
AMD valotti E3-messujen yhteydessä medialle järjestetyssä Tech Day -tapahtumassa hieman suunnitelmiaan uuden RDNA-arkkitehtuurin ja säteenseurannan suhteen. Kuten jo aiemmin jo Computex-messuilla paljastettiin, yhtiö kutsuu jatkossa uutta grafiikka-arkkitehtuuriaan RDNA-nimellä ja siihen pohjautuvia grafiikkapiirejä Navi-nimellä. Ensimmäisenä RDNA-arkkitehtuuri ja Navi-grafiikkapiiri ovat käytössä Radeon RX 5700 -sarjan näytönohjaimissa ja tarkemmalta nimeltään kyseessä on Navi 10. Toistaiseksi mahdollisesti isommista tai pienemmistä Navi-piireistä ei ole tietoa, mutta luvassa on joka tapauksessa nopealla aikataululla päivitys 7nm+ -valmistusprosessiin ja RDNA 2 -arkkitehtuuriin.
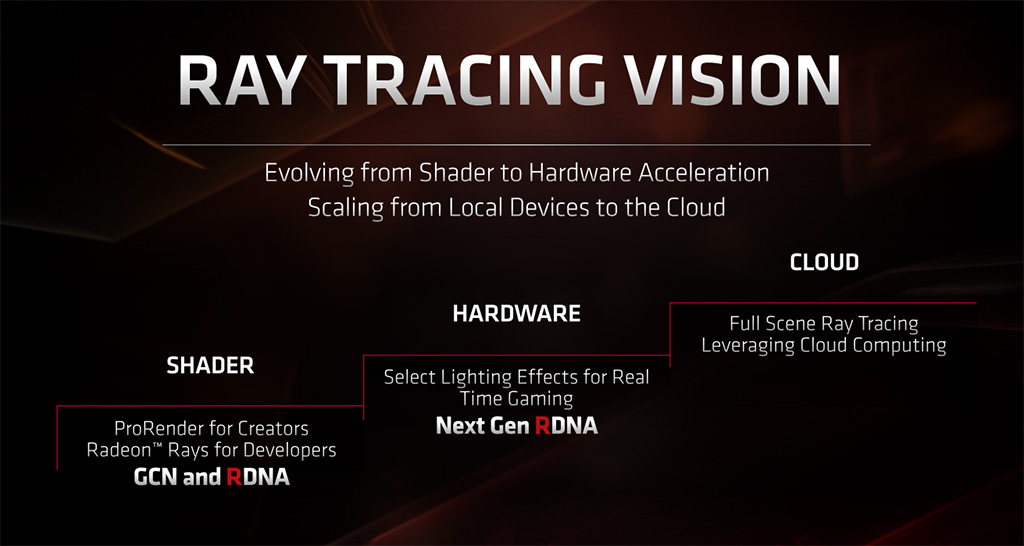
Todennäköisesti jo ensi vuonna julkaistava RDNA 2 -arkkitehtuuri tuo mukanaan muun muassa rautapohjaisen kiihdytyksen säteenseurannalle ja valikoiduille valaistusefekteille. Laajempaa säteenseurannan kiihdytystä AMD suunnittelee toteutettavaksi pilvipohjaisesti. Microsoft ja Sony ovat molemmat ilmoittaneet tuovansa seuraavan sukupolven pelikonsolinsa markkinoille ensi vuonna kustoimoidulla Navi-grafiikkapiirillä, joka tukee säteenseurantaa. Käytännössä tämä tarkoittaa sitä, että Navi-grafiikkapiirejä tullaan näkemään myös RDNA 2 -arkkitehtuuriin pohjautuen. Tähän asti AMD:n roadmapeissa Navin jälkeiseen 7 nm+ -päivitykseen on viitattu Next-gen-nimellä.
Edellinen Graphics Core Next -arkkitehtuuri soveltuu edelleen hyvin suorituskykyiseen laskentaan, joten AMD tulee jatkamaan todennäköisesti sen ja HBM-muistien käyttöä Radeon Instinct -kiihdyttimissään. Jatkossa pelinäytönohjaimet tulevat perustumaan RDNA-arkkitehtuuriin.
Valikon rakentaminen client sidelle ei olisi todellakaan mikään iso homma. Käytännössä Stadiaa varten pitää engineä muutenkin customoida, joten yhden valikon irroittaminen ei olisi mikään iso homma. Mahdollistaisi myös valikon customoinnit käyttäjän toimesta. Noh katsotaan mitä sieltä tulee.
Säteenjäljityksessä on käytännössä kolme sellaista vaihetta, joita voi kiihdyttää raudalla, ja joita perinteinen rasterointi-GPU ei osaa kiihdyttää:
1) BVH-puun rakentaminen. (tarvii tehdä liikkuvien objektien osalta joka frame uusiksi).
2) BVH-puun läpikäynti, törmäystarkastus sen laatikoihin
3) Kolmioiden törmäystarkastus.
Näiden lisäksi on säteenjäljityksessäkin hyödyllinen/käytetty asia, jonka perinteinen rasterointi-GPU osaa jo kiihdyttää raudalla:
4) Tekstuurimäppäys
nVidian nykyrauta osaa näistä asiat 2+3+4. Ja näistä 2 ja 3 ovat hyvin samanlaisia, on melko helppo tehdä rauta joka pystyy molempiin. Ja kaverini teki väikkärinsä vaiheesta 1 ja meni sen jälkeen vajaa vuosi sitten nVidialle töihin, eli nVidialta varmaan tulossa joskus viimeistään 2021, ehkä jo aiemmin.
PowerVRn nykyrauta osaa näistä kaikki.
Oletettavasti ensi vuonna tulevaan RDNA2een tulee vähintään BVH-puun läpikäynti ja kolmioiden törmäystarkastus, ehkä myös BVH-puun rakentaminen. Ja tekstuurimäppäys siinä siis on varmasti, koska rasterointi.
BVH-puu tyypillisesti jaetaan kahteen osaan. Yksi puunhaara staattisille (paikallaanpysyville) kappaleille, ja toinen haara dynaamisille(liikkuvilla kappaleille). Staattinen BVH-puuhaara generoidaan etukäteen (viimeistään pelikentän latautuessa tai ekaa framea rendatessa), dynaaminen BVH-puuhaara generoidaan uudestaan joka framelle. Ja kun tämä tehdään softalla, se vaatii paljon tehoa, ja rajoittaa liikuvien kappaleiden määrää.
Käytännössä nvidian nyky-RTXn rajoite on siis suorituskyky suurella määrällä liikkuvia kappaleita. Soveltuu huonosti esim. peleille, joissa kaikki on hajoavaa, tai jossa puiden oksat voivat heilua tuulessa tms.
Soveltuu hyvin pelille, jossa itse kenttä on hyvin staattinen, ja siellä on pieni määrä liikuvia vihollisia.
Noita tilanteita, joissa näkymä vaihtuu nopeasti on käytännössä paljon, esim jonkun nurkan taakse kurkkaaminen, nopea pyörähtämien paikoillaan, paikassa, jossa näkyy yhtään edemmäs ym..
whops – missclick
Kiitos tästä!
Olet useampaa kertaan sanonut, että pilveä ja paikallista ei voi sotkea…
Eli ei siis ole fiksu laske sitä puu osaa pilvessä ja ehkä seuraavaa ja rendata loput gpu:lla? Ilmeisesti tuossakin viiveet olisi se ongelma. Siirrettävää dataahan ei kaiketi olisi samoja määriä kuin rendatun kuvan siirrossa, jota itsekkään pidä järkevänä.
Mutta puhtaana amatöörinä kuvittelisin että datan määrä ei olisi hillitön kahden ensimmäisen vaiheen osalta.
Jos vielä aukaisut tuota niin oppisi wanha taas jotain uutta grafiikan piirron saralta!
Rasteroinnissa piirrettään kolmioita. Otetaan kolmio, piirretään se, otetaan toinen kolmio, piirretään se, jne.
Säteenjäljityksessä ei piirretä kolmioita lähtien kolmioista, vaan siinä tarkastetaan sitä, mihin säteet osuu.
Lauotaan yksi säde, tarkastetaan kaikista kolmioista, että mihin se osuu, mahdollisesti lauotaan osumakohdasta uusi sekundäärisäde. Sitten lauotaan toinen säde jne.
Jotta voidaan tehdä tarkastus kaikista kolmoista, pitää säteenjäljitystä tekevällä laitteella olla omassa nopeassa muistissaan kaikki kolmiot.
Ei voida jakaa eri laittiden välillä, että "hoida sinä nämä kolmiot, minä hoidan nämä kolmiot"
Ja BVH-puu on tietorakenne, jolla voidaan optimoida sitä osumatarkastusta niihin kolmioihin. Kolmioita sortataan ja luokitellaan siten, että voidaan sen perusteella hylätä suuri osa kolmioista. Ennalta ei kuitenkaan voida tietää, mitkä kolmioit hylätään, koko BVH-puu ja kolmiodata pitää olla melko nopeassa muistissa (DRAM)
BVH-puu koostuu laatioista, yksinkertaisessa tapauksessa uloimman tason laatikko on niin iso, että sinne mahtuu sisään scenen kaikki kolmiot.
Yksinkertaisessa radix-2-BVH-puussa tämän sisällä on sitten kaksi laatikkoa, molemmat sisältävät puolet kolmioista. Avaruudellisesti nämä laatikot kuitenkin overläppäävät tosiaan selvästi.
Ja seuraavalla tasolla taas molemmat näistä laatikoista sisältävät 2 laatikkoa, joissa molemmissa puolet näiden laatikoiden kolmoista.
Lopulta matalimmalla tasolla meillä on laatikoita, joissa on vain 1 tai 2 kolmiota. Sitten niistä tehdään se kolmioiden osumatarkastus.
Jos säde ei osu BVH-puun laatikkoon, se ei voi osua mihinkään laatikossa olevaan kolmioon.
Eli, kun laatikko käsitellään, tarkastetaan sen molemmat lapsilaatikot, että osuuko säe niihin. Ja jos säde osuu lapsilaatikkoon, laitetaan lapsilaatikko jonoon odottamaan käsittelyä. Jos säde ei osu lapsilaatikkoon, se ei voi osua mihinkään siellä olevaan kolmioon ja tarkastettavien kolmioiden määrä putoaa n. puoleen. Ja jos se seuraavalla tasollakaan ei osu toiseen laatikkoon, se putoaa neljäsosaan alkuperäisestä jne.
Toki välillä käy niin, että osutaan molempiin laatikon alilaatikoihin, sitten pitää tarkastaa molemmat.
Yhden (tai kahden) laatikon tai kolmion törmäystarkastus kestää raudalla luokkaa joitain kellojaksoja, (riippuen raudasta), softalla suuruusluokkaa sata kellojaksoa, eli joitain kymmeniä nanosekunteja, karkeasti ottaen samaa suuruusluokkaa kuin DRAM-muistin hakuaika. Ja puun läpikäynti on melko sarjallinen operaatio, lapsilaatikon osoite selviää vasta kun ylemmän tason laatikko on luettu, ja se, tarviiko sitä käsitellä, selviää vasta, kun ylemmän tason laatikko on kokonaan käsitelty. Yhden säteen sisällä rinnakkaisuutta on melko huonosti, lähinnä siellä on rinnakkaisuutta vain
1) kolmen levyisiä geometriavektoreita
2) laatikon molempien lapsilaatikoiden törmäystarkastus voidaan tehdä yhtä aikaa.
Yhden primäärisäteen renderöimiseksi voidaan joutua tekemään karkeasti n. 18 törmäystarkastusta, kokonaisuudessaan aika on siis softalla luokkaa parituhatta kellojaksoa(vajaa mikrosekunti), raudalla selvästi vähemmän.
Jokaista primäärisädettä kohden sitten tosin lauotaan tyypillisesti n. 3-4 sekundäärisädettä, eli puhutaan kokonaisuudessaan luokkaa parista mikrosekunnista, joka menee esim. yhdeltä ytimeltä yhden pikselin rendaamiseen.
Tämä on niin sarjallinen ja nopea operaatio, että tämän sisällä ei ole mitään järkeä yrittää rinnakkaistaa mitään erimerkiksi monilla säikeillä. Koko säde jäljitetään loppuun asti yhdessä säikeessä.
Sen sijaan eri säteitä voidaan laukoa loputtomasti rinnakkain eri säikeissä, myös eri säteiden laskeminen saman ytimen eri SIMD-linjoissa voi kehittyneellä SIMD-käskykannalla olla mahdollista, joskin ei triviaalia. Tällöin kolmiodata ja BVH-puu on kaikille säikeille/säteille yhteistä read-only-dataa.
ELi ruutu voidaan jakaa vaikka tuhansiin tiiliin, joista jokaista tiiltä rendaa eri prosessori, jotka voivat kyllä olla eri tietokoneissa. Kaikkein pitää kuitenkin päästä nopeasti käsiksi siihen BVH-puuhun ja kolmiodataan, eli jos niillä ei ole jaettua muistia, ne pitäisi duplikoida kaikille, ja kun scene muuttuu (eli kun mikä tahansa liikkuu, käytännössä siis joka frame), geometriadata ja päivitetty BVH-puu pitää uudelleen siirtää kaikille muille.
Käytännössä kolmiodata on luonnostaan paikassa, missä itse pelienginekin pyörii. Sen lähettäminen minnekään tahansa muualle kuluttaa aika paljon kaistaa. Jokaista kolmiota kohden 1-3 verteksiä(16-48 tavua) ja esim. joku viite tekstuuriin, sen kordinaatit, sekä pari lukua pinnan ominaisuuksista, niin ollaan helposti 32-64 tavussa per kolmio. Ja BVH-puussa laatikoita on suurinpiirtein sama määrä kuin kolmioita on, siitä luokkaa 32 tavua lisää. Ollaan helposti 64-96 tavussa per kolmio, ja meillä voi kolmioita olla esim. 250000 kpl.
Geometriadatan muistintarve helposti kymmeniä megatavuja. Tätä kun alkaa lähettämään 60 FPSää verkon yli, kaista menee yli gigatavu sekunnissa. Tai siten joka laite generoi uudestaan saman BVH-puun ja ollaan silti sadoissa megatavuissa sekunnisa. Vaikka 90% scenestä olisi staattista, ja lähetettäisiin vain muutokset(ja BVH-puun ylimpänä haarana olisi jako staattisiin ja dynaamisiin) , ollaan silti kymmenissä megatavuissa sekunnissa.
Onnistuu nopeassa lähiverkossa laskentaclusterissa, ei internetin yli.
Käytännössä, jos yritettäisiin hajauttaa ison verkon yli, pitäisi alkaa duplikoida aika paljon koko pelienginestä, että kaikki eri rendaajat osaisivat laskea kaikkien pelin kolmioiden paikat. Ja tässä tehdään entistä enemmän samaa homma monessa paikassa, ja tulee entistä pajhempia synkronointiongelmia.
Järkevä/mahdollinen malli on, että samalla palvelinclusterilla pilvessä pyörii sekä pelin verkkopeliserver(jonka takia siellä on se pelienginen data) että säteenjäljitysrendausfarmi, mutta sitten ei enää kannata lähettää sinne pelaajan kotikoneelle/päätelaitteelle mitään rendattavaksi, vaan lähettää asiakkaalle vain valmis kuva.
Tuosta selvisi matematiikkaa, joten jep… Selvitti itselle paljon tuota ongelmavyyhteä. Osa tietoteknisestä puolesta meni ohi kun ei ole sen alan terminologia aivoihin iskostettuna mutta matemaattisesta puolesta pääsi kärryille.
Kuvittelin että jotain laskentaa olisi voinut ulkoistaa, mutta koska riippuvan noin paljon toisistaan niin odotteluksi menisi.
Kiitos uudestaan! Mukava lukea näitä taustatietoja. Näihin ei juuri törmää noissa englanninkielisillä sivostoissa. Paria poikkeusta lukuunottamatta.
Suomen Keskustelupalstat ovan usein informatiivisempi kuin valtamedian syventävät artikkelit!
Stadian kanssa Chromecast on minimi-investointi. Joka jonnella ei ole sitä läppäriä ja jos on, niin sillä läppärilläkin on hintansa, joka on todennäköisesti enemmän kuin tuo Chromecast. Sen läppärin pitää sitten myös pystyä tuuppaamaan 4K-kuvaa ulos ja purkaa korkeabittivirtaista HEVC tai VP9, joka ei onnistu kovin vanhalla raudalla.
Sivujuttuna kävin eilen kirjastossa ja sielläpä oli jäätävä valikoima Xbox360/One- ja PS3/PS4-pelejä lainattavana. Jos olisi konsoli, niin varmaan kävisin pelit lainaamassa tuolta kun ei maksa mitään. Muutaman pelin kun pelaa, niin siinä on koko konsolin hinta jo maksettu pois vs. striimauspalvelut.
Kyllä se nyt aika iso homma on. On ihan eri asia paketoida peli striimattavaan muotoon ulkoapäin kuin lähteä ronkkimaan sen sisäistä toimintalogiikkaa tai alkaa purkaa sen sisälmyksiä ulos. Juuri sen vähäisen muutostarpeen takia noita pelejä on Stadialla nyt niin monta listallaan. Veikkaan että Googlella on joku melko kevyt itse tehty ohjainrajapinta, joka välittää verkon takana olevan käyttäjän komennot paikalliselle virtuaaliohjaimelle tms. Itse peli ei tajua tuon taivaallista siitä pyöriikö se lokaalisti käyttäjän koneella vai ei. Tuo sanomani asepopup oli vain esimerkki. Peleistä löytyy nyt tuhat muutakin kohtaa, jotka ovat hyvin hankalia videostriimaukselle. Ei Googlella ole mitään mahkuja lähteä kaivamaan pelien sisältä jotain inventaariota, karttaa tms ja tuuppaa niitä jotenkin erillisessä javascript/html5-putkessa käyttäjälle. Toisekseen samat latenssiongelmat ne vaanivat ihan sama mitä tekniikka käytetään. Se asepopu päivittynee myös sen mukaan paljonko on panoksia/energiaa/perunoita, minimappi päivittyy jatkuvasti vihollisen ja omien liikkeiden mukaan. Ei vain toimi. Joku save-load-tapainen voisi olla toteutettavissa monellakin tapaa, mutta sillä ei taas voitettaisi oikein yhtään mitään latenssien tai muutenkaan käyttäjäkokemuksen parantumisena.
No ei tietenkään ole, amd on omien sanojensa mukaan sitoutunut tukemaan raytracing -teknologiaa mutta nähtävästi siellä ei panosteta tähän asiaan. Yritys lupaili viime vuonna kehittää omia ratkaisuja säteenseurannalle mutta aikataulu oli avoin. PC pelaaminen + amd:n 'suunnittelema' pilvipohjainen raytracing kiihdytys kuulostaa mielenkiintoiselta, joskin hieman erikoiselta ratkaisulta. Siellä tietenkin toivotaan että joku muu taho pystyy ratkaisemaan heidän tarvitseman pilvipalvelun kymmenien – satojen millisekuntien viiveet jolloin amd selviäisi tästäkin pienellä budjetilla tai pelkällä kiitoksella.
Onneksi isoin peluri on tukenut microsoftin kehittämää directx raytracing -teknologiaa raudalla jo 9kk ja tämän vuoden puolella pascal korteilla ajuritasolla, ilman tämän(kin) nvidian panostusta tekniikan käyttöönotto jäisi 100varmasti demo asteelle.
No kyllä tulee taas sellaista värilasi
soopaa, että huhhuh.
Ei se ole ihan yksi tai kaksi teknologiaa mitä joku valmistaja on tuonut markkinoille toista aiemmin. Esimerkiksi tesselaation kiihdytys tuli AMDltä kolmisen vuotta ennen NVIDIAa.
AMD kehittää koko ajan omia RT-ratkaisujaan ja niitä on myös olemassa ja tuettuna tällä hetkellä kun, ne ei vaan ole suunniteltu reaaliaikaiseen pelikäyttöön (reaaliaikaisuus onnistuu kuitenkin)
Se pilvipohjainen kohta erikseen alleviivaa että kyse on täysin säteenseurannalla toteutetuista skeneistä, tuohon tapaan mitä DXR:ää käytetään ajetaan ihan paikallisesti RDNA2-näyttiksistä lähtien