se osaavin taho ei huutele vaan tekee ja toimii (toivottavasti).
Jätänpä tämän tähän 13 Major Vulnerabilities Discovered in AMD Zen Architecture, Including Backdoors
Tähän voi myös jättää tämän
Virallinen: AMD vs Intel keskustelu- ja väittelyketju
Jätä vaan, oli vaan enemmän related suoraan tähän ketjuun, oli totta tai ei.
Kommentoidaan nyt tännekin sen verran että ilmeisesti kyse on firman markkinamanipulointiyeityksestä. Ja ko. Firma on ilmeisesti matkalla jostain vastaavasta jo oikeuteen Saksassa.
Ilmeisesti haavoittuvuudet sinänsä ovat "todellisia", että ne on olemassa JOS koneeseen asennetaan tarkoituksella haitallinen BIOS, firmis piirisarjalle jne. Sellaisenaan koneissa ei ole noita haavoittuvuuksia.
Lisäksi huomionarvoista on että "löydökset" julkistettiin alle 24h sen jälkeen kun niistä oli ilmoitettu AMDlle joka ei ehtinyt vastaamaan tai ottamaan kantaa väitteisiin ennen julkaisua
Mutta tutkitaan tietenkin vielä asiaa
Tutkinnoissa voisi lähteä liikkeelle vaikkapa siitä, että kuka tämän CTS-Labsin toimintaa rahoittaa. Ajoitus viittaa kyllä aika vahvasti yhteen suuntaan.
Alleged AMD Zen Security Flaws Megathread • r/Amd
Tuolla on hyviä linkkejä. "Bugit löytänyt" firma mm. ilmeisesti on feikannut pääkonttorinsa green screenin ja muutaman kuvapankkiotoksen avulla. Ellei muuta todisteta, niin kuulostaa suuren luokan kusetus / markkinamanipulaatioyritykseltä
EDIT: Ja ilmeisesti kaikki noista tarvitsevat admin oikeudet toimiakseen. Jos hyökkääjä saa admin oikeudet, niin peli on joka tapauksessa menetetty oli haavoittuvuuksia tai ei, joten koko homma kuulostaa todella liioitellulta
Tietoturvayhtiö kertoo löytäneensä 13 haavoittuvuutta AMD:n Zen-alustoista – io-tech.fi tuonne jatkot
Gigabyte GA-H270N-WIFI emoon on näköjään ilmestynyt uusi bios F8d (2018/03/09)
Reilu kuukausi sitten ilmestyi aikaisempi F8b, joka korjasi samaa. Itsellä ei ole ollut tuon vanhan kanssa mitään ongelmia. Kone pfSense palomuurina niin ongelmat olisi kyllä huomannut.
Täähän oli liittyen Meltdowniin, eli Meltdownin selittää hyvin se että TLB:t käsitellään jäljessä. Jo jäljessä käsittely antaa paljon aikaa optimoida homman virrankulutusta, ja voidaan esimerkiksi koota kaikki tietylle linjalle osuvat hitit yhdessä.
Intel on ollut hipihiljaa iät ja ajat L1-taggauksestaan, mutta AMD on dokumentoinut Zenin L1-taggauksen ja TLB-käsittelyn oikein hyvin. Eli Zenin L1 on täysin virtuaalisesti accessoitu osittaiseisen lineaarisen tagin mukaan. Väärintulkintamahdollisuudet ja muut konfliktit on hoidettu L2:ssa.
https://support.amd.com/TechDocs/55723_SOG_Fam_17h_Processors_3.00.pdf
Toki AMD puhuu itse way predictionista mutta dokumennoinin mukaan on ihan selvää että fyysistä tagia ei ikinä L1:ssä käsitellä. Eikä ole uusi tekniikka, samaa on käytetty jo 80-luvulla direct mapped kakkujen kanssakin.